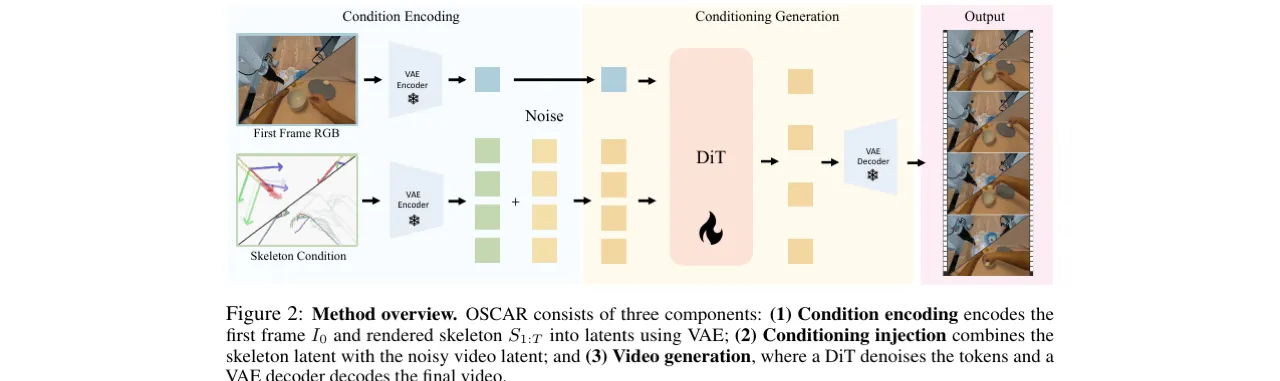
01 动机
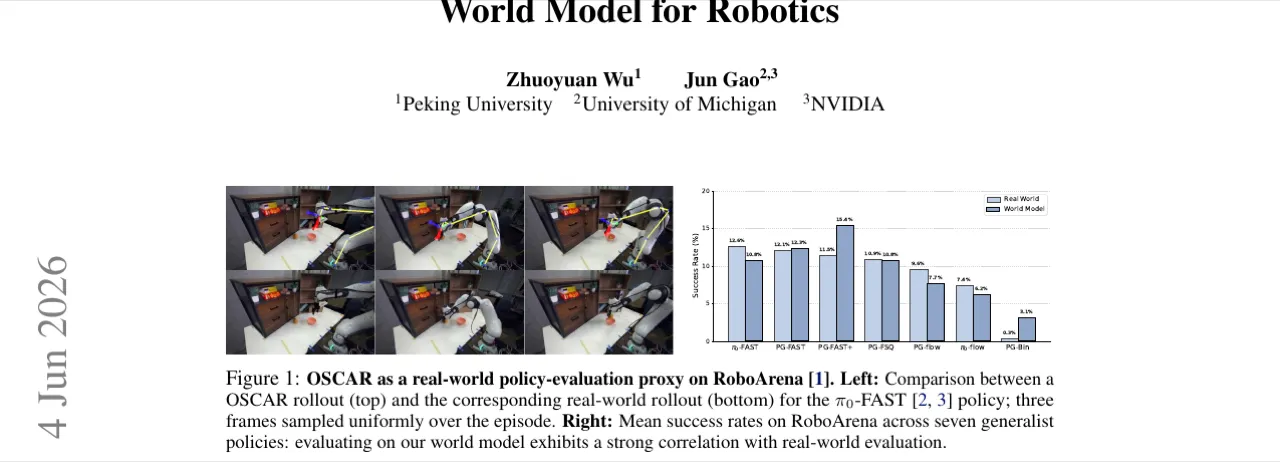
现有视频世界模型在机器人策略真实评估中面临三大核心挑战:训练数据场景多样性不足、动作跟随不精准、以及跨机器人形态泛化能力差。
"Existing video world models face three main challenges for real-world robot evaluation: limited scenario diversity in current robot training datasets, imprecise action following, and poor generalization across embodiments for broad adoption."
2B模型参数量(vs. 基线最大 14B)
180K清洗后训练 episode 数量
4覆盖机器人形态数(+ 人手)
2.165M原始数据源 episode 总量
三大挑战与对应设计
挑战 I:动作跟随不精准
视频需要在帧级别(何时发生)和像素级别(何处发生)精确跟随动作序列,才能为策略评估提供有意义的信号。Latent-action 方法将动作压缩为隐变量,往往无法精确传达空间运动。
挑战 II:场景泛化不足
策略评估需要覆盖不同任务、环境和动作序列。现有数据集(如 AgiBot)虽有百万条 clip,却集中在同一场景和任务,视觉多样性极低。
挑战 III:跨形态泛化能力差
世界模型应能泛化到不同机器人形态(Franka Panda、KUKA iiwa、AgiBot G1 等),而非绑定单一机器人,才能支持广泛的策略评估应用。
OSCAR 的两大设计支柱
(1)大规模标准化数据流水线:跨 4 种机器人和 2 种人手数据源,经过去冗余、质量过滤,构建覆盖广泛的联合训练数据集。(2)2D 骨骼渲染统一条件:仅依赖运动链,无需机器人外观信息,可跨机器人乃至人手泛化。