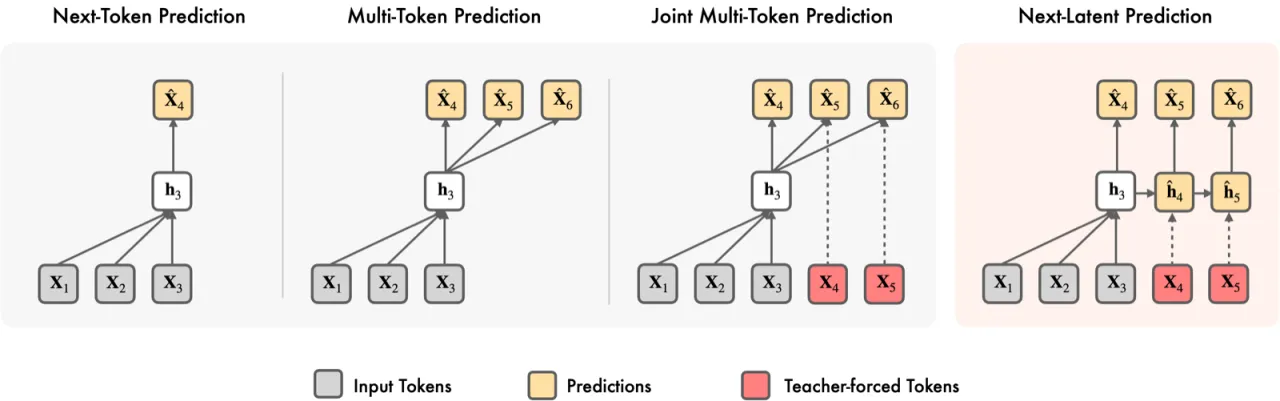
01 动机 · Motivation
Transformer 的自注意力机制允许模型在任意时刻直接"查询"过去的 token,从而不必把历史信息压缩成紧凑的内部状态。这带来了一个根本性的问题:
"Transformers lack an inherent incentive to compress history into compact latent states with consistent transition rules, which often leads to learning solutions that generalize poorly."
相比之下,循环神经网络(RNN)因为每步只能访问一个固定大小的隐藏状态,被迫学习紧凑的状态表征。如果能把这种"循环归纳偏置"(recurrent inductive bias)注入 Transformer,同时保留其并行训练优势,就能得到一个既高效又泛化能力强的模型。这正是 NextLat 的出发点。
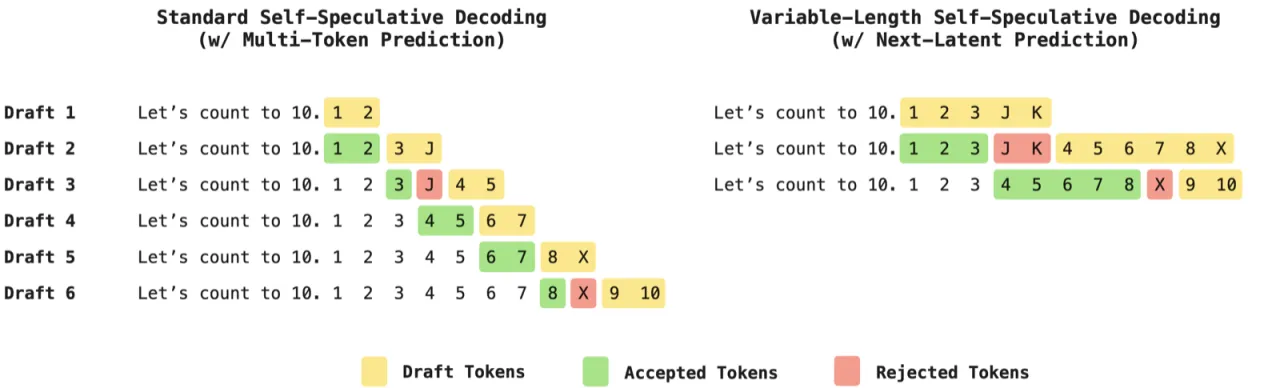
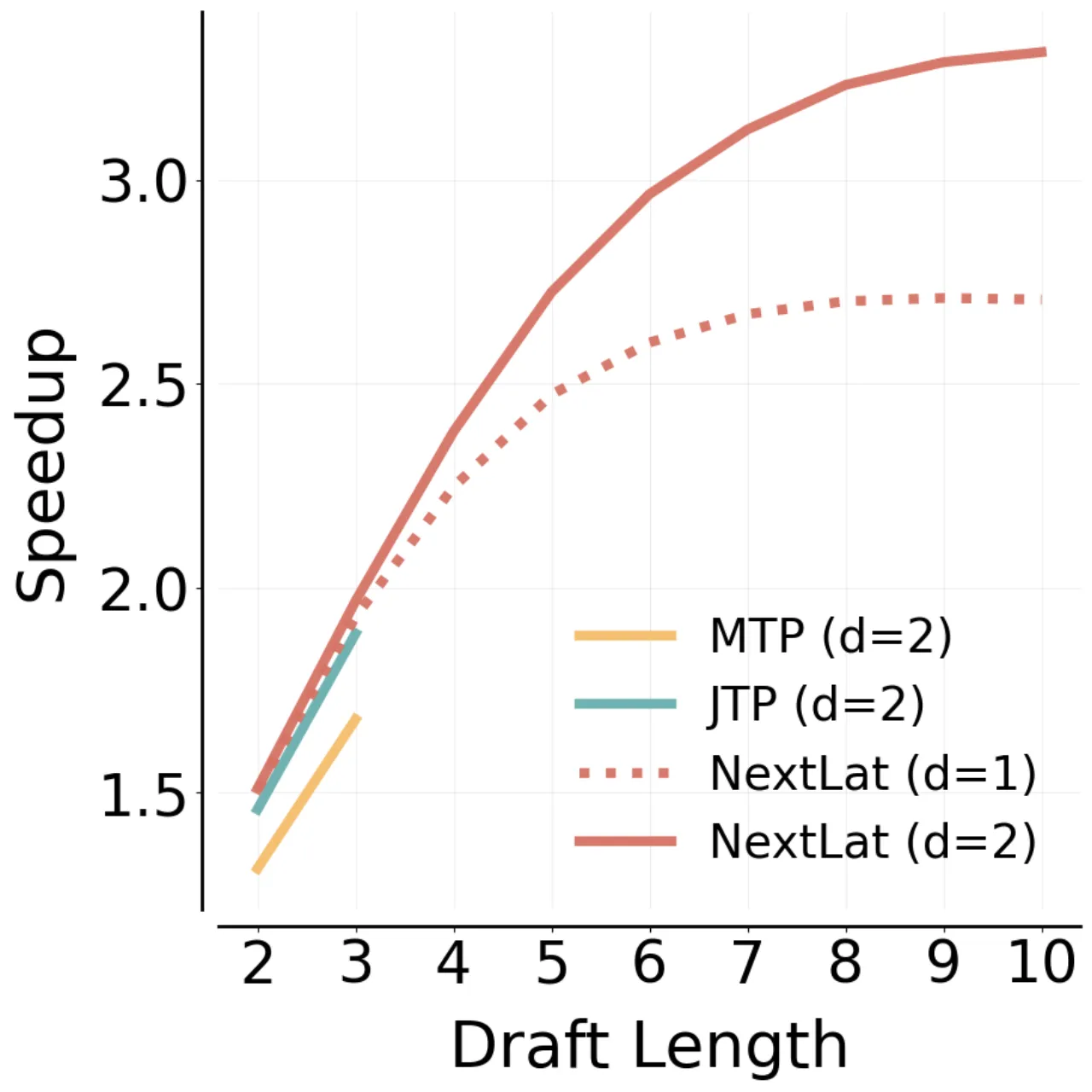
3.32×推理加速(Books 集,speculative decoding)
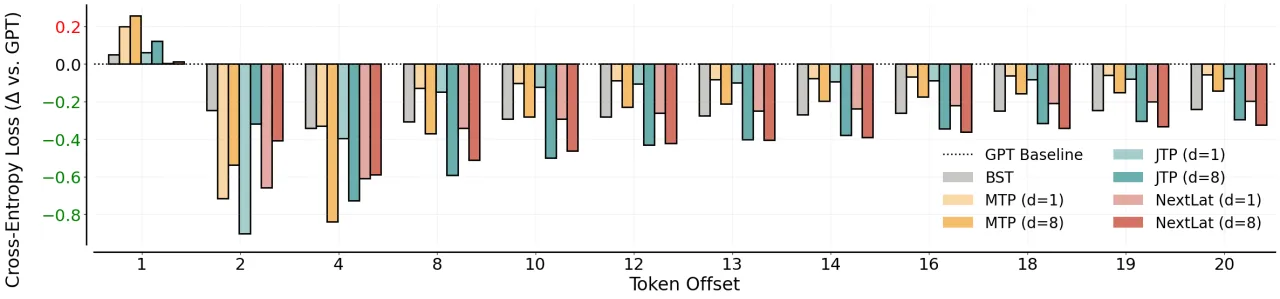
52.7NextLat 有效潜在秩(vs. GPT 的 160.1,压缩 3×)
98.7%世界建模任务 OOD 有效轨迹率(vs. GPT 97.0%)
~100%G₇,₇ 规划任务准确率(MTP/JTP 大幅失败)