01 动机
大规模预训练已彻底改变了 NLP 与计算机视觉领域,但机器人学习为何仍难以复制这一成功?核心障碍在于机器人的多样性:不同的本体(embodiment)、传感器配置、动作空间和任务规范,使得统一的通用策略难以构建。现有的通用机器人策略(Generalist Robot Policies, GRP)通常将用户锁定在固定的观测输入格式上,且对新平台的微调支持十分有限。
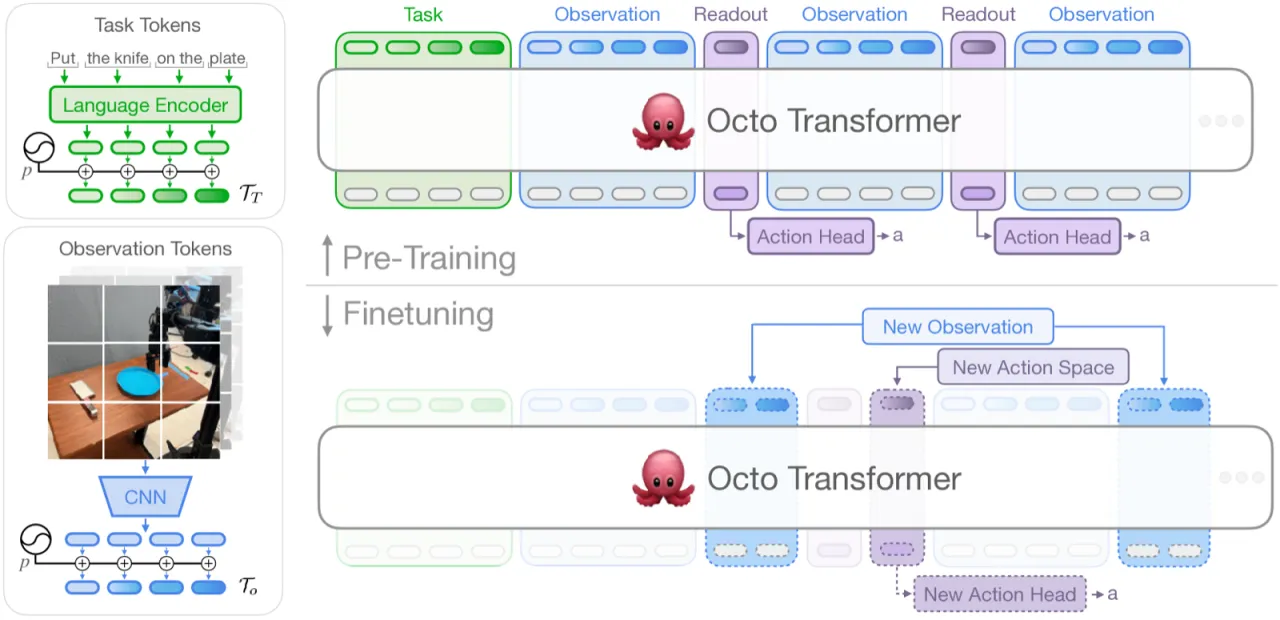
"Octo is the first GRP that can be effectively finetuned to new observations and action spaces."
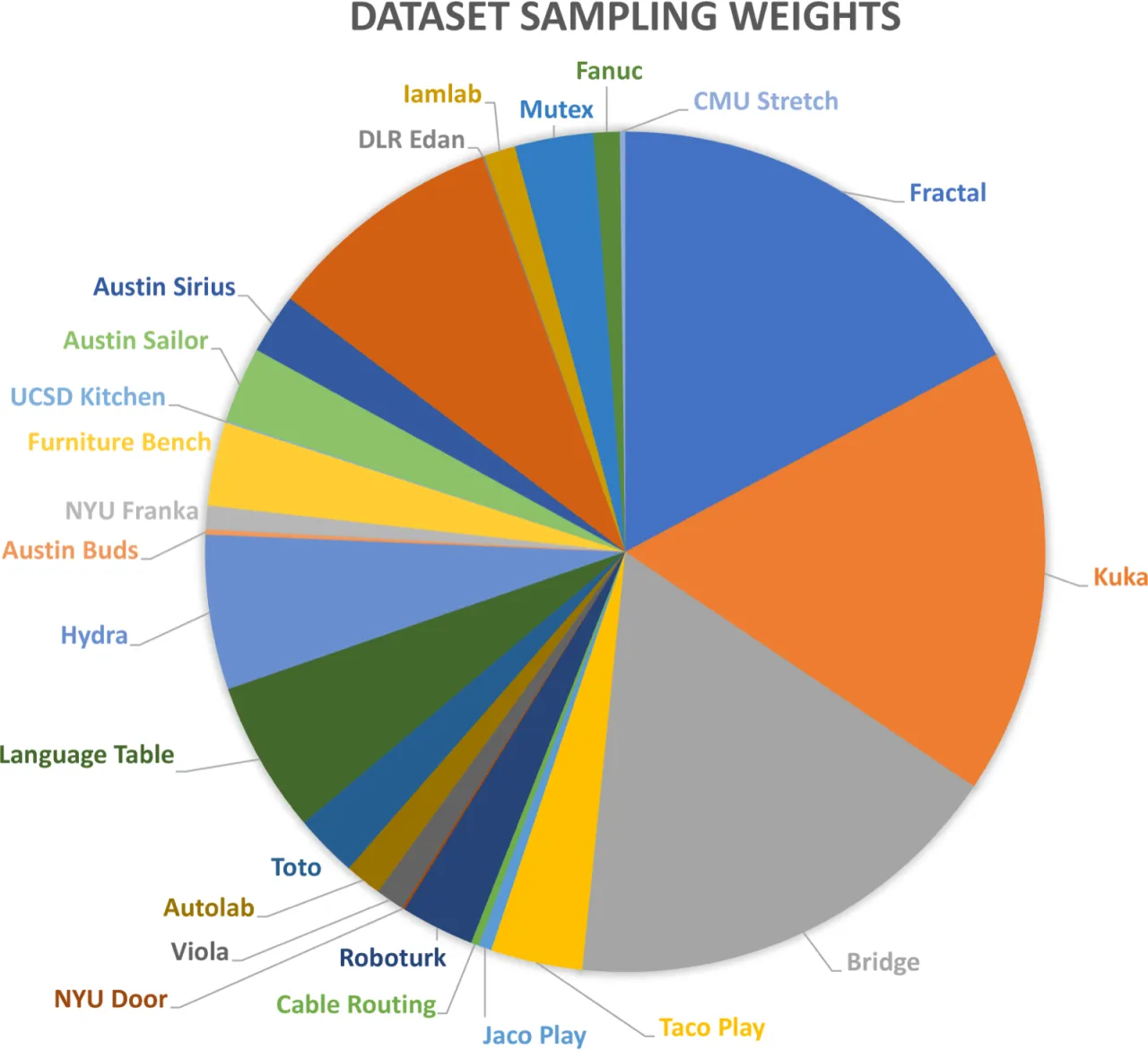
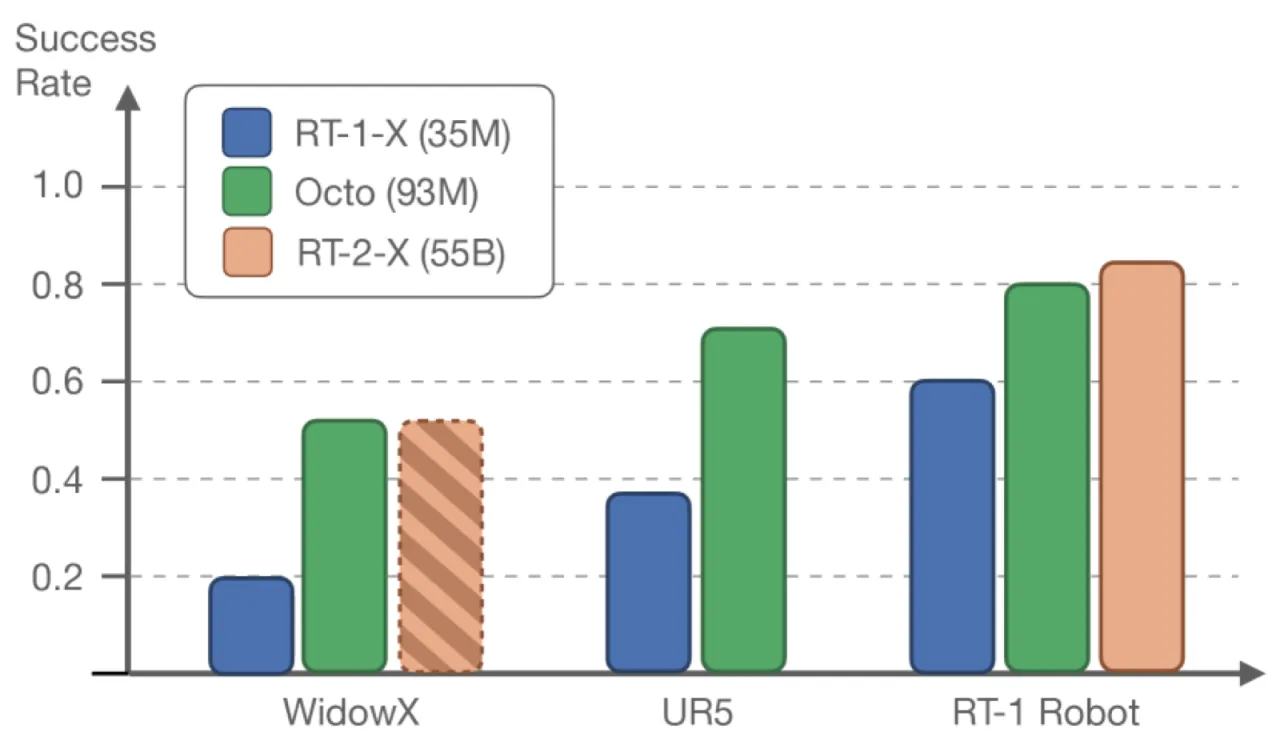
800k预训练轨迹数(Open X-Embodiment)
25训练数据集来源
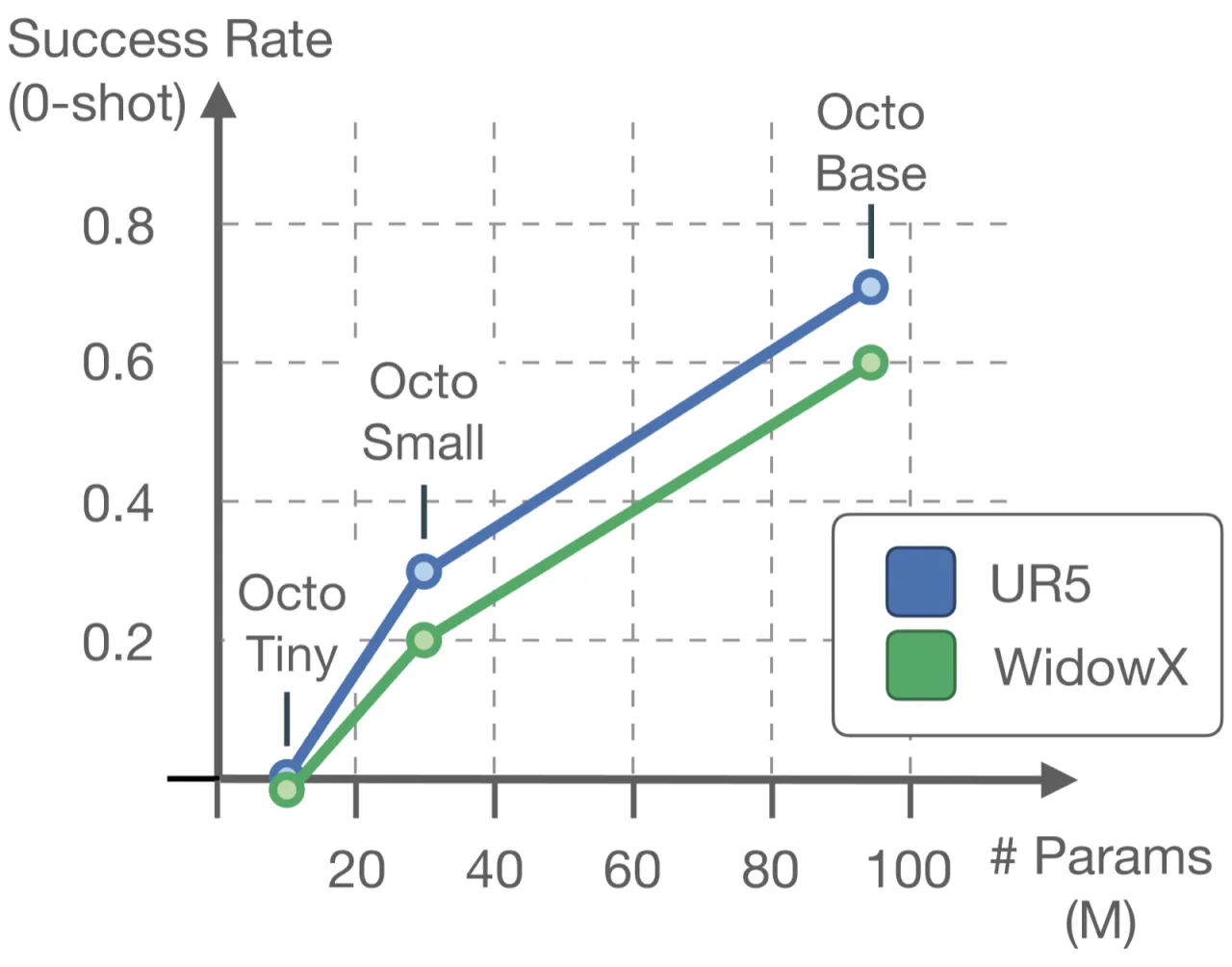
9零样本评估机器人平台数
72%微调后六项任务平均成功率