01 动机
现有的视觉导航策略通常是"硬编码"的:一旦训练完成,就无法在推理阶段动态引入新的约束或反事实推理。 如果导航过程中遇到障碍、需要绕道,或需要在完全陌生的场景中规划路径,这类策略几乎无从应对。 更根本的问题是:如何让机器人在脑中"想象"轨迹,并以此筛选出最优方案?
"Unlike fixed policies, NWM can imagine trajectories considering constraints and counterfactuals, enabling dynamic constraint incorporation during the planning phase."

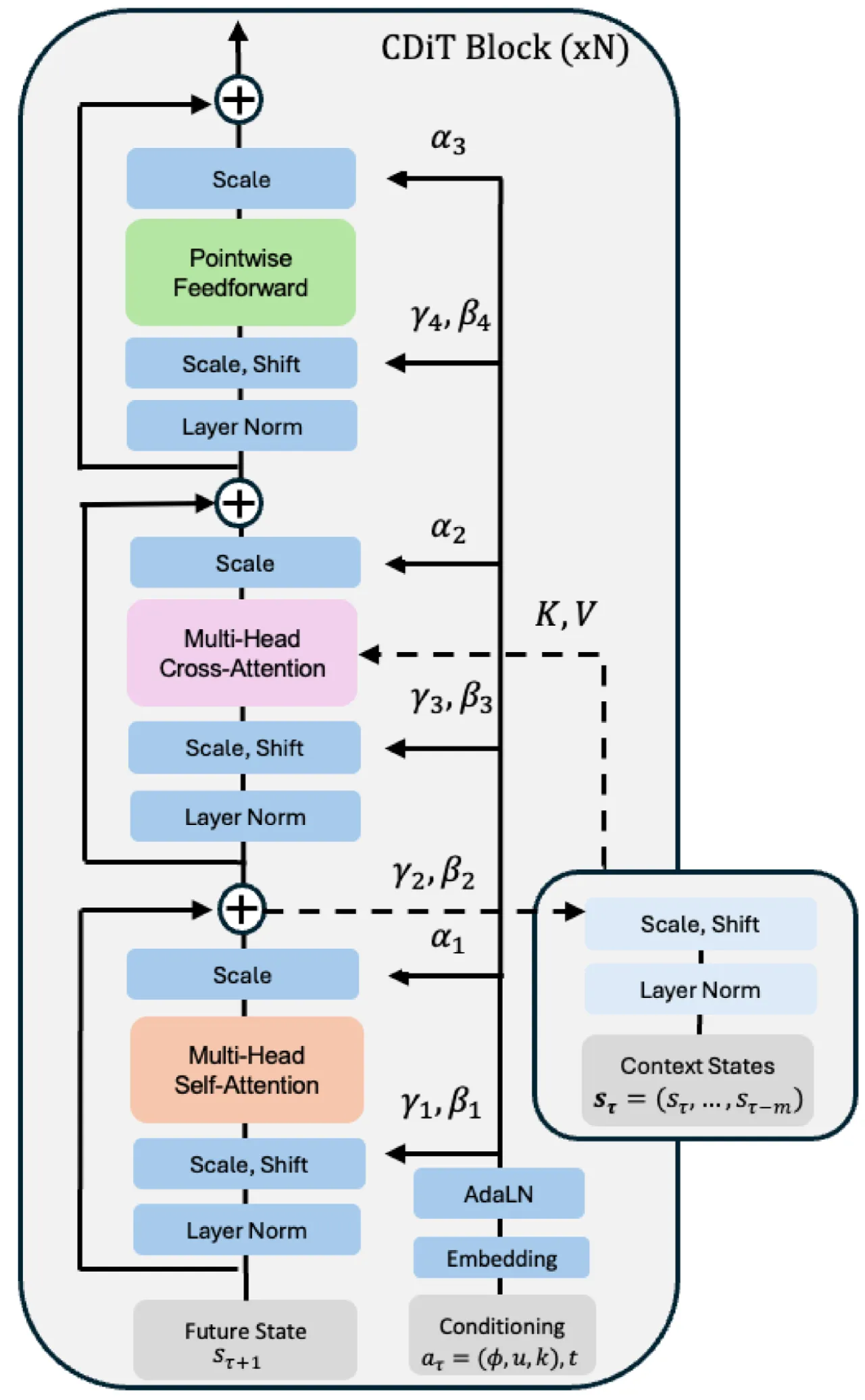
1BCDiT 最大参数规模
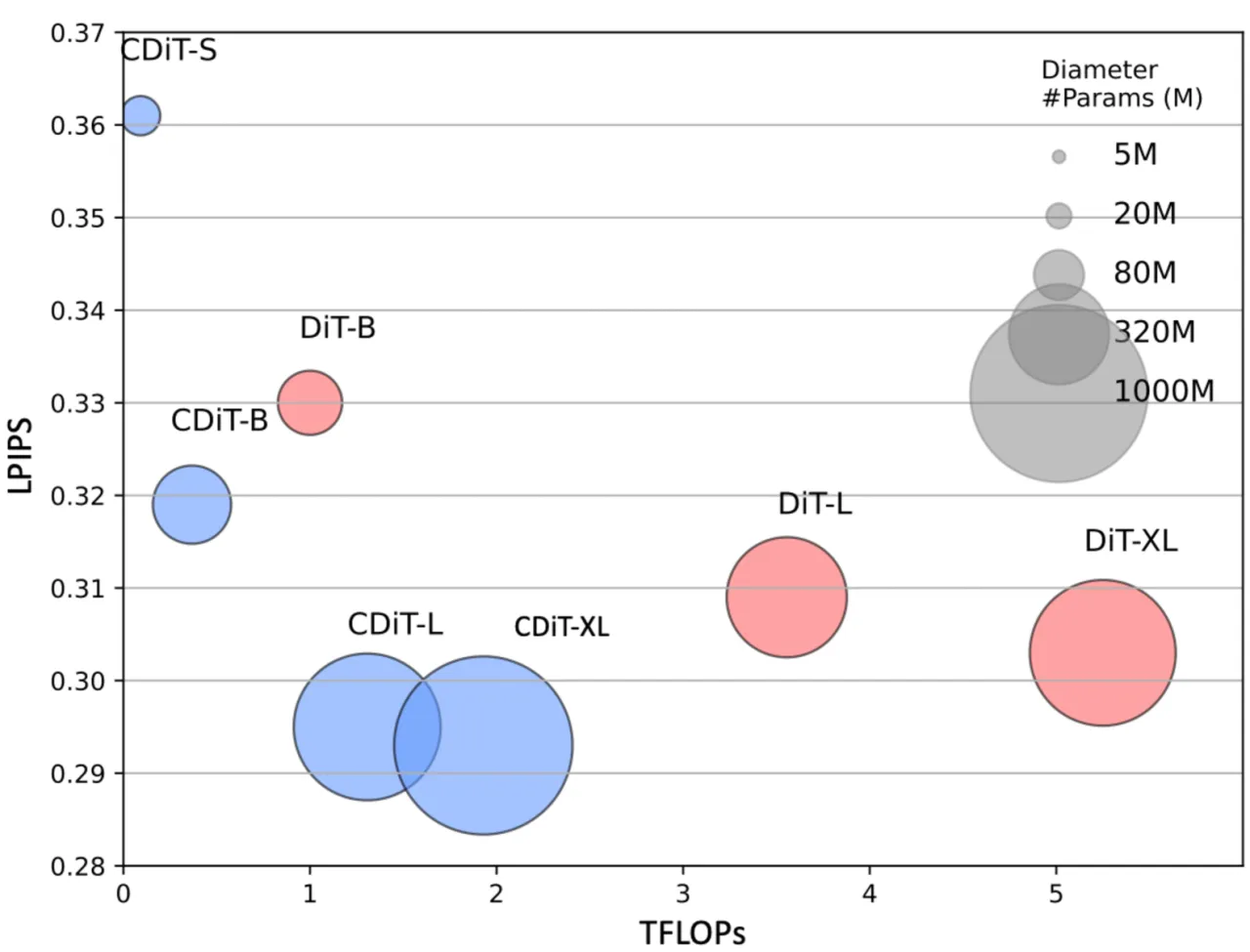
4×CDiT vs. DiT FLOPs 减少(相同 LPIPS 下)
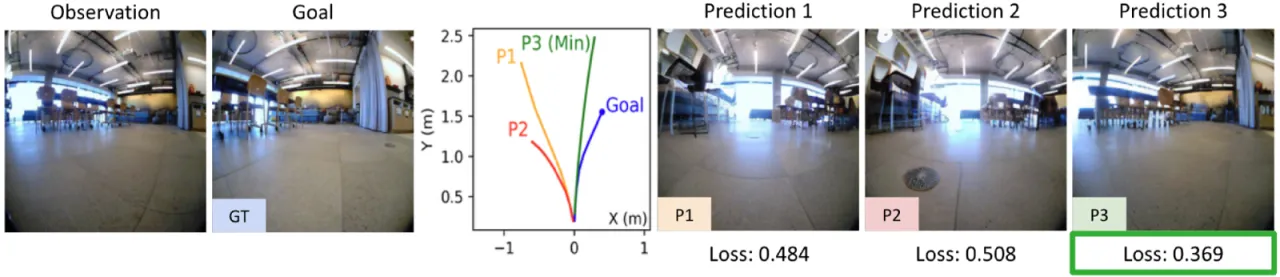
200.97NWM FVD(RECON),优于 DIAMOND 的 762.73
908hEgo4D 无标注视频辅助训练