03 实验实验在 6 个任务域上展开:Point Maze、Wall、Rope、Granular(来自 D4RL、DeepMind Control Suite)、PushT 和 RT-1(机器人操作数据)。评估指标:PSNR(像素保真度)、SSIM(结构相似性)、LPIPS(感知距离)、FID(分布相似性),以及决策任务的 Success Rate。验证集使用 256 个固定 seed=42 的片段。
发现一:预测目标对比(RT-1 Fractal 数据集,NanoWM-B/2)
预测目标 噪声调度 PSNR ↑ SSIM ↑ LPIPS ↓ FID ↓ v-prediction cosine + ZTSNR 23.07 0.760 0.207 42.27 x-prediction cosine + ZTSNR 23.37 0.783 0.184 42.99 ε-prediction linear 21.89 0.739 0.225 48.86
v-prediction 在 FID 上最优;x-prediction 在重建指标(PSNR/SSIM/LPIPS)上最优。两者均大幅优于 ε-prediction。
发现二:模型规模消融(RT-1 Fractal)
架构 参数量 PSNR ↑ SSIM ↑ LPIPS ↓ FID ↓ NanoWM-S/2 39.8M 22.30 0.739 0.230 54.95 NanoWM-B/2 158.6M 23.07 0.760 0.207 42.27 NanoWM-L/2 ~460M 23.62 0.777 0.186 36.31
规模扩大在所有指标上均带来一致提升。
发现三:动作注入方式对比
RT-1 数据集
方法 PSNR FID ↓ 参数量 additive 23.07 42.27 158.6M adaLN 23.19 43.62 158.6M adaLN-fuse 23.10 43.03 158.6M FiLM 23.20 40.62 172.8M cross-attention 20.82 51.12 187.0M
PushT 数据集
方法 PSNR FID ↓ additive 26.20 23.89 adaLN-fuse 26.17 30.28 adaLN 26.09 26.32 cross-attention 25.95 28.64 FiLM 25.88 25.45
动作注入方式的优劣具有任务依赖性 :FiLM 在 RT-1 上 FID 最优(40.62);additive 在 PushT 上以最少参数量取得最佳 PSNR 和 FID。Cross-attention 在 RT-1 上表现最差(FID 51.12),尽管参数量最多。
发现四:潜在空间对比(PushT 目标条件规划)
潜在空间 骨干网络 Latent Shape 成功率 ↑ SD-VAE NanoWM-B/2 [4, 32, 32] 25.0% Web-DINO NanoWM-B/1 [1024, 16, 16] 0.0% V-JEPA 2.1 NanoWM-B/1 [1024, 16, 16] 0.0%
诊断实验(真实动作 rollout 的 Latent MSE)揭示了失败根源:Web-DINO 和 V-JEPA 2.1 的动作嵌入 RMS 量级(分别为 0.00214 和 0.00129)远低于 SD-VAE(0.1119),表明语义潜在空间下模型几乎完全忽略动作信号,成为"动作无关"模型。这暗示扩散目标函数不足以强制语义表征中的动作利用。
图 2:多域定性 rollout 对比(Qualitative rollouts across domains)。 展示 Point Maze、Wall、Rope、Granular、PushT 和 RT-1 的真实帧(GT)与 NanoWM 预测帧对比。统一的数据集与环境接口使网格导航、仿真控制和机器人视频预测在同一 rollout 格式下可比较。
发现五:跨域性能(统一训练方案)
数据集 训练步数 PSNR ↑ SSIM ↑ LPIPS ↓ FID ↓ Point Maze 30K 36.74 0.984 0.019 9.66 Wall 15K 34.05 0.994 0.010 2.64 Rope 15K 31.63 0.953 0.056 35.20 Granular 15K 26.08 0.917 0.073 40.05 PushT 100K 33.19 0.982 0.016 13.63 RT-1 300K 24.36 0.787 0.180 35.08
统一训练方案在所有域上均有效。视觉/动态复杂度越高(如 Granular、RT-1),性能越低;简单仿真环境(Wall、Point Maze)表现最优。
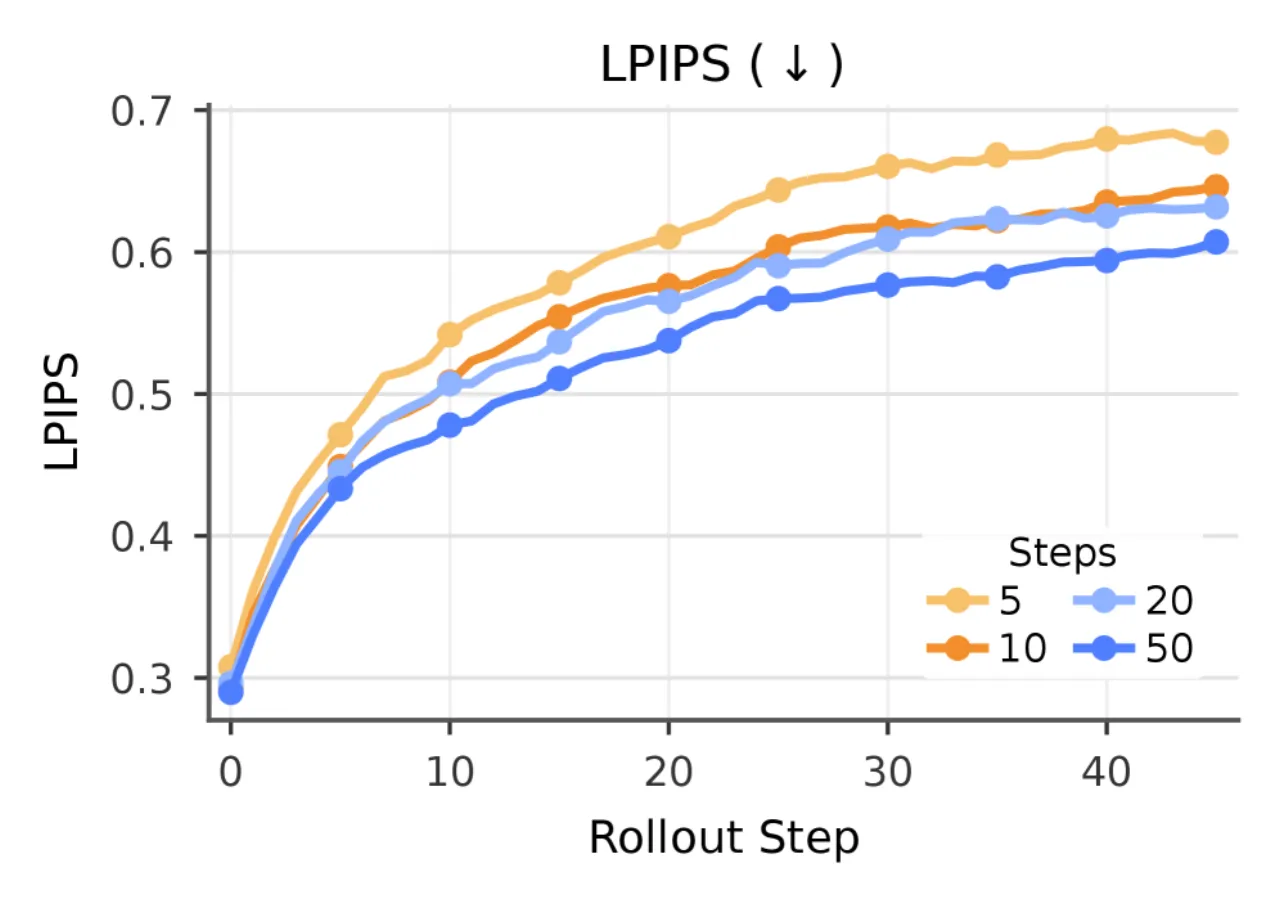
发现六:长程 Rollout 误差累积
图 6:Error Accumulation(误差累积曲线)。 随着 rollout 步数增加,感知误差(LPIPS)持续累积。增加 DDIM 采样步数(50→250)在整个 rollout 范围内一致降低 LPIPS,表明更强的单帧去噪可缓解误差复合。模型在长程序列上能保持粗略的场景几何和摄像机运动,但细节的感知误差不断积累。
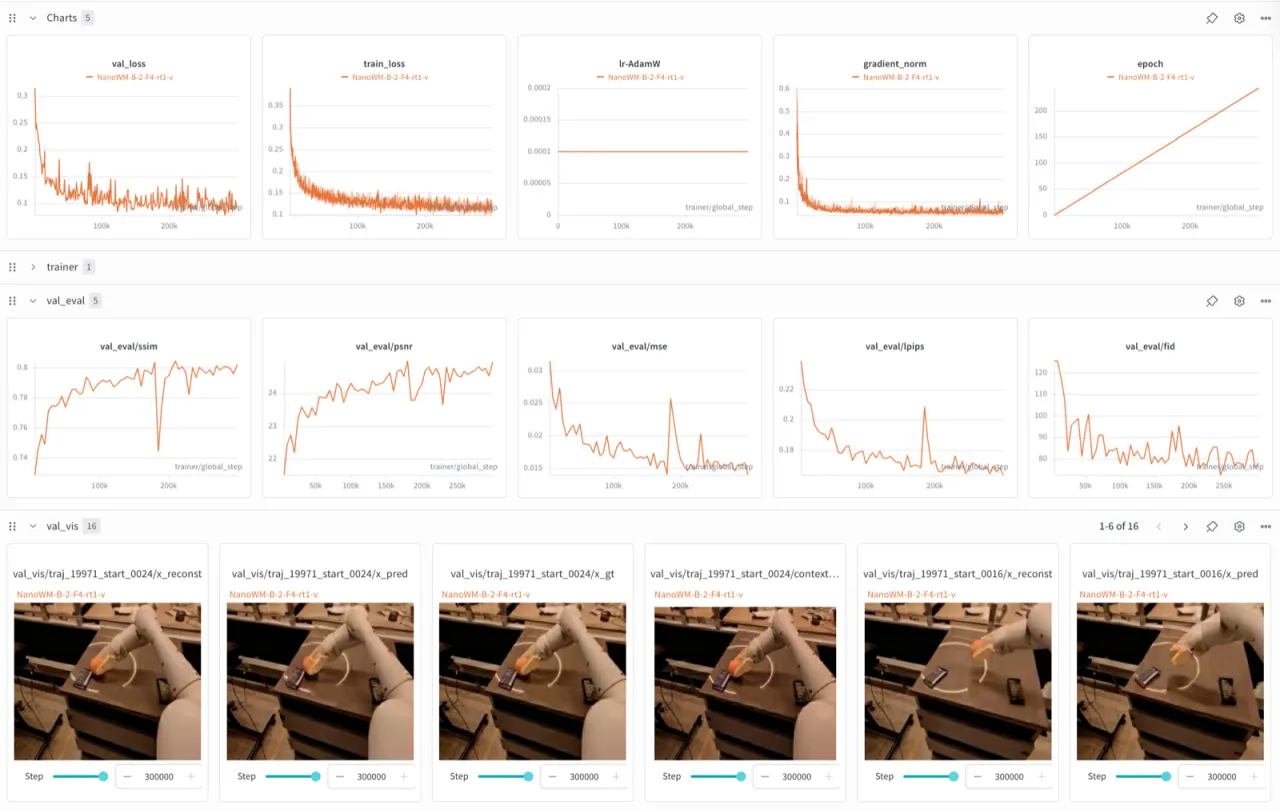
图 3:Weights & Biases 验证指标面板。 NanoWM 集成了 Tensorboard 和 W&B 日志,支持 PSNR、SSIM、LPIPS、FID 等指标的实时监控,辅助设计选择的系统比较。
消融实验总结
预测目标 :v-prediction 在感知质量(FID)最优;x-prediction 在像素保真度最优;ε-prediction 整体最差,差距显著(FID 差约 6–7 点)。模型规模 :从 S(39.8M) 到 L(~460M) 所有指标单调提升,规模效应清晰。动作注入 :无单一最优方法,任务依赖性强;additive 以最低参数量提供竞争性能。采样预算 :增加 DDIM 步数可持续改善 rollout 质量,对长程生成尤为重要。