01 动机 Motivation
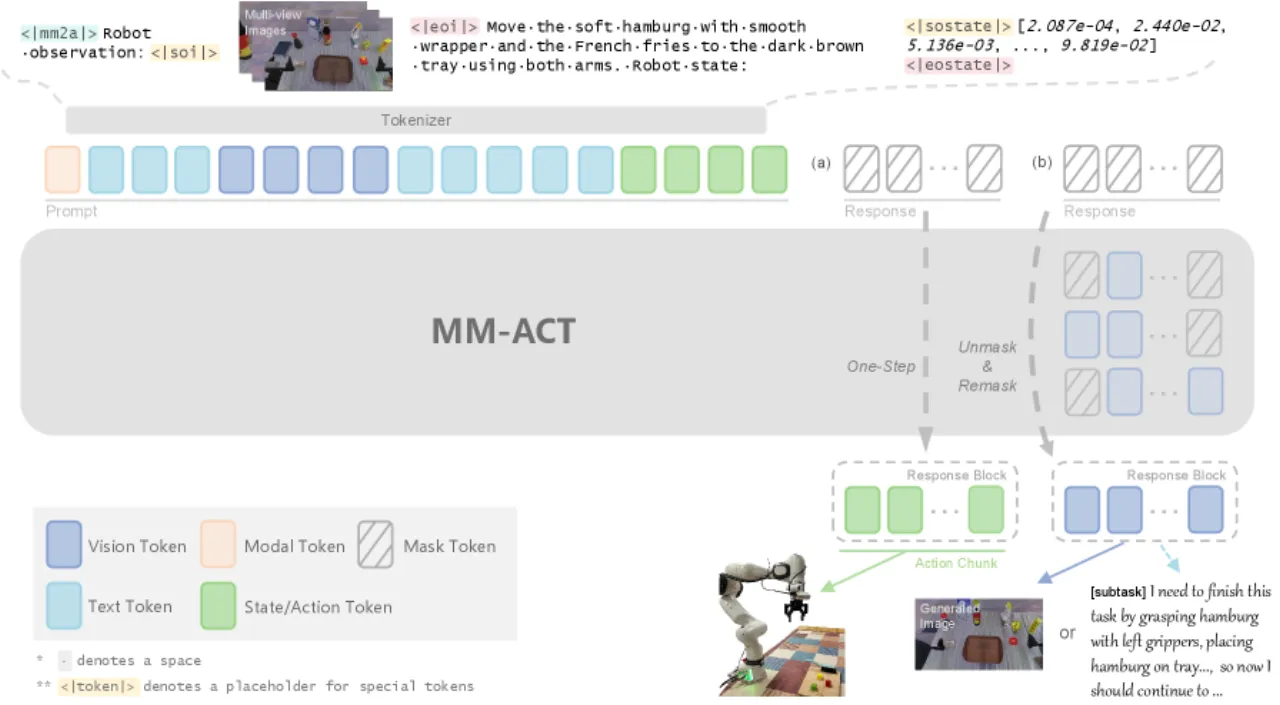
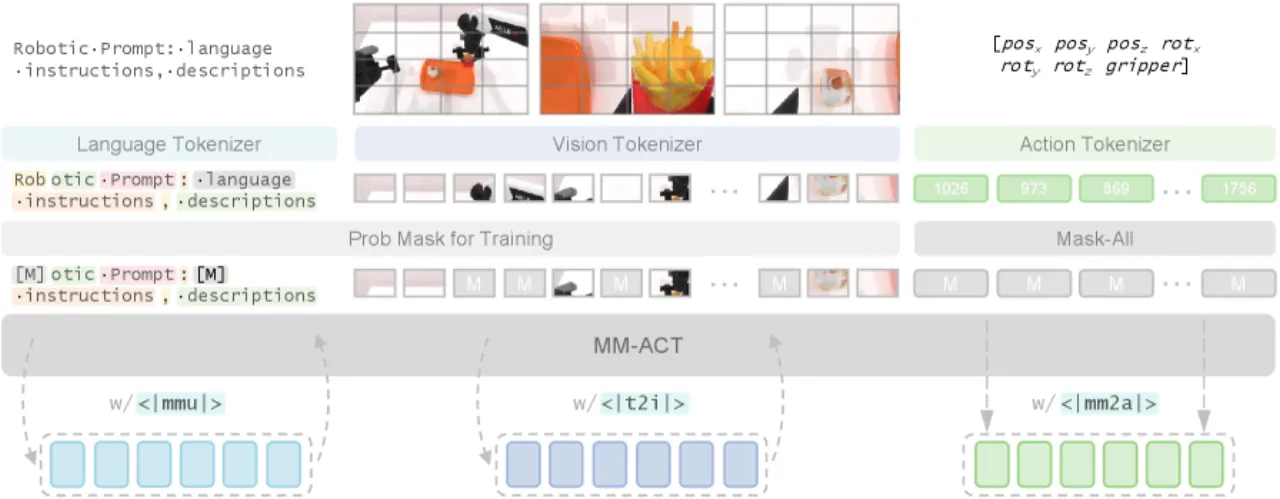
通用机器人策略需要同时具备语义理解(任务规划)与环境交互(动作预测)两种能力,但现有方法往往将二者分离处理,难以充分利用多模态信号之间的互补关系。
"A generalist robotic policy needs both semantic understanding for task planning and the ability to interact with the environment through predictive capabilities."
96.3%LIBERO 平均成功率
72.0%Franka 真实机器人成功率
52.38%RoboTwin2.0 双臂任务成功率
+9.25%跨模态学习带来的额外增益
现有方法的不足
- 单模态辅助训练:许多 VLA 仅将视觉或语言生成作为辅助任务,缺乏统一的多模态生成框架。
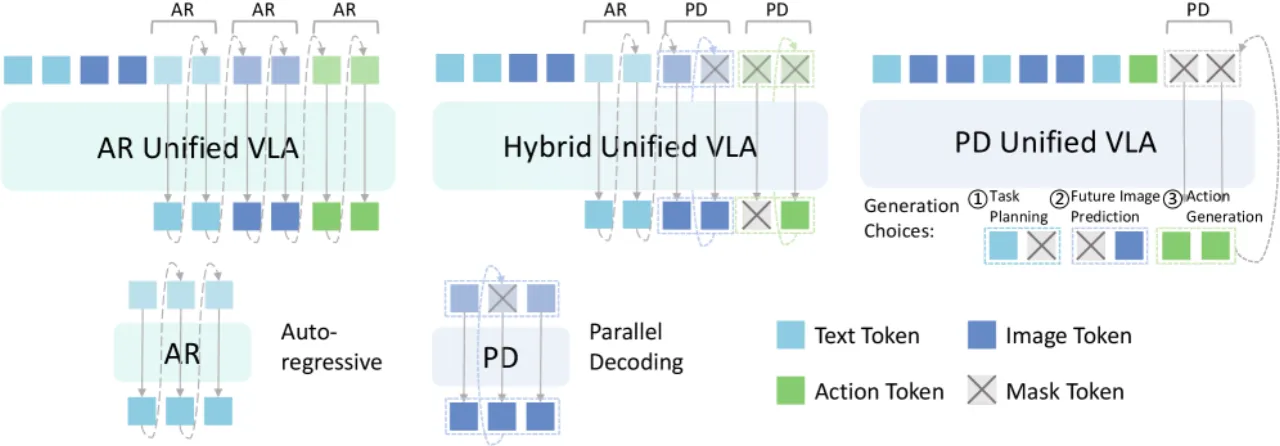
- 自回归解码效率低:逐 token 的自回归动作解码在 40 Hz 实时控制场景下瓶颈明显。
- 跨模态上下文未充分利用:文本描述与图像预测对动作生成的潜在增益未被系统挖掘。