01 动机
当前最强的视觉-语言-动作(VLA)模型(如 RT-2-X)均为闭源,架构、训练数据、部署方法均不公开;而开源社区的替代方案又缺乏在消费级硬件上高效适配新机器人和任务的实用手段。OpenVLA 旨在填补这一空白。
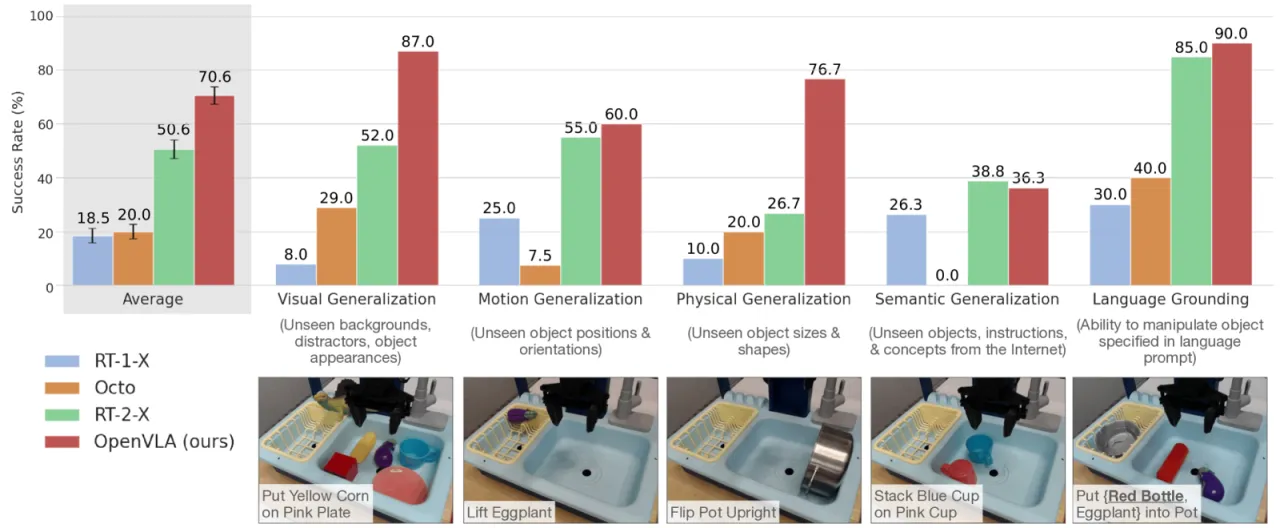
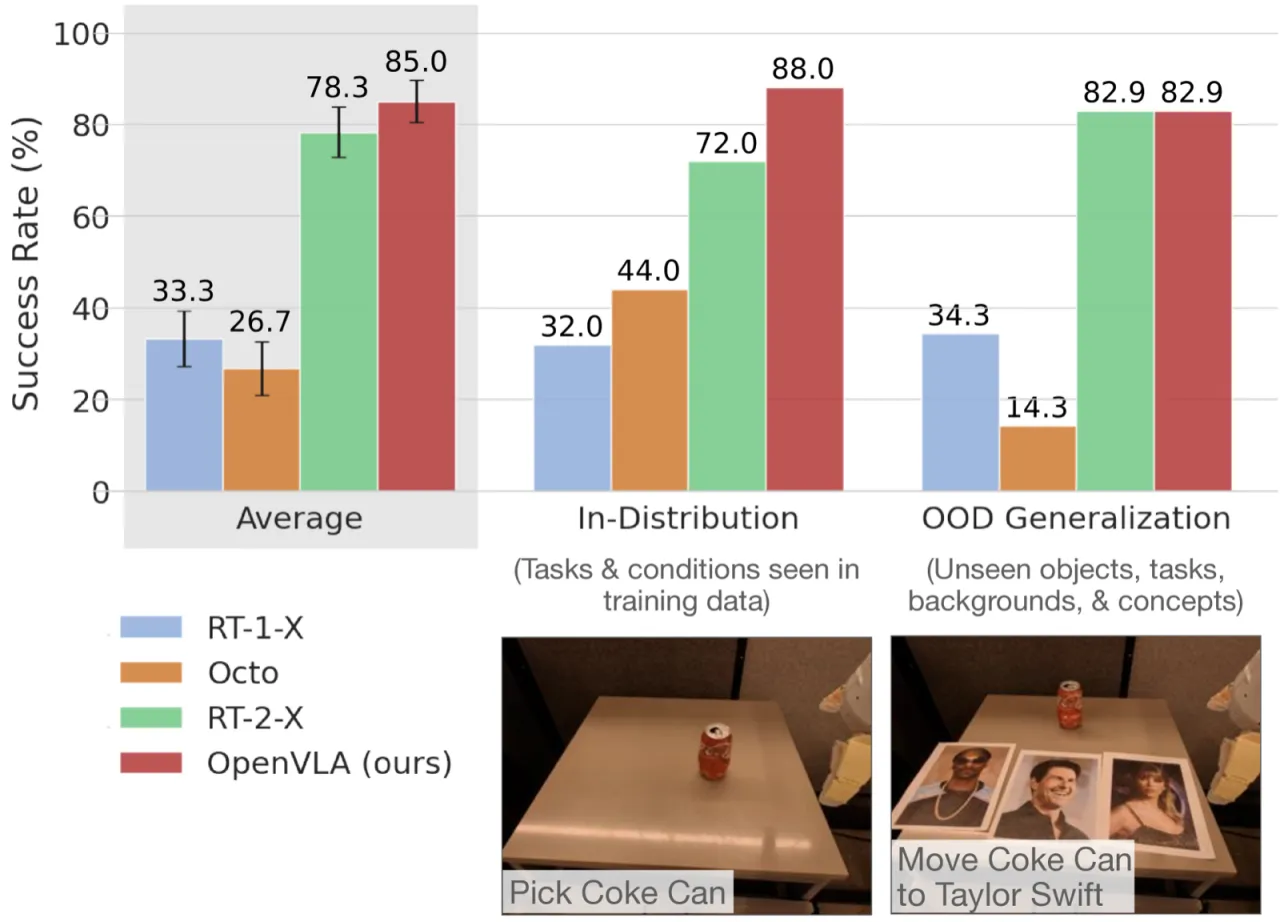
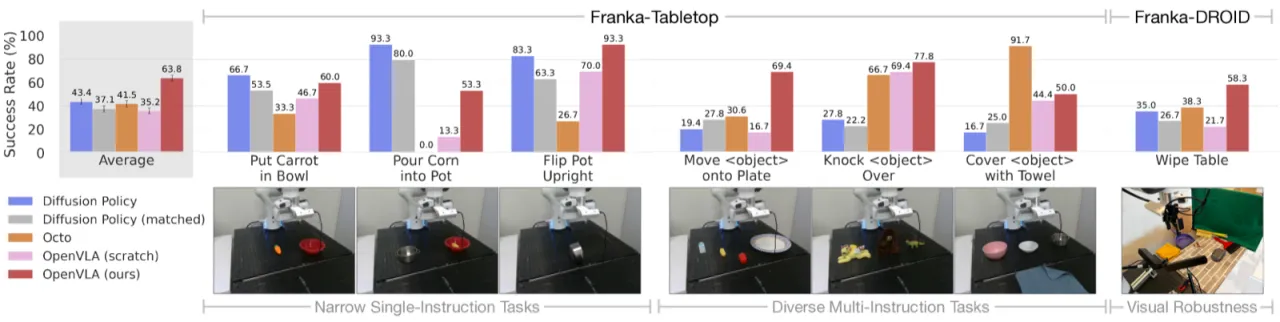
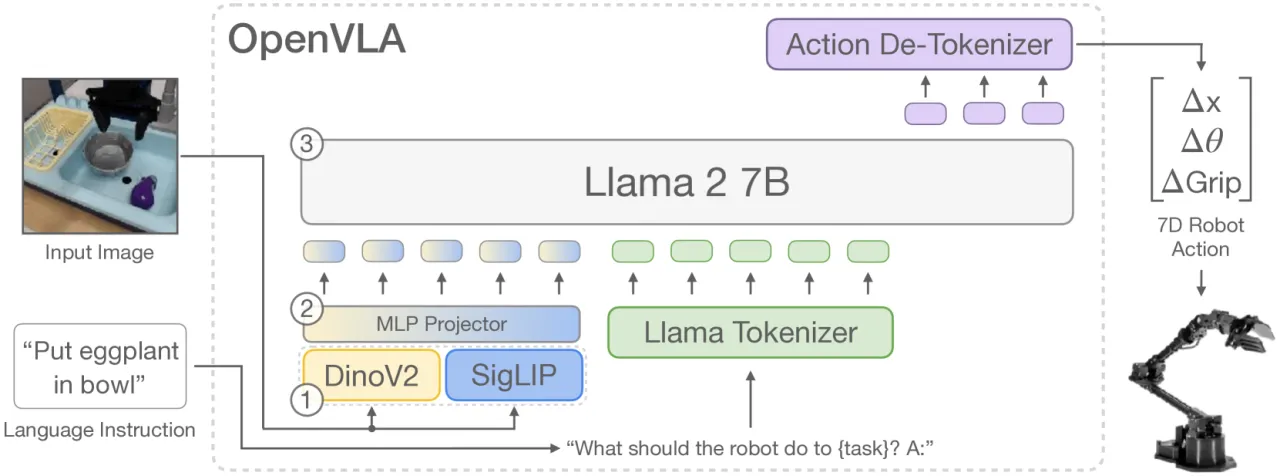
"We present OpenVLA, a 7B-parameter open-source VLA trained on 970k real-world robot demonstrations from the Open X-Embodiment dataset, and show that it outperforms RT-2-X (55B parameters) by 16.5% on manipulation tasks while requiring 7× fewer parameters."
970kOpen X-Embodiment 真实演示轨迹
+16.5%超越 RT-2-X(BridgeData V2 成功率)
7B参数量(RT-2-X 参数的 1/7)
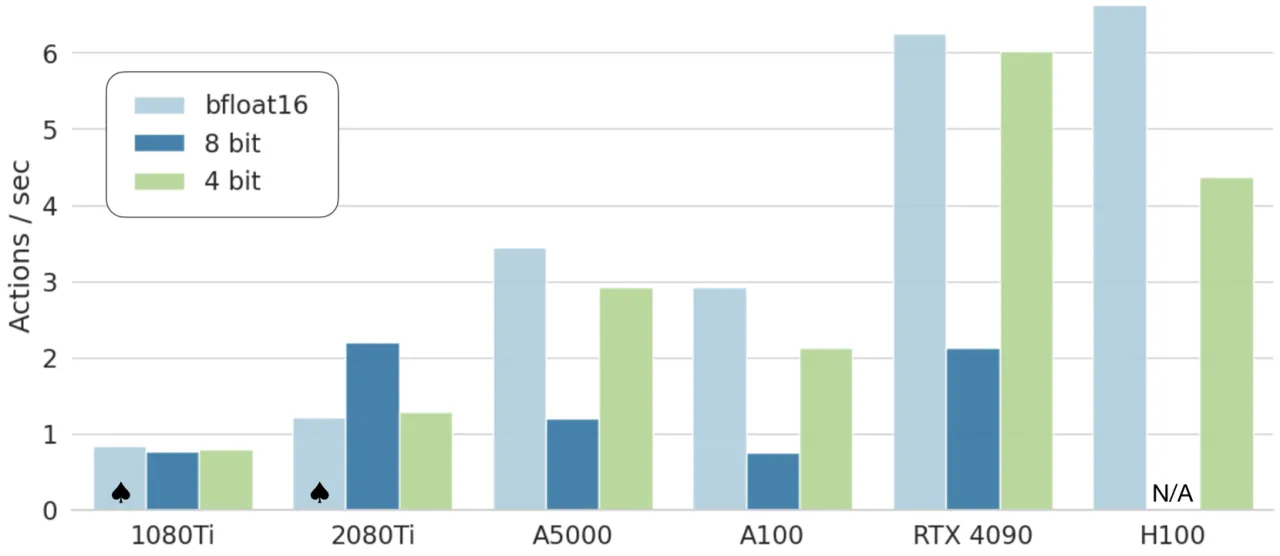
1.4%LoRA 仅需微调该比例参数即可达全量效果
现有方法的两大痛点
封闭生态
RT-2-X 等顶尖 VLA 不公开权重与训练代码,研究者无法复现、改进或深入理解其决策机制。学术界和工业界被迫从头开发,资源浪费严重。
部署门槛高
现有 VLA 论文几乎没有讨论如何高效地将模型适配到新机器人、新场景、新任务。全量微调需要多台 A100,普通实验室无法承受。量化和 LoRA 等方法在 VLA 场景下的效果尚未系统研究。