01 动机
高保真运动追踪是检验 humanoid 运动技能泛化能力的"终极试金石"。但当 motion library 覆盖越来越多样的风格、接触状态与节奏模式时,追踪质量反而系统性下降,高动态动作尤甚。
"when we scale to larger, more heterogeneous motion libraries spanning diverse styles, contact regimes, and timing modes, motion tracking quality tends to degrade. Controllers become conservative and 'average,' break on the hardest motions, or prove brittle to the small deviations that inevitably occur in sim-to-real transfer."
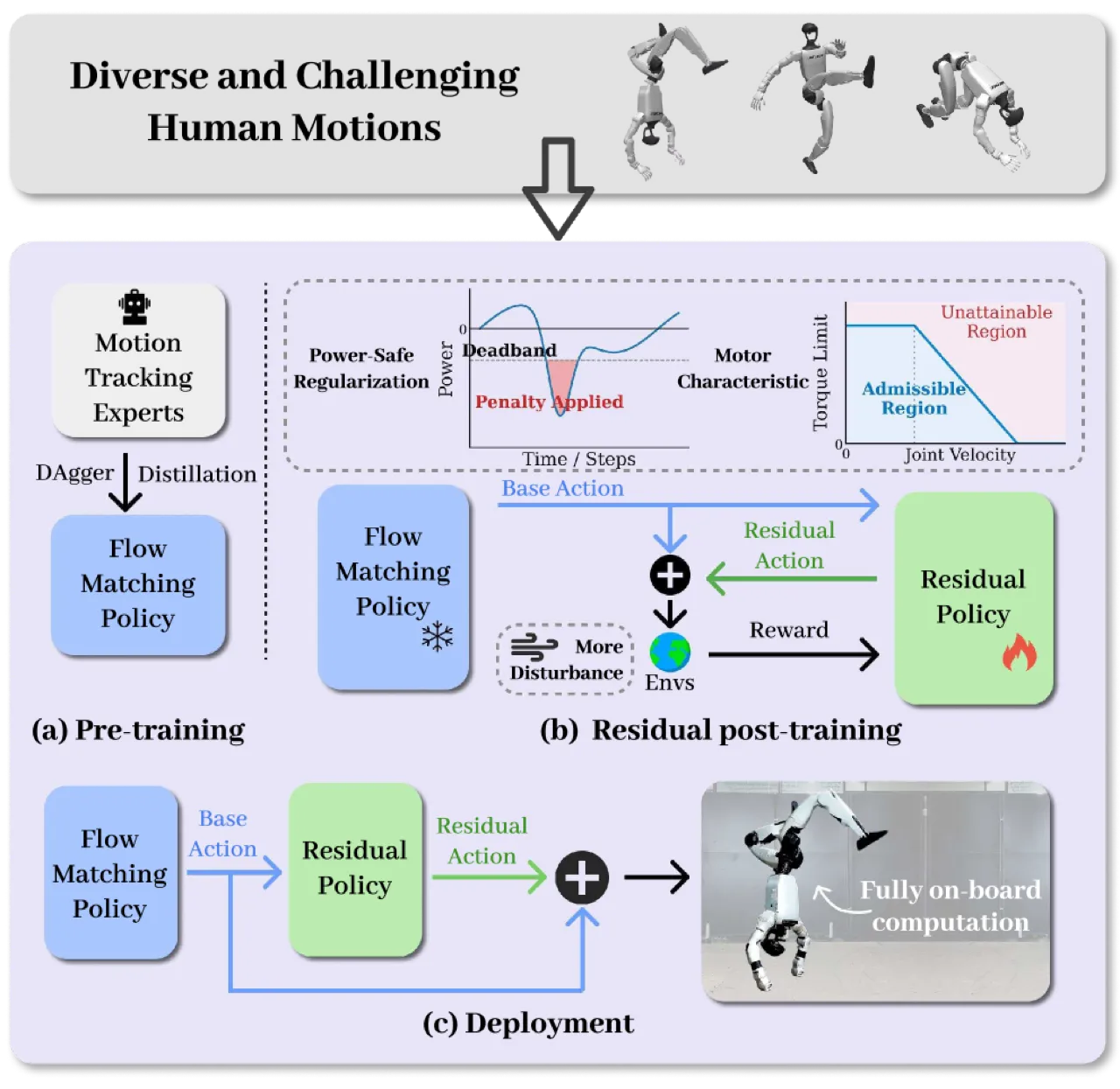
作者将这一"泛化壁垒"归因于两个叠加障碍:
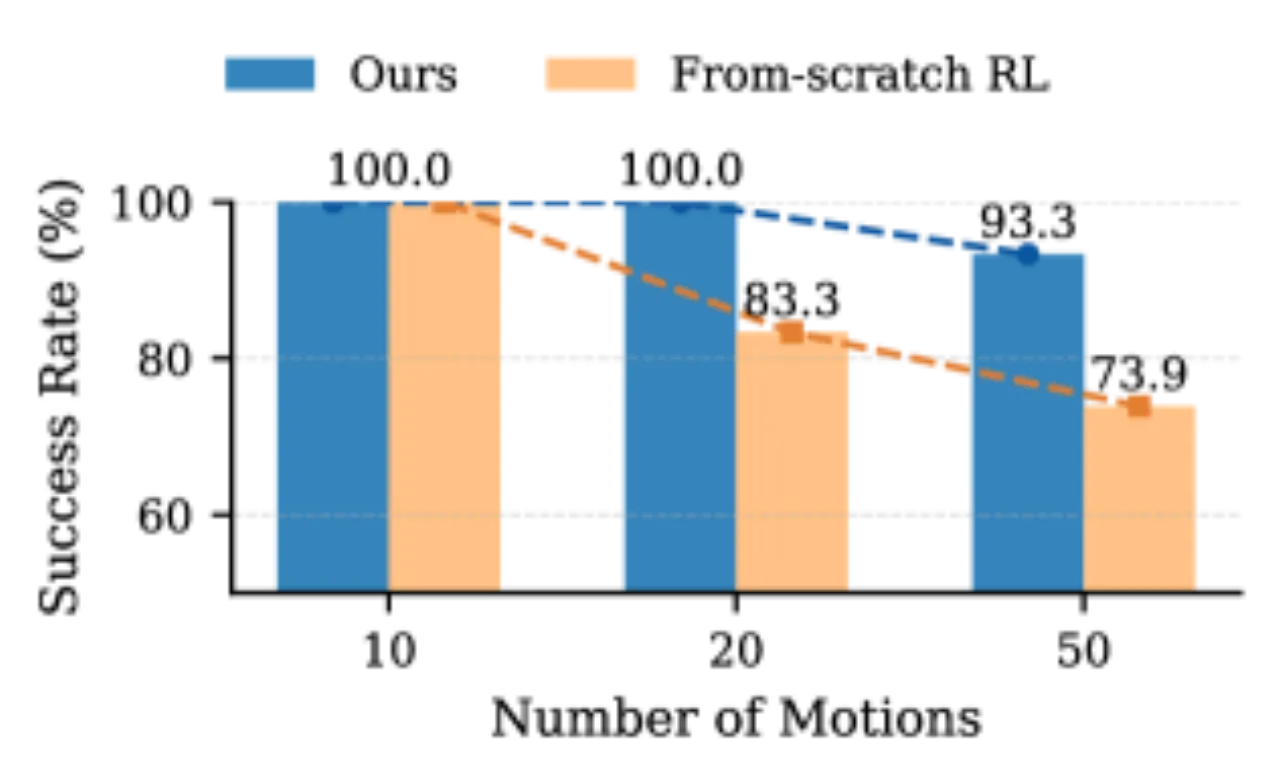
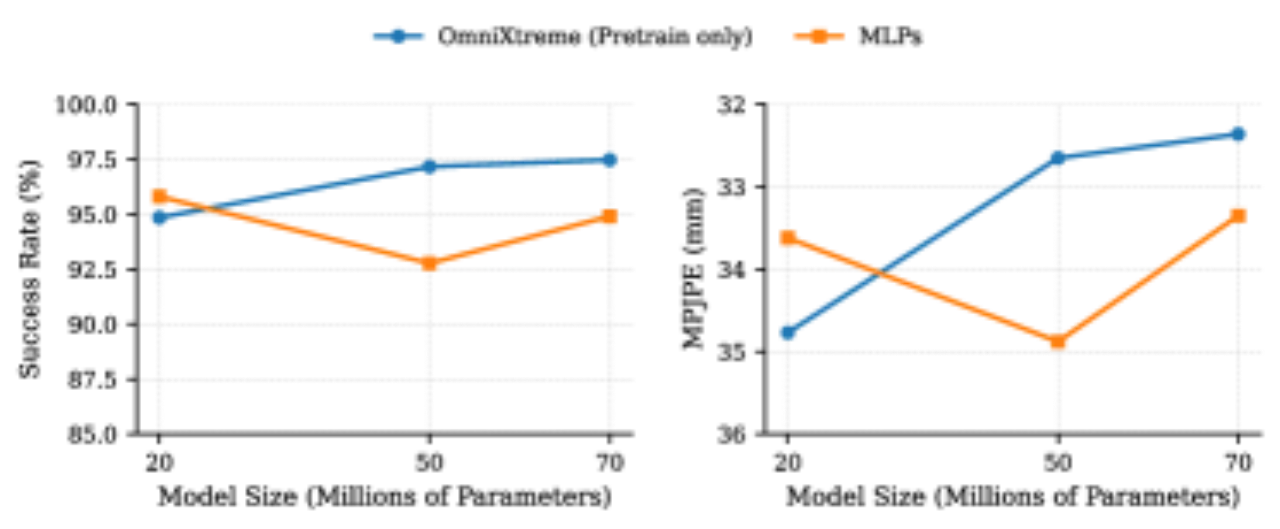
- 学习瓶颈(learning bottleneck):现有方法依赖简单 MLP,在多运动联合 RL 训练中存在梯度干扰,导致策略向"保守均值"退化,在高动态行为上选择性失败。
- 物理可执行性瓶颈(physical executability bottleneck):即便仿真中追踪保真,真机部署时仍因建模缺失(力矩–速度特性、速度相关力矩损耗、再生制动等致动器非线性)而快速失稳。
91.08%真机综合成功率(157 次)
96.36%翻跟头(Flip)成功率(55 次)
30.93 mm仿真 MPJPE(LaFAN1 + XtremeMotion)
10 ms板载推理端到端延迟