01 动机
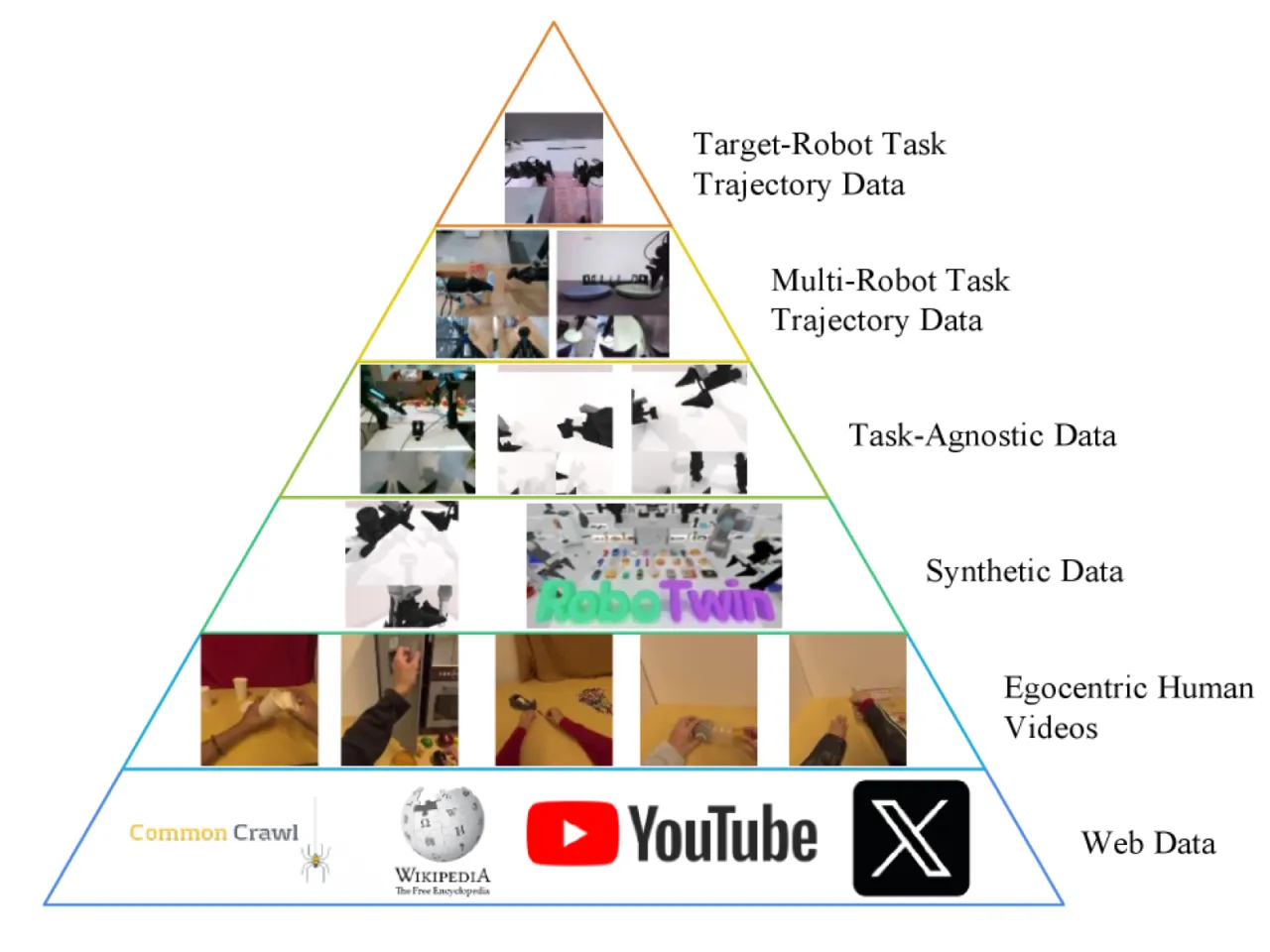
具身 AI 领域长期存在"能力碎片化"问题:VLA(视觉-语言-动作)模型、世界模型(WM)、逆动力学模型(IDM)、视频生成(VGM)、视频-动作联合预测五类能力分属不同模型,难以相互增益。此外,绝大多数视频数据缺乏动作标注,而机器人平台之间动作空间各异,导致大规模跨具身预训练十分困难。
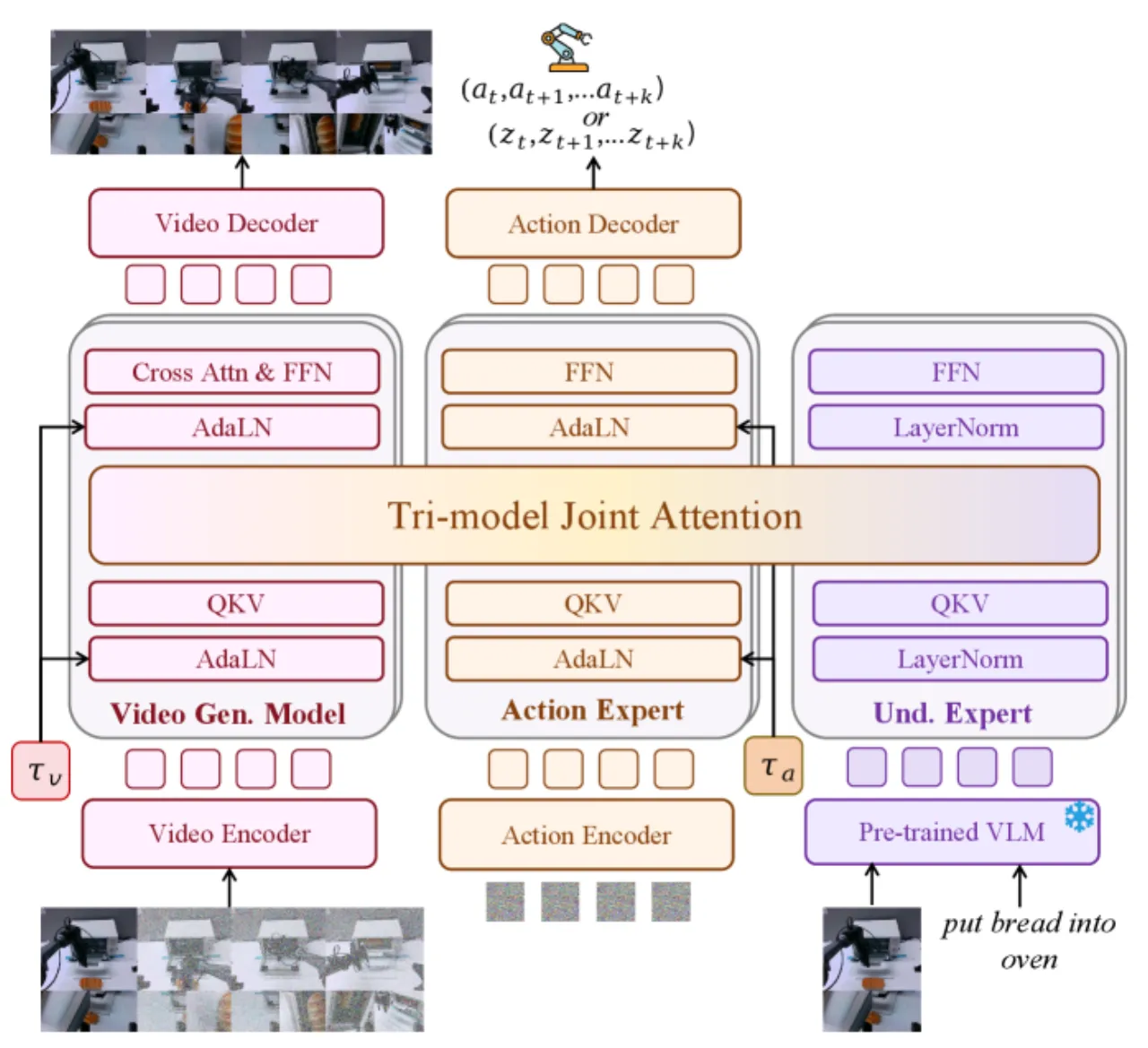
"We propose Motus, a unified world model framework that integrates five key embodied AI capabilities—VLA, WM, IDM, VGM, and video-action joint prediction—into a single model via a Mixture-of-Transformers (MoT) architecture."
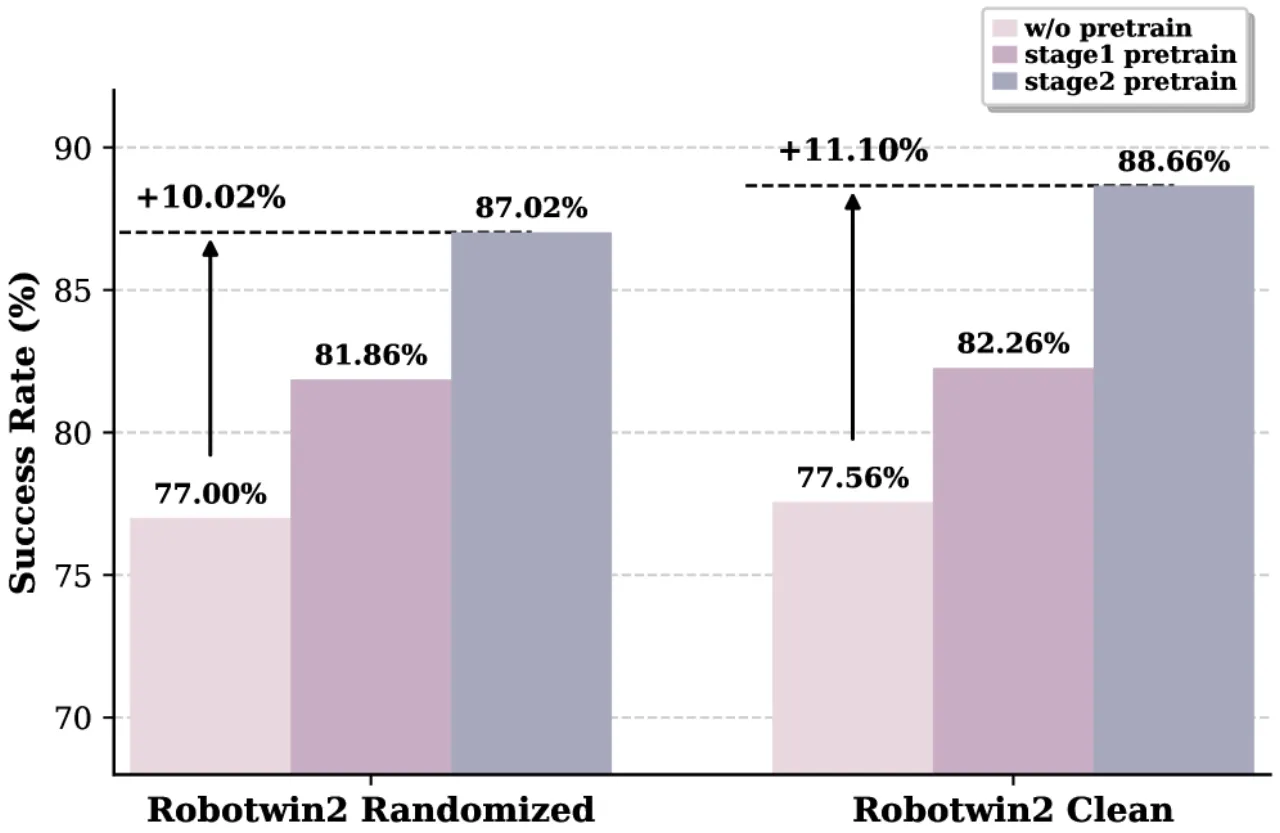
88.66%RoboTwin 2.0 仿真平均成功率(clean)
+15%超越 X-VLA(仿真)
+45%超越 π₀.₅(仿真)
+11~48%真实机器人平台提升幅度
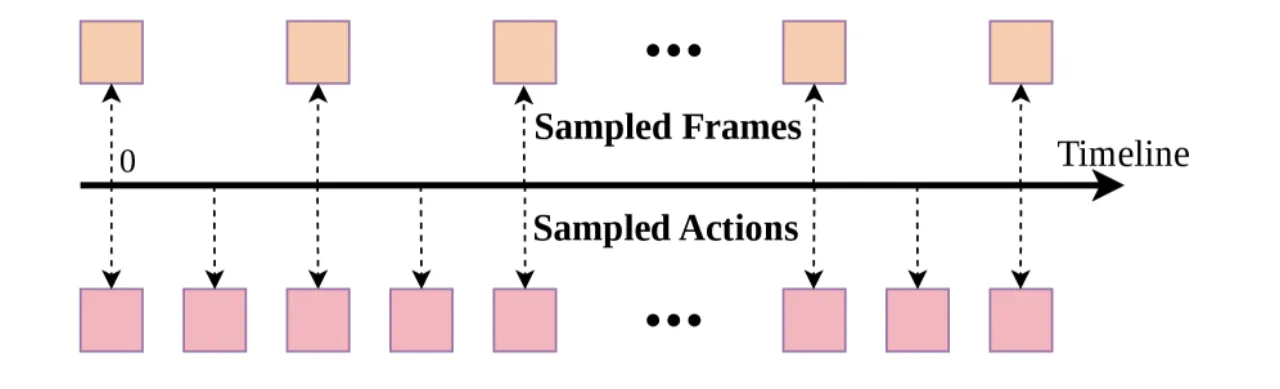
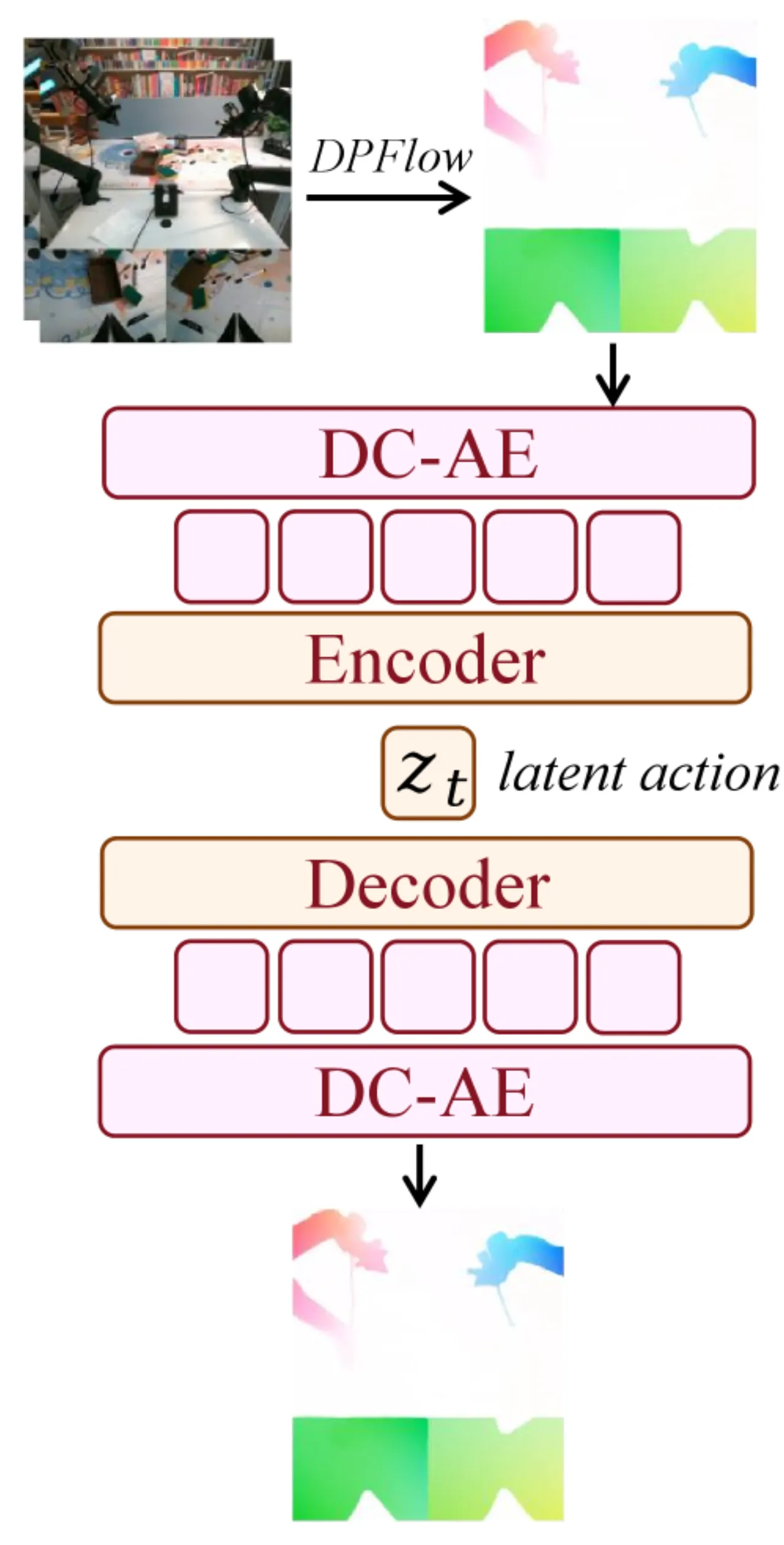
现有方法的核心痛点有两个:(1)如何在单一架构中统合多模态生成能力,同时不牺牲各专项功能;(2)如何在动作标注稀缺、具身差异显著的情况下利用海量异构视频数据。Motus 通过 optical flow 作为"通用运动代理"来绕过动作标注缺失的问题,用深度卷积变分自编码器(DC-AE)将光流压缩为 14 维的 latent action 向量,恰好匹配主流机器人控制空间维度,从而实现跨具身迁移。