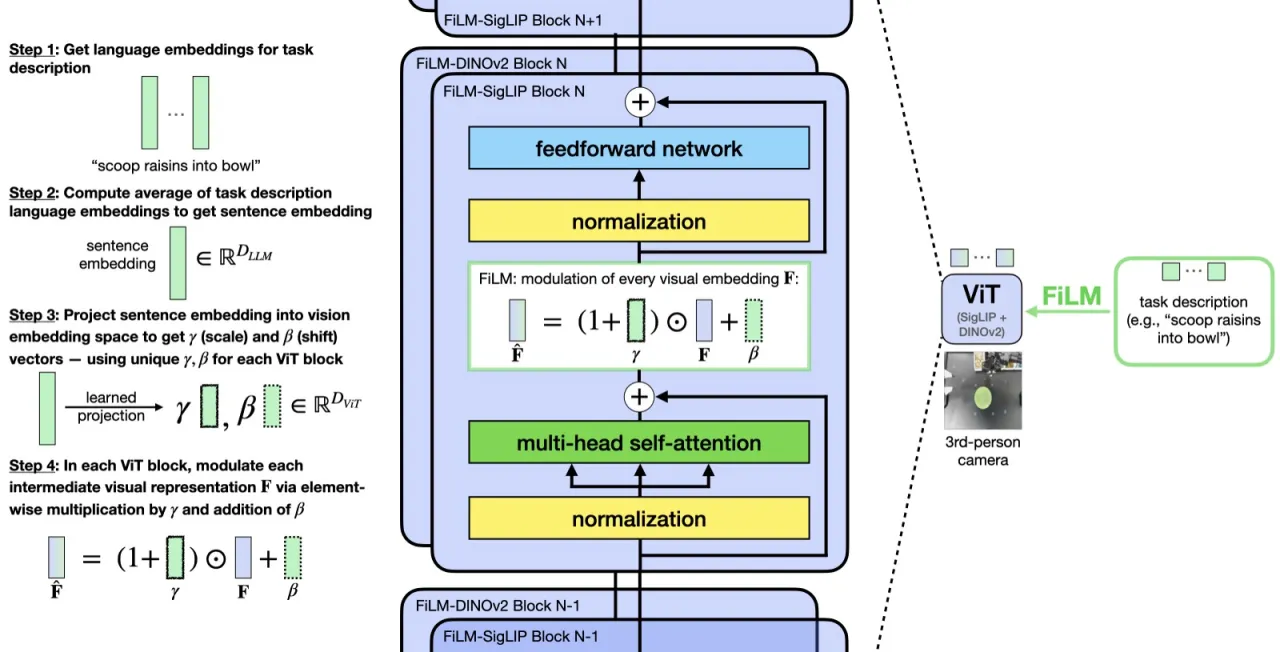
01 动机
VLA 模型(如 OpenVLA)将大规模视觉-语言预训练引入机器人操作,但直接迁移到新场景时面临两大瓶颈:推理速度太慢(自回归逐 token 解码)和成功率不足(离散动作表示精度受限)。已有工作倾向于重新设计预训练,而本文聚焦微调阶段,寻找一套通用、高效的系统性配方。
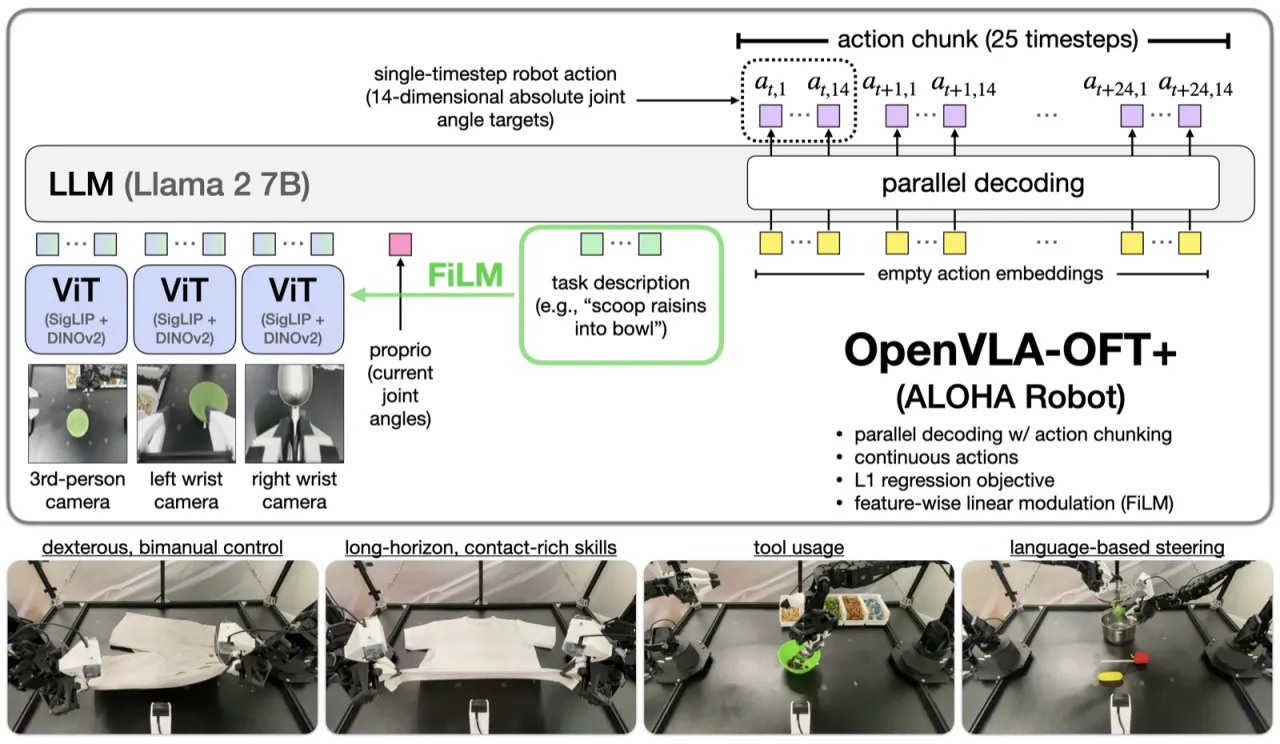
"We investigate optimized fine-tuning (OFT) — a recipe for adapting VLAs to novel robot setups, integrating parallel decoding, action chunking, continuous action representations, and L1 regression."
97.1%LIBERO 平均成功率(最高输入配置)
26×相较于基线 OpenVLA 的吞吐量提升(仿真)
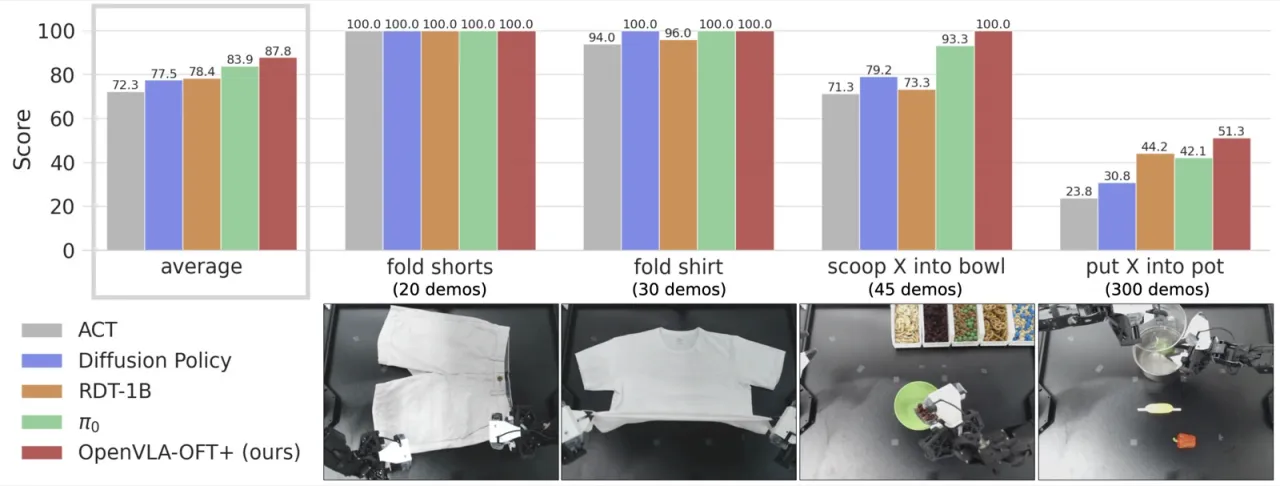
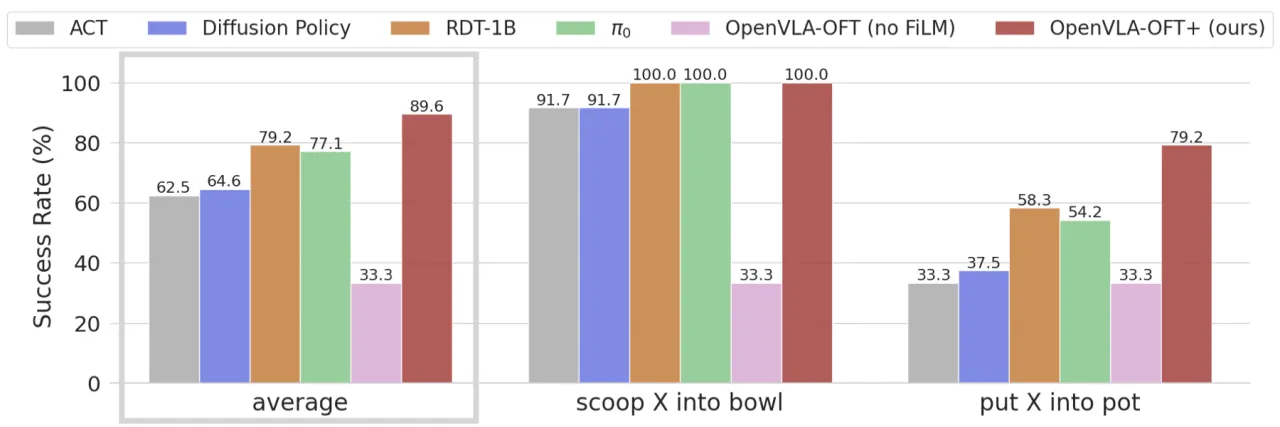
+15%真实机器人绝对成功率提升(vs. π₀、RDT-1B)
43×ALOHA 机器人吞吐量提升(K=25 动作分块)