"Frontier models are closed; open-weight alternatives are tied to expensive hardware; reasoning-augmented policies pay prohibitive latency for their grounding; and fine-tuned success rates remain below the threshold for dependable use."
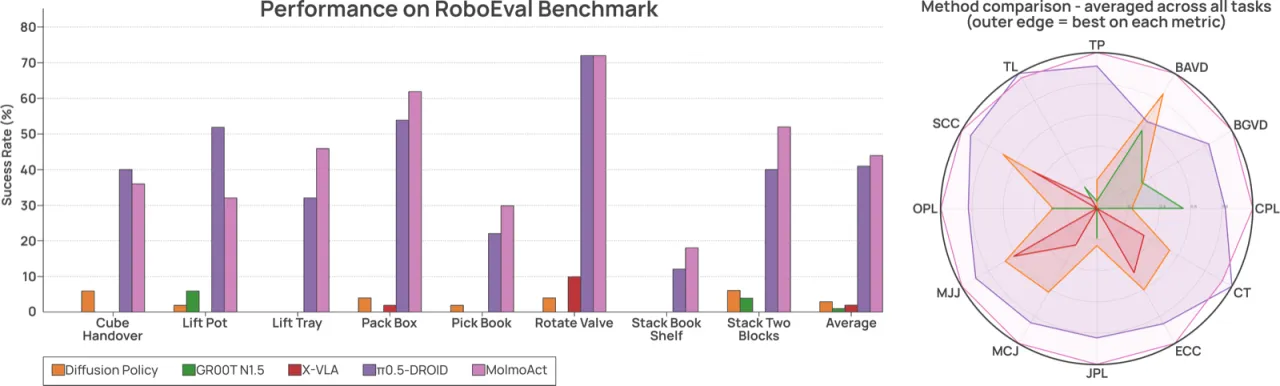
在 MolmoSpaces 基准的 Open(关节体交互)类别上,MolmoAct2-DROID 得分仅 9.5,明显低于 π₀.₅-DROID 的 22.7,表明"articulated-object interaction remains a direction for further improvement"(论文原文)。
空间泛化仍是薄弱项(stated)
在 OOD 鲁棒性评估中,MolmoAct2 在 Spatial Variance(空间位置超出训练分布)类别下的绝对成功率仅 26.25%,是四类扰动中最低的,表明细粒度空间泛化仍有提升空间(论文指出 "room for improvement on fine-grained spatial generalization")。