机器人操作任务需要对多样化的物体、空间位置和语言指令进行泛化——而现有方法要么依赖目标物体的显式检测与位姿估计,要么只能处理 2D 图像输入,难以有效利用 3D 空间结构先验。如何用单一模型、在极少演示下学会多种 6-DoF 操作任务?
"Rather than explicitly detecting or tracking objects, we want to learn perceptual representations of actions conditioned on language goals."
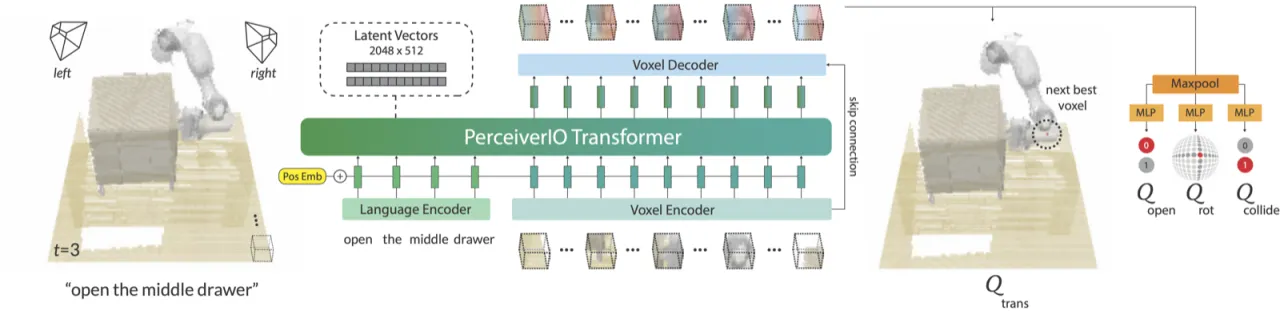
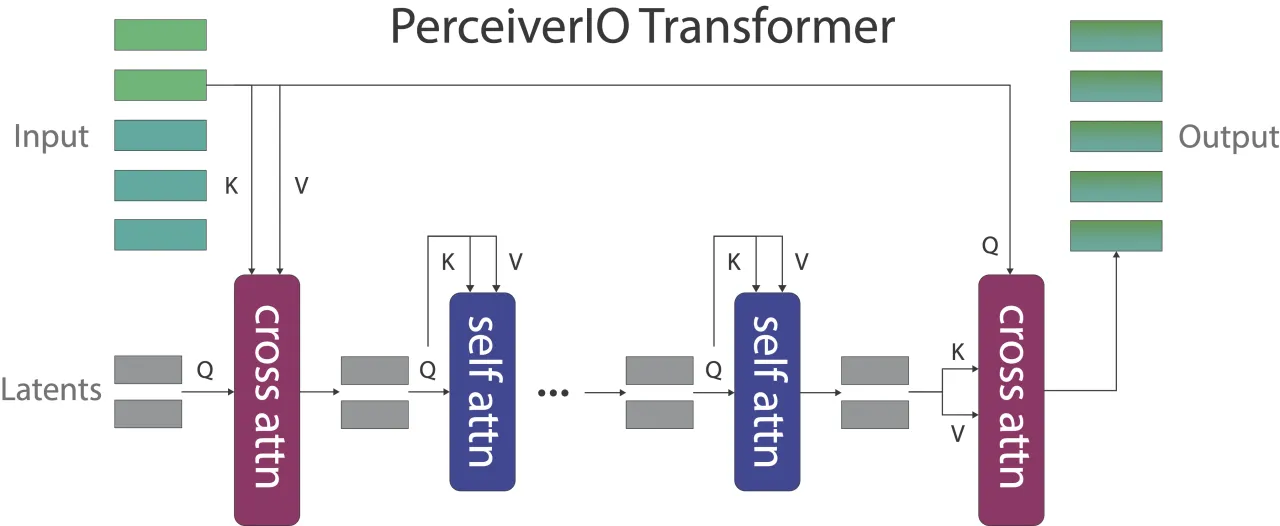
图 1:PerAct 在 RLBench 18 个操作任务(249 种变体)上的展示,涵盖抓取、推拉、开关门抽屉、堆叠、倒液体等多种交互类型。图中展示了语言指令(如 "open the middle drawer"、"put the green block in the green bowl")与对应的操作场景。
18RLBench 仿真任务
249任务变体数量
34×vs Image-BC 基线提升
2.8×vs C2FARM-BC 提升
核心问题
传统机器人操作方法存在以下主要挑战:
图像平面局限性:Image-BC(CNN/ViT)等方法将 RGB 图像直接映射到动作,缺乏 3D 空间推理能力,在精细 6-DoF 操作任务上表现差。
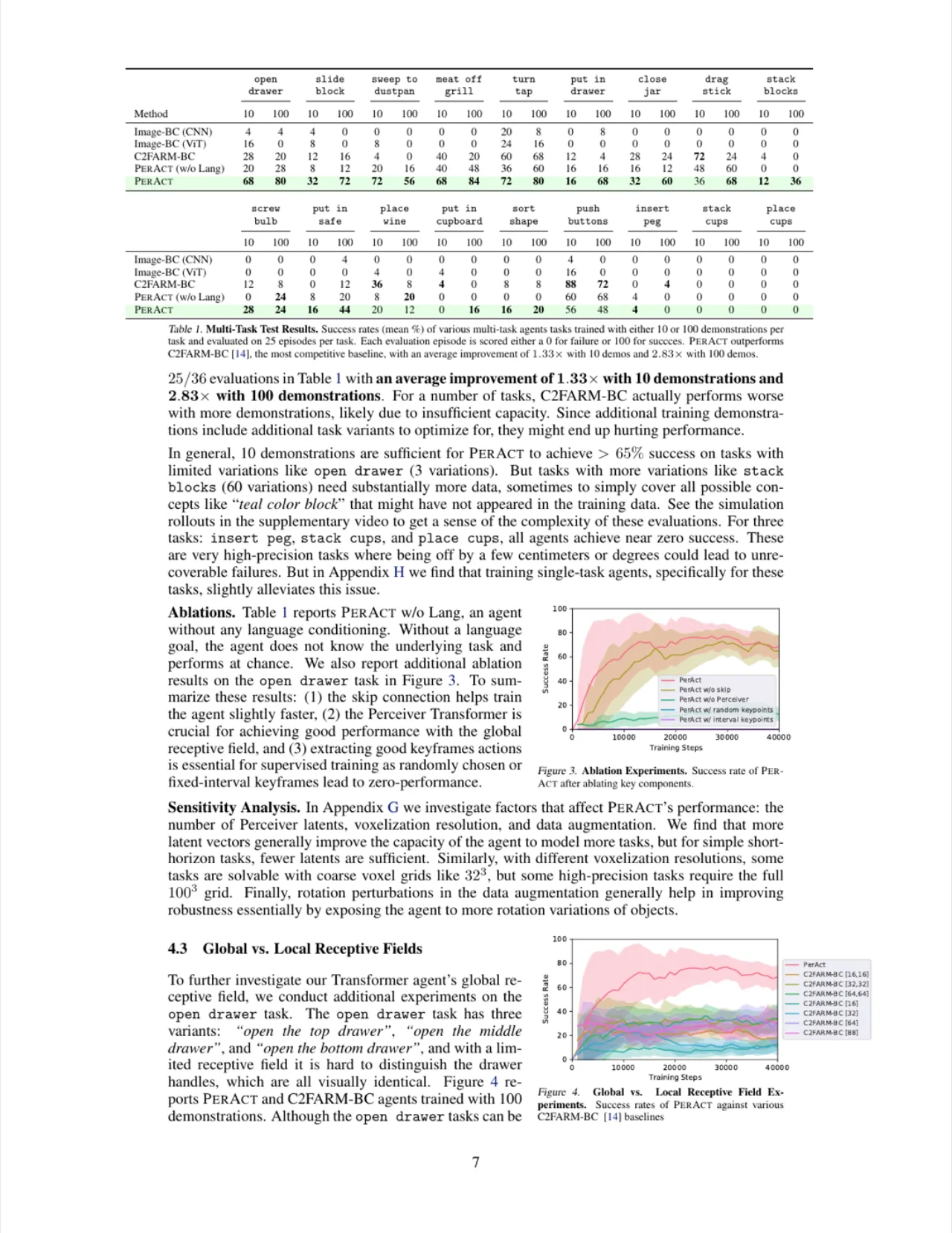
PerAct 在 10 个 demonstrations 时平均成功率约 29%,100 个 demonstrations 提升至约 49%,使用更多 demonstrations 时还有进一步提升空间("likely due to insufficient capacity",论文原文)。
对于 stack blocks(3 种变体)、insert peg、place cups 等高精度任务,PerAct 超越所有基线但成功率仍低于 65%,说明这些任务对末端执行器精度要求极高("a few centimeters or degrees could lead to unrecoverable failures")。
PerAct 展现出对语言描述的语义理解:可以泛化到训练中未见过的语言指令变体(如颜色词、位置描述),即 emergent language grounding。
PerAct 使用 keyframe-based behavior cloning,仅在关键帧处预测动作,默认采用线性插值运动规划器(motion planner)连接关键帧。论文明确指出:"our observations and actions are colorless and motionless",不建模非关键帧的连续轨迹,对高度动态或时序依赖的操作任务(如抓取移动物体)不适用。
论文实验显示 PerAct 在增加演示(从 10 到 100)时持续涨点,但同时指出额外训练 demonstrations 带来的提升"likely due to insufficient capacity",说明当前模型容量可能仍是瓶颈,在演示数量更大时需要更大的模型或更高效的训练策略。
依赖结构化场景与标定相机(inferred)
方法依赖多台标定好的 RGB-D 相机重建 3D 体素场景,对相机标定精度和场景光照条件敏感。在无结构化环境(如非实验室场景)或单相机设置下,3D 重建质量下降会直接影响体素空间中的动作预测精度。
高精度任务成功率仍有差距(stated)
对于 insert peg、place cups、stack blocks 等高精度任务,PerAct 成功率仍显著低于 65%,论文明确指出"a few centimeters or degrees could lead to unrecoverable failures",这类任务对当前 ~1cm 体素分辨率和 5° 旋转精度仍构成挑战。