01 动机
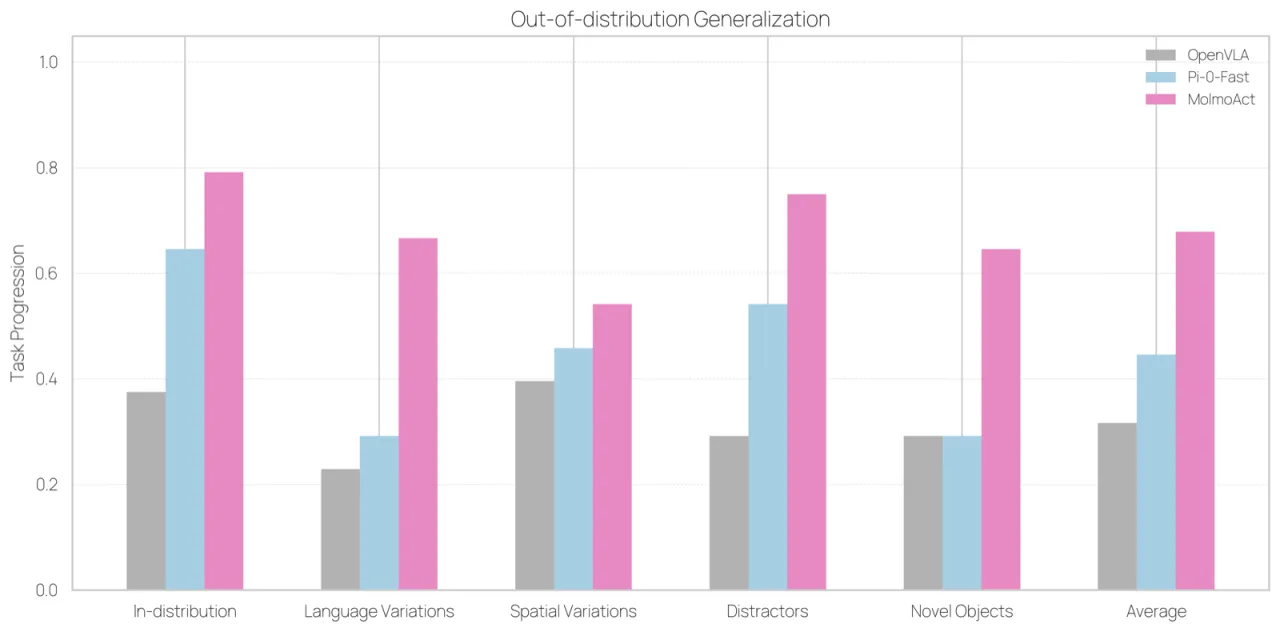
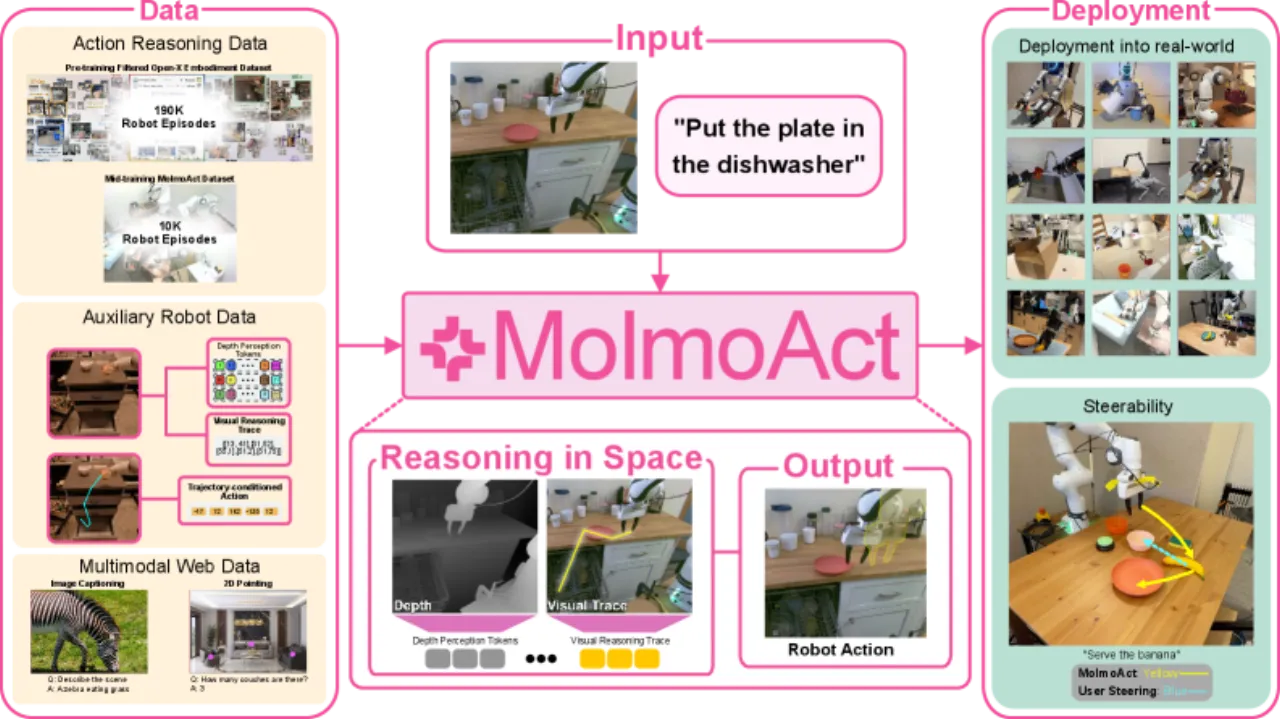
当前大多数视觉-语言-动作(VLA)模型将感知与指令直接映射到控制信号,缺乏中间推理步骤,导致适应性、泛化性和语义可解释性受限。论文指出,大语言模型从 chain-of-thought 推理中获益匪浅,而机器人学领域却鲜有类似结构。
"Reasoning is central to purposeful action, yet most robotic foundation models map perception and instructions directly to control, which limits adaptability, generalization, and semantic grounding."
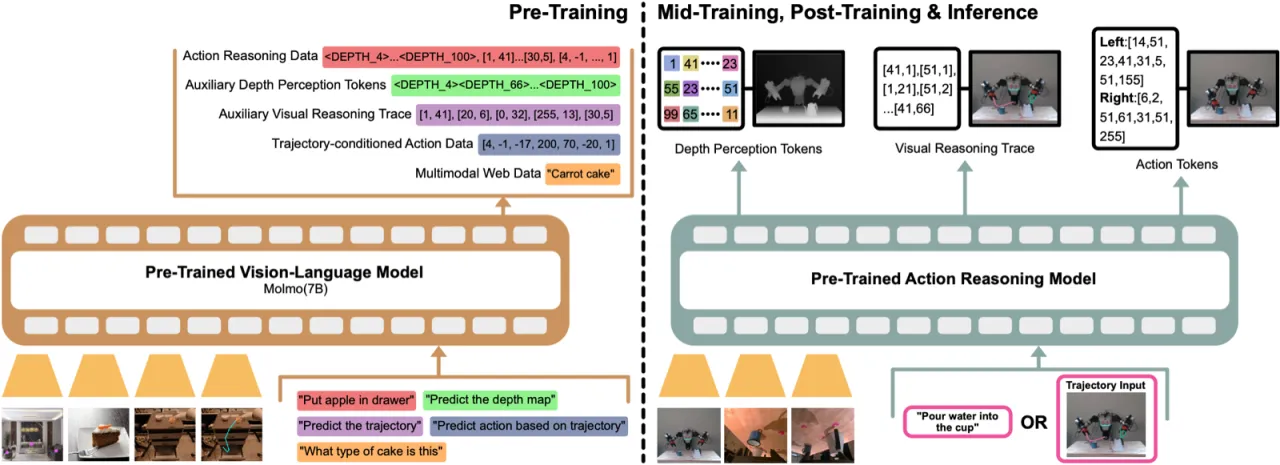
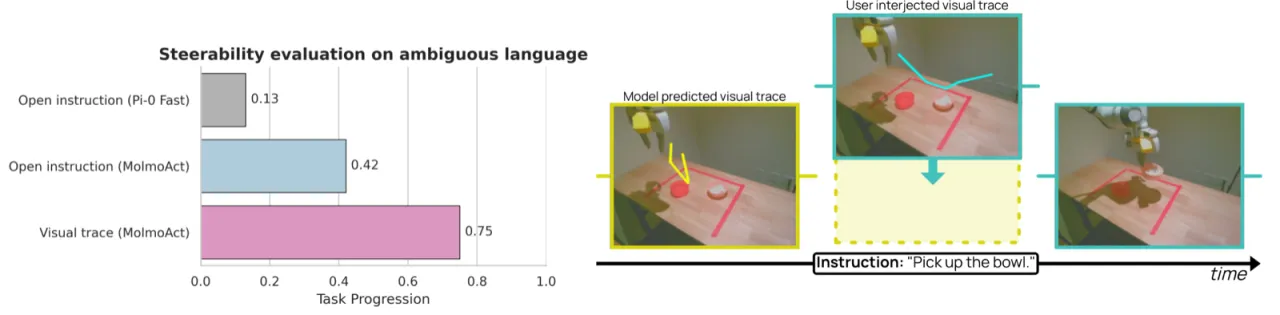
作者认为,机器人的推理应当「根植于空间理解」而非纯语言推理——轨迹、深度信息与物理空间才是机器人决策的真正基础。MolmoAct 的核心贡献是将这一理念落地:在自回归生成的同一 token 序列中,依次推断深度、轨迹与动作,实现可解释、可干预的行为。
70.5%SimplerEnv zero-shot
Visual Matching Avg
Visual Matching Avg
86.6%LIBERO 平均成功率
(4 类任务)
(4 类任务)
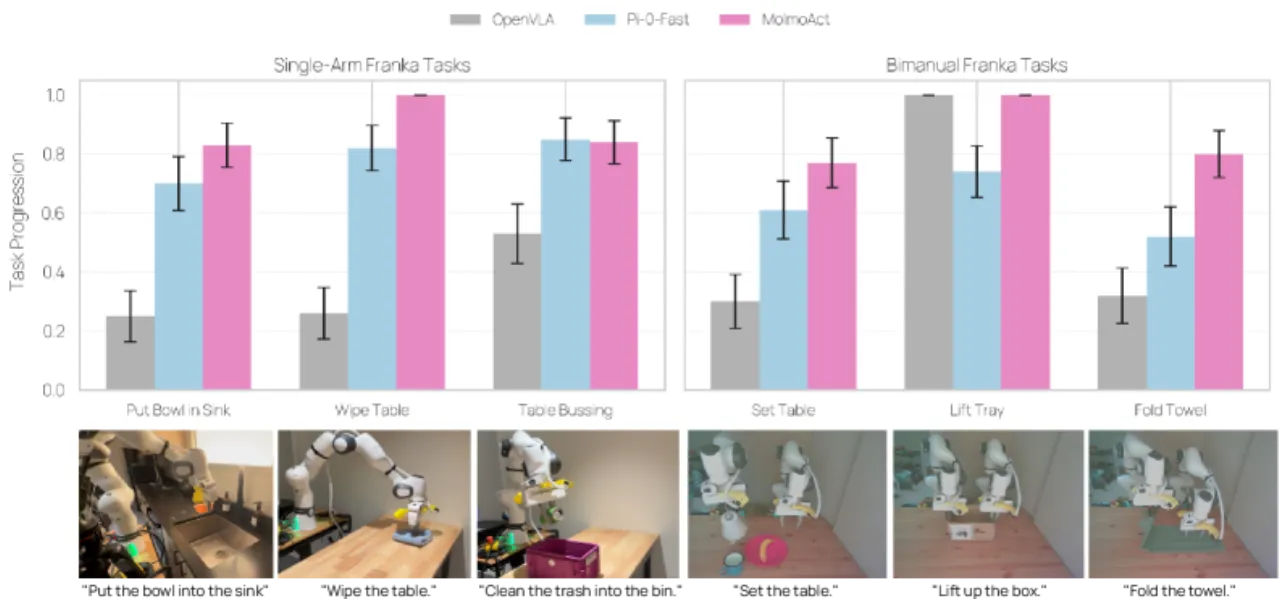
+22.7%双臂操作超越
π₀-FAST
π₀-FAST
10,689MolmoAct Dataset
真实轨迹条数
真实轨迹条数