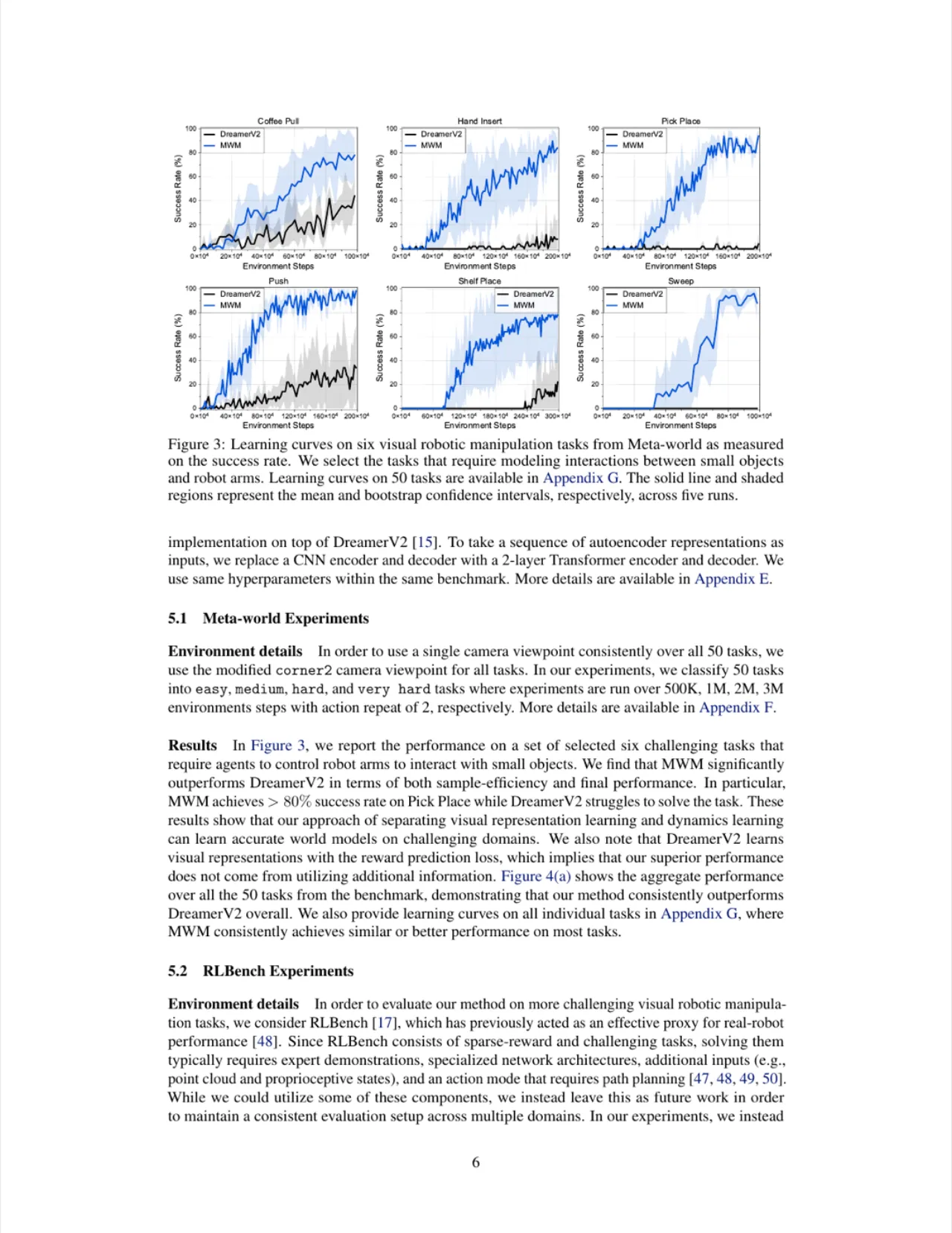
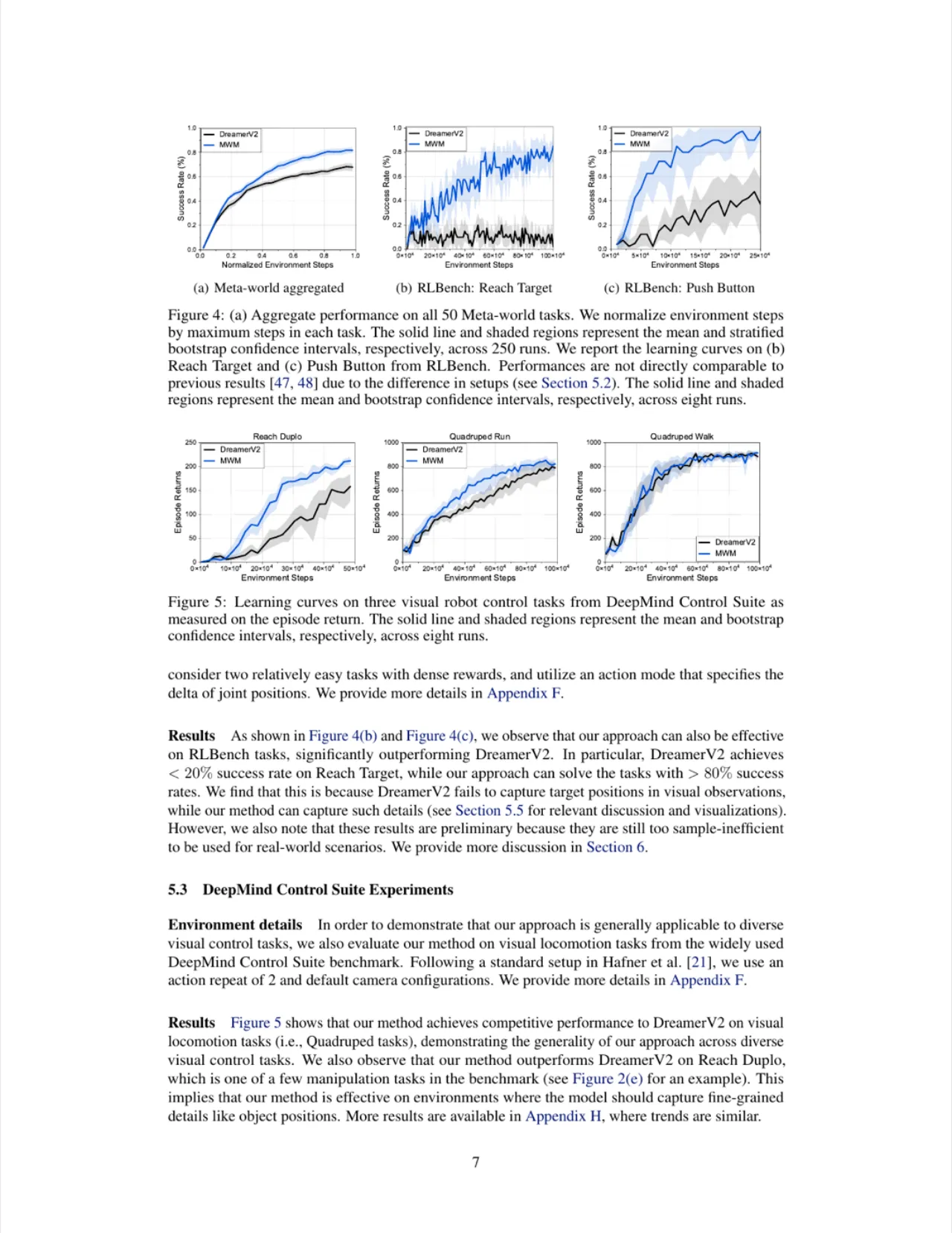
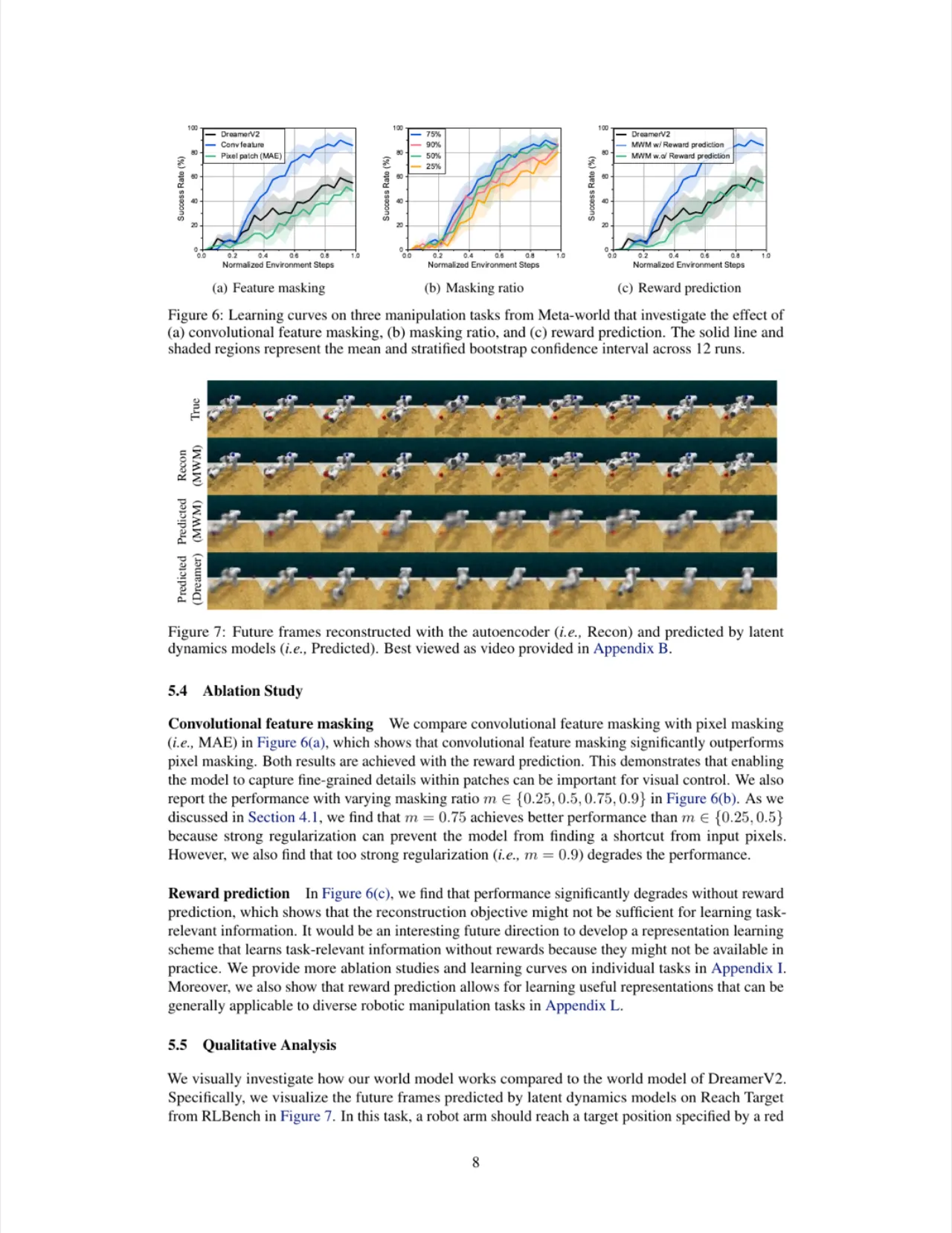
01 动机 Motivation
视觉模型强化学习(visual model-based RL)有潜力从视觉观测中实现高样本效率的机器人学习,但现有方法通常将视觉表征学习与动态建模端到端联合优化,难以准确建模机器人与小物体之间的交互。
"the current approaches typically train a single model end-to-end for learning both visual representations and dynamics, making it difficult to accurately model the interaction between robots and small objects."

81.7%Meta-world 50 任务成功率(MWM)
67.9%DreamerV2 基线成功率(同一基准)
>80%RLBench Reach Target 成功率(MWM)
<20%RLBench Reach Target 成功率(DreamerV2)
端到端优化在表征质量与动态准确性之间存在内在权衡:世界模型需同时负责"看清画面"和"预测未来",两者目标相互干扰。另一方面,类 MAE(masked autoencoder)的像素块掩码方式虽计算高效,但难以捕捉块内精细细节(如小目标位置),限制了其在视觉控制中的应用。MWM 正是为此而生。