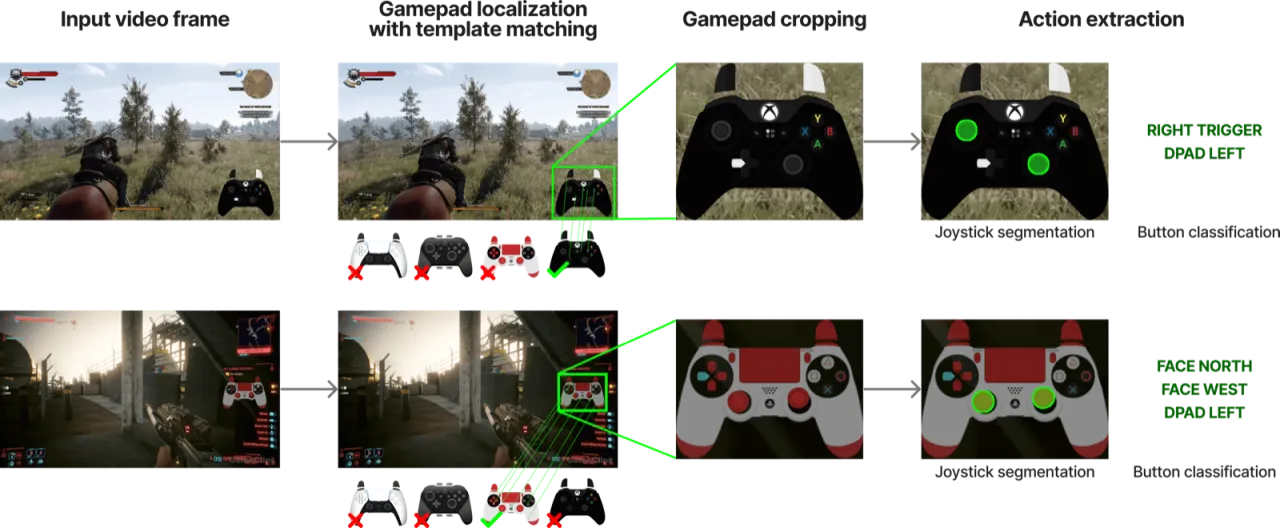
01 动机
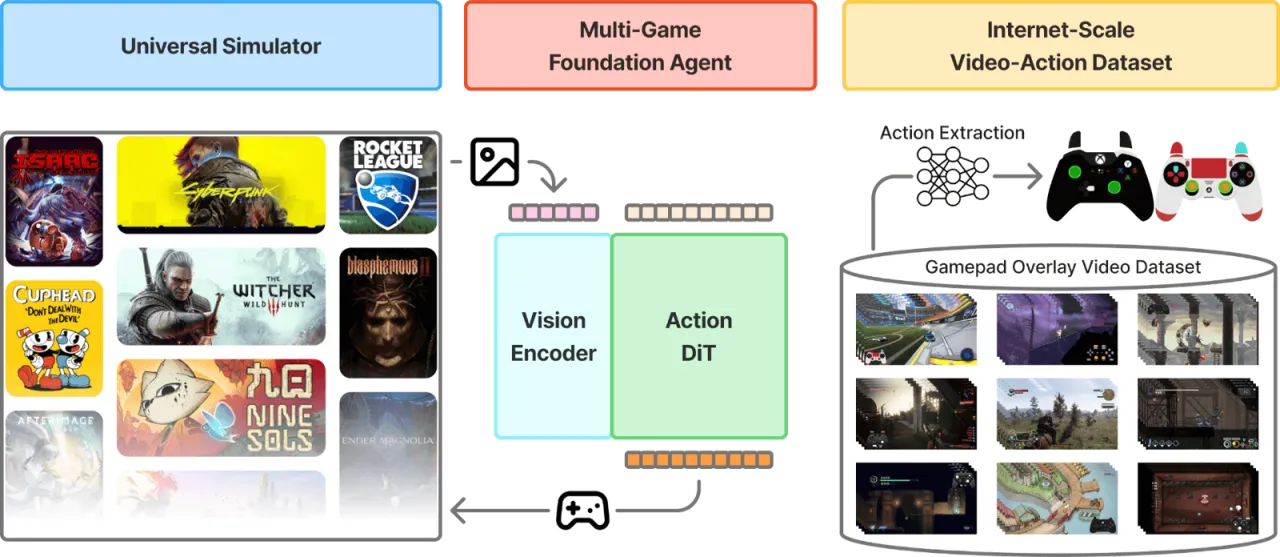
电子游戏是训练通用具身智能体的理想沙盒:它们种类繁多、规则多样、且无需物理硬件。然而,现有方法要么依赖手工设计的 API(如 Voyager),要么需要昂贵的强化学习训练(如 DQN、AlphaStar),要么人工演示数据规模极为有限。本文的核心问题是:能否直接从互联网上海量、嘈杂的玩家录像中,自动学习跨越千款游戏的视觉-动作策略?
"We present a vision-action foundation model trained on 40,000 hours of gameplay videos across more than 1,000 games."
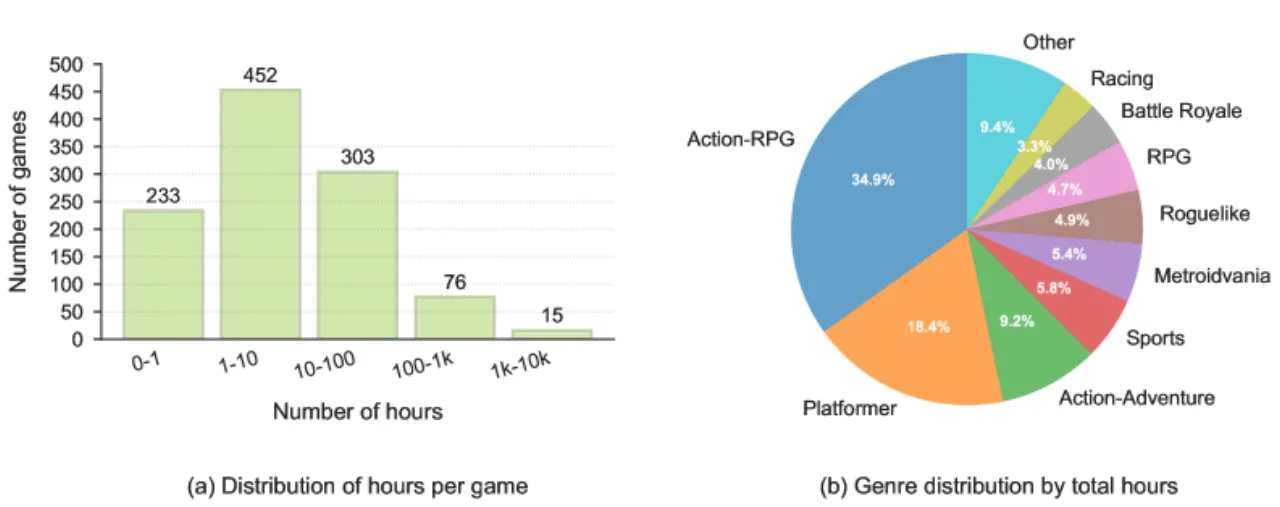
40K训练视频总时长(小时)
1,000+覆盖游戏数量
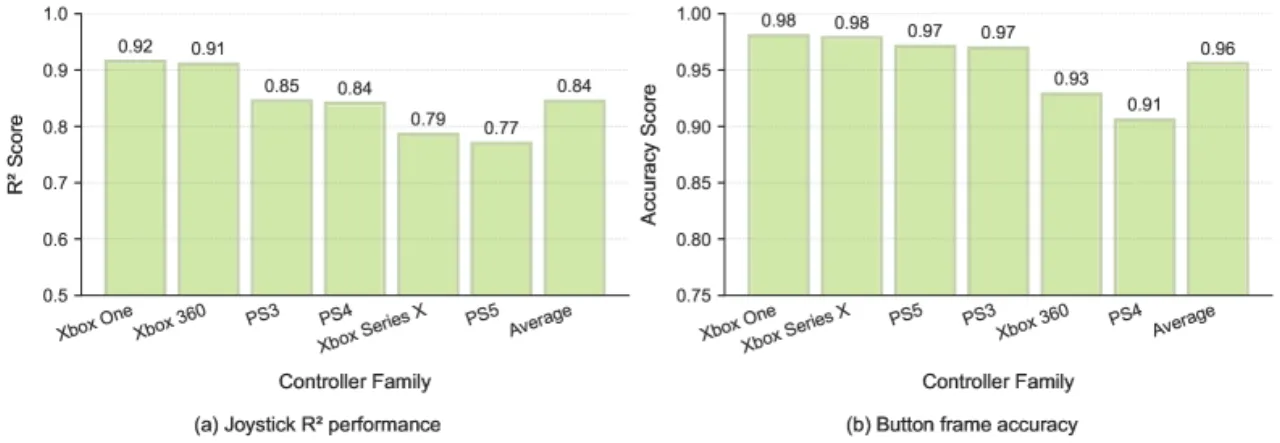
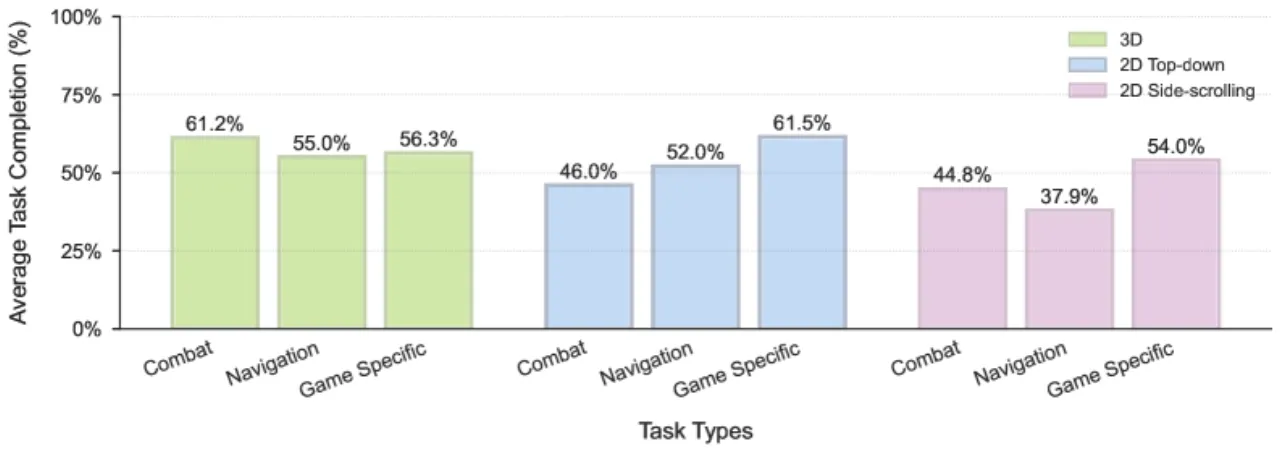
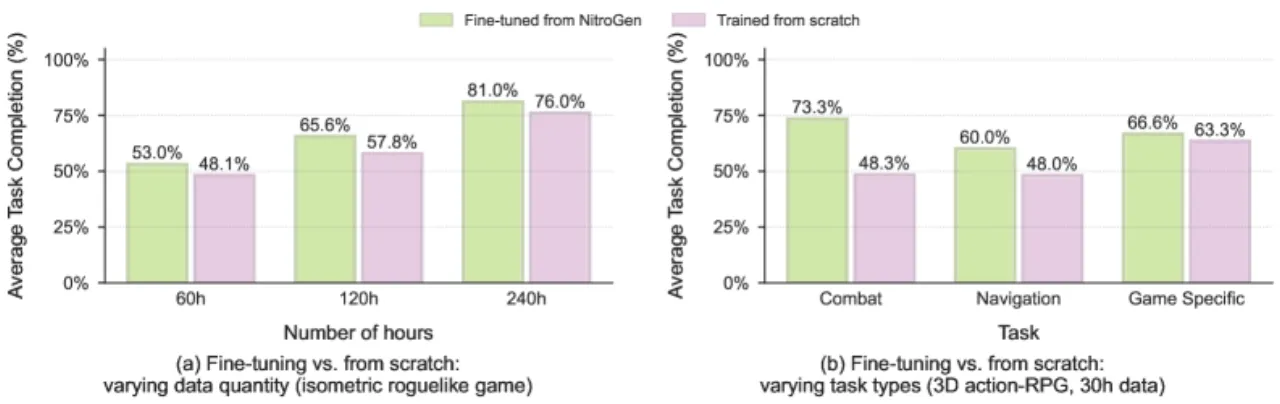
52%战斗任务迁移相对提升
30跨 10 款游戏的评测任务