02 方法
PhyCo 采用两阶段训练范式:(1)基于 ControlNet 的物理监督微调(Physics-Supervised Fine-Tuning),通过像素对齐的物理属性图条件化预训练扩散模型;(2)基于视觉语言模型(VLM)的奖励优化,进一步提升物理属性的可控性与准确度。
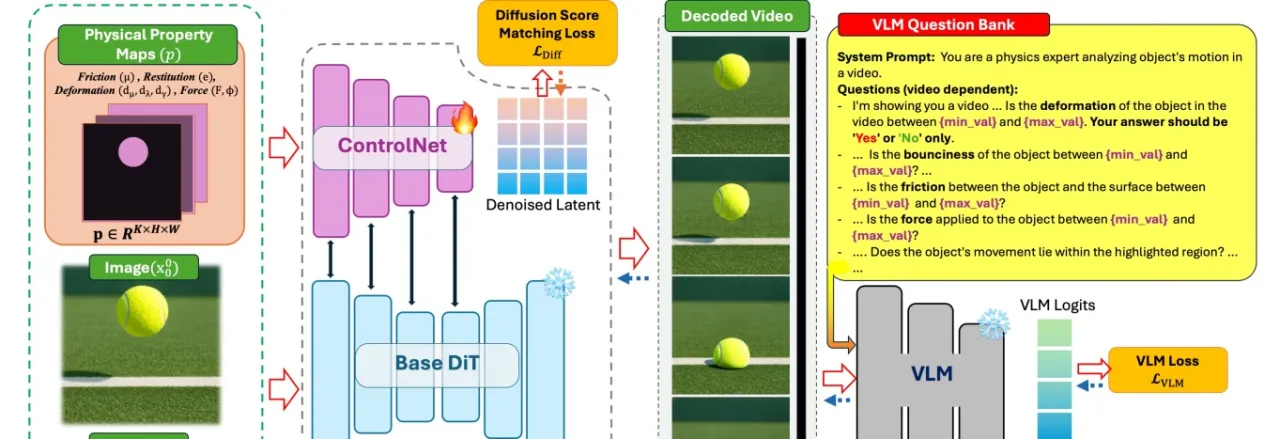 图2:PhyCo 两阶段训练流程。第一阶段:基于 Kubric + PyBullet + Blender 构建物理仿真数据集,通过 ControlNet 架构将物理属性图作为条件输入,对冻结的 Cosmos-Predict2 基础模型进行微调。第二阶段:对 Qwen2.5-VL-3B 进行物理问答微调(VLM fine-tuning),再将其作为奖励模型通过端到端反向传播优化 ControlNet 分支的参数,提高属性控制精度。
图2:PhyCo 两阶段训练流程。第一阶段:基于 Kubric + PyBullet + Blender 构建物理仿真数据集,通过 ControlNet 架构将物理属性图作为条件输入,对冻结的 Cosmos-Predict2 基础模型进行微调。第二阶段:对 Qwen2.5-VL-3B 进行物理问答微调(VLM fine-tuning),再将其作为奖励模型通过端到端反向传播优化 ControlNet 分支的参数,提高属性控制精度。
阶段一:物理监督的 ControlNet 微调
数据集基于 Kubric 框架,使用 PyBullet 物理引擎与 Blender 渲染器构建,包含六类控制场景:砖块在平面滑动(摩擦)、球弹离墙壁(弹性)、球垂直弹跳、软球自由下落、物体撞击可形变体,以及台球多球碰撞。每类场景对物理属性、物体颜色、表面材质、相机位姿和 50 种 HDRI 光照环境进行系统性随机化,最终生成超过 100K 条视频。
物理属性被编码为像素空间内的圆形 blob 表示,归一化至 [-1, 1]。属性分为三组:
- 接触属性:摩擦系数(μf)和弹性系数(e)
- 形变属性:Neo-Hookean 参数(dμ、dλ、dγ)
- 外力属性:力的大小(F)及方向(cos φ、sin φ)
每组属性对应一个独立的 ControlNet 分支,仅更新 ControlNet 层权重,基础扩散模型保持冻结。训练序列为 57 帧 @ 24 FPS,使用标准扩散 score-matching 目标函数。
 图3:PhyCo 仿真数据集示例。六类场景分别对应不同的物理动力学模式,系统性覆盖摩擦、弹性、形变和外力等属性的多样化取值范围,确保训练数据的物理多样性与视觉可观测性。
图3:PhyCo 仿真数据集示例。六类场景分别对应不同的物理动力学模式,系统性覆盖摩擦、弹性、形变和外力等属性的多样化取值范围,确保训练数据的物理多样性与视觉可观测性。
阶段二:VLM 奖励优化
单步重建优化因其全局轨迹编码特性,往往产生模糊的细节表现,不足以精确学习物理属性控制。PhyCo 引入 NN 步去噪 rollout,生成与推理阶段一致的预测潜变量,再通过 VLM 奖励对其进行反馈优化。
VLM 奖励模型基于 Qwen2.5-VL-3B,在 PhyCo 数据集上进行物理问答(physics-related queries)微调(LoRA rank=64,200 步,4×H100),在 100 次迭代内达到约 85% 的预测准确率。奖励函数采用正确/错误答案 logit 差的 binary cross-entropy:
ℒVLM = −∑i log σ(ζ₊(i) − ζ₋(i))
VLM 奖励优化阶段使用 8×H200 GPU 训练 100 次迭代(约 70 分钟),峰值显存 115 GB VRAM,通过端到端反向传播更新 DiT backbone 和 ControlNet 分支。
 图4:PhyCo 真实场景生成结果。在真实图像输入条件下,PhyCo 能够根据指定的物理属性生成符合物理规律的动态视频。不同行对应不同的属性控制条件,可观察到运动轨迹、碰撞弹性与形变行为均与输入属性高度一致。
图4:PhyCo 真实场景生成结果。在真实图像输入条件下,PhyCo 能够根据指定的物理属性生成符合物理规律的动态视频。不同行对应不同的属性控制条件,可观察到运动轨迹、碰撞弹性与形变行为均与输入属性高度一致。

