01 动机
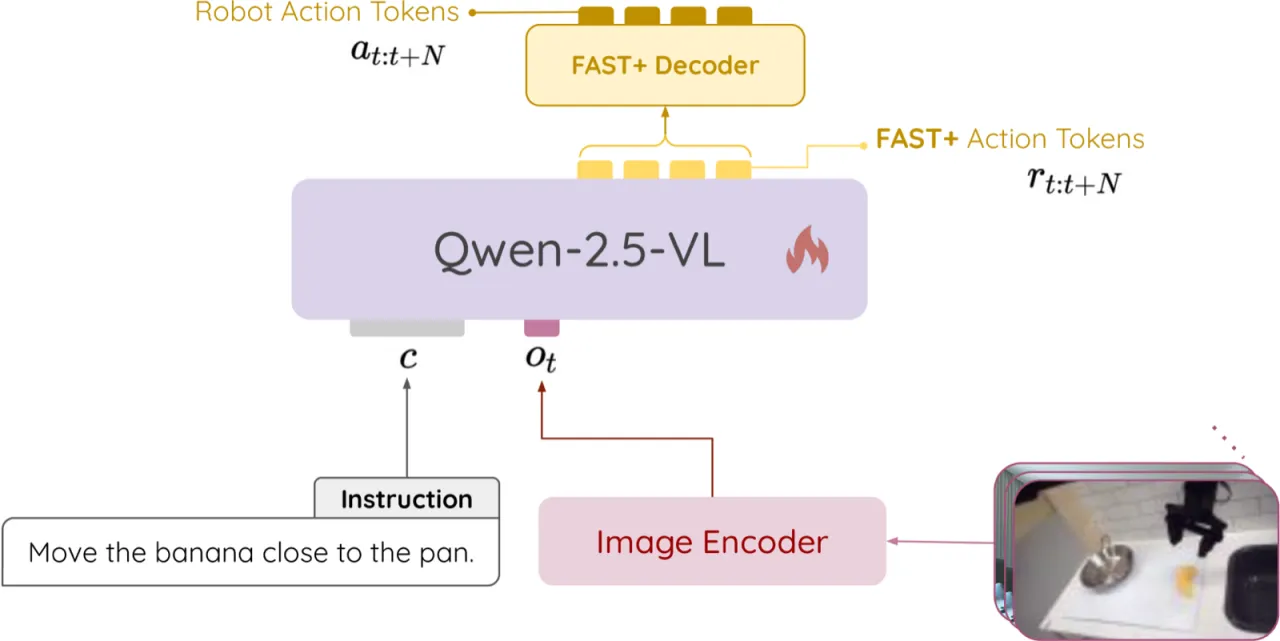
现有的 Vision-Language-Action(VLA)系统在性能上表现出色,但普遍面临计算开销过大的问题:主流模型(OpenVLA、TraceVLA、ECOT 等)参数规模接近甚至超过 7B,导致实时部署困难,且无法在消费级 GPU 上直接微调。另一方面,现有方法在精细操作任务(如目标抓取)中的视觉编码能力仍不足。
"Existing VLA models are typically large-scale, with model sizes approaching 7B parameters, such as OpenVLA, and even larger in methods like TraceVLA, ECOT, and EMMA-X."
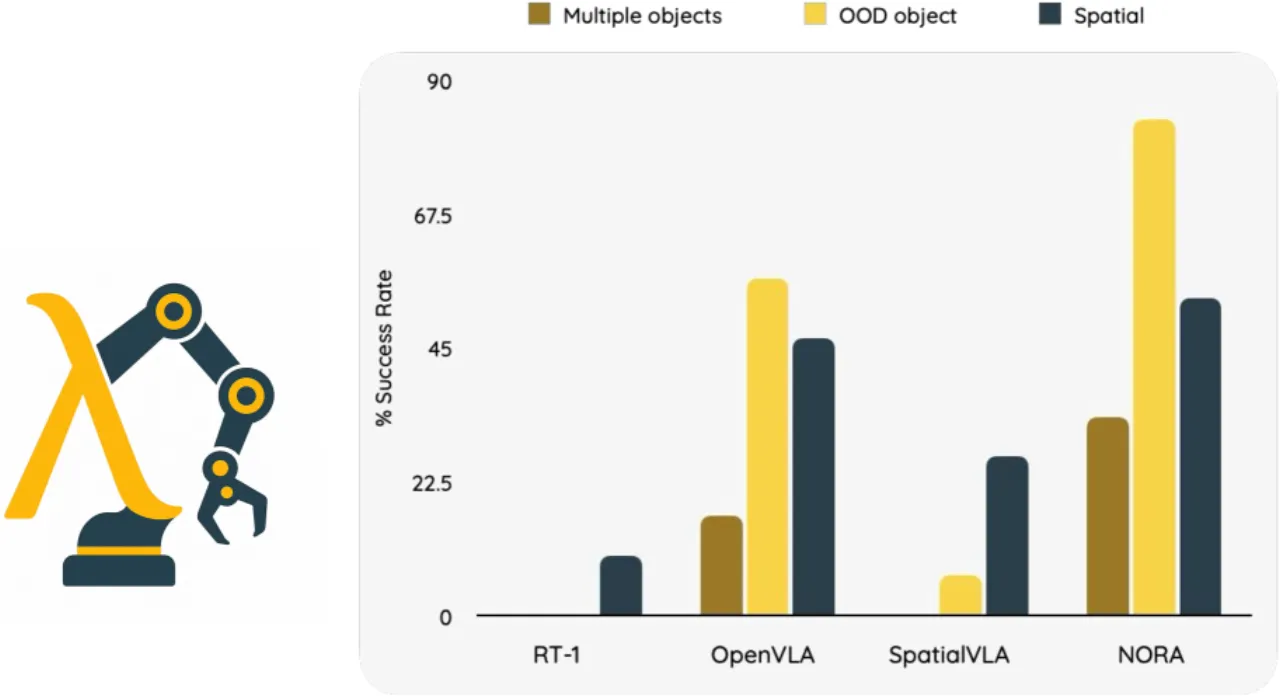
3B模型参数量(vs. 7B+ 基线)
56.7%真实 WidowX 机器人平均成功率
87.9%LIBERO 四套任务平均成功率(NORA-Long)
~1M训练用真实机器人演示数据量