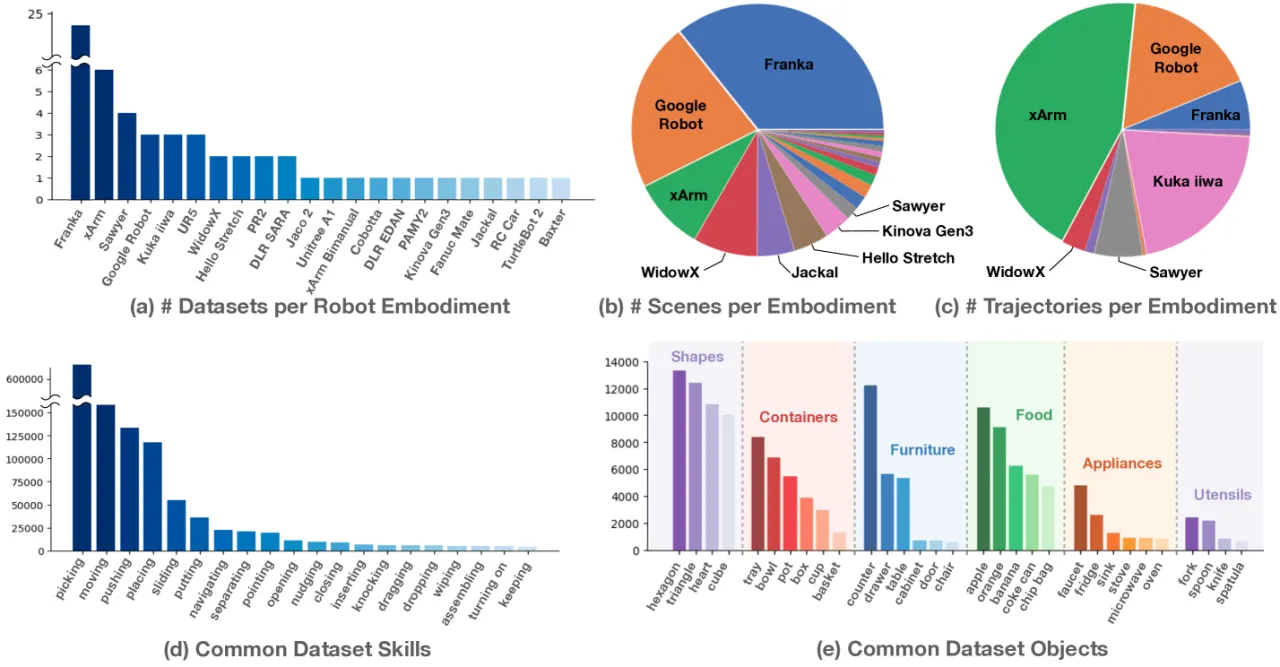
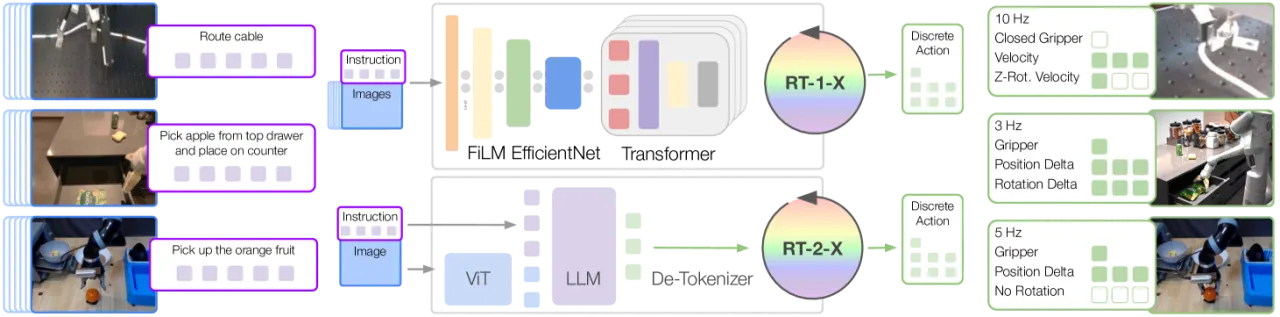
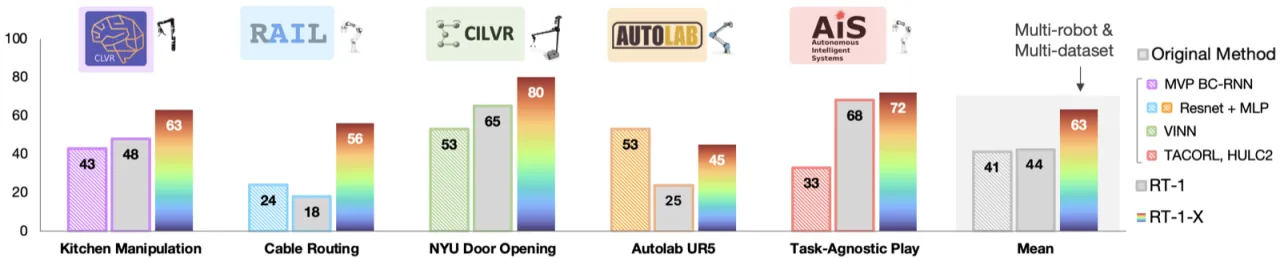
"Robotic learning datasets are often still narrow along some axes of variation, either focusing on a single environment, a single set of objects, or a narrow range of tasks."
消融实验揭示三个关键因素:(1) Web 预训练至关重要——去除后 emergent skills 从44.4%骤降至0%;(2) 模型容量影响迁移效果——55B vs 5B 在 emergent skills 上相差约31个百分点(75.8% vs 44.4%);(3) 图像历史帮助性能——去除后 emergent skills 下降约30个百分点。
04 局限性
Note: 以下局限性均来自论文正文作者明确陈述(stated by authors)。
不涵盖感知与驱动模态差异极大的机器人
论文原文:"Our experiments do not consider robots with very different sensing and actuation modalities."
当前实验主要集中在使用相机视觉输入和标准末端执行器的机械臂,未探索触觉传感、力传感器、腿式机器人等差异更大的模态。
未研究向全新机器人的泛化(zero-shot embodiment transfer)
论文原文:"They do not study generalization to new robots, and provide a decision criterion for when positive transfer does or does not happen."
所有评估机器人均在训练阶段出现过,未测试能否将策略迁移到从未见过的机器人平台。