01 动机
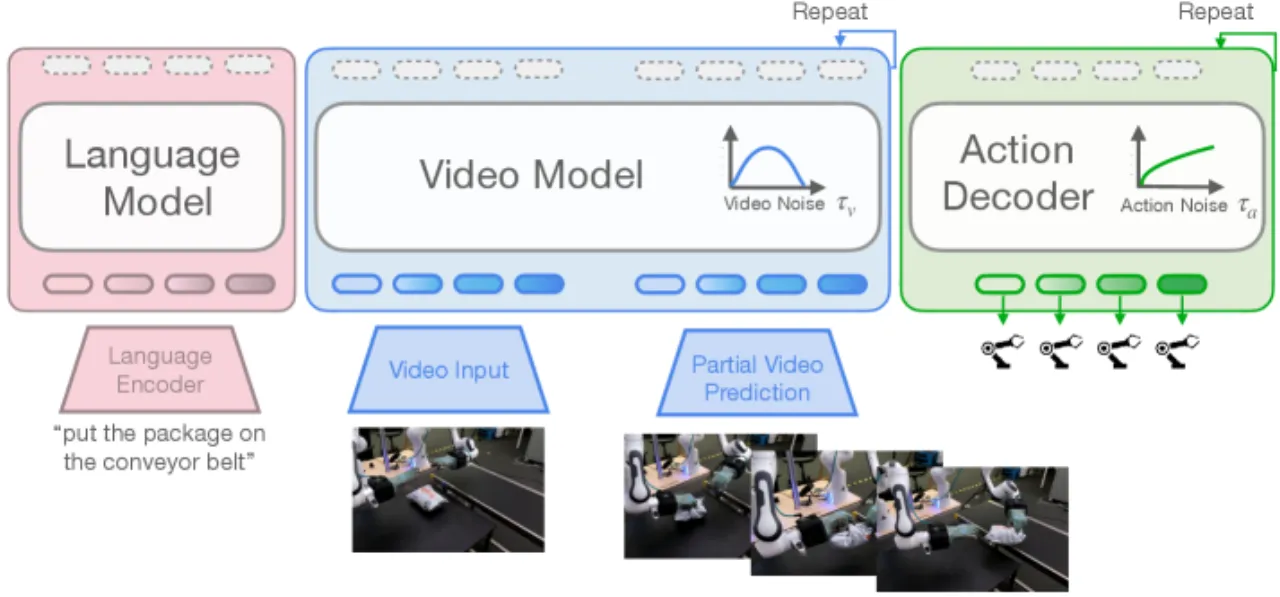
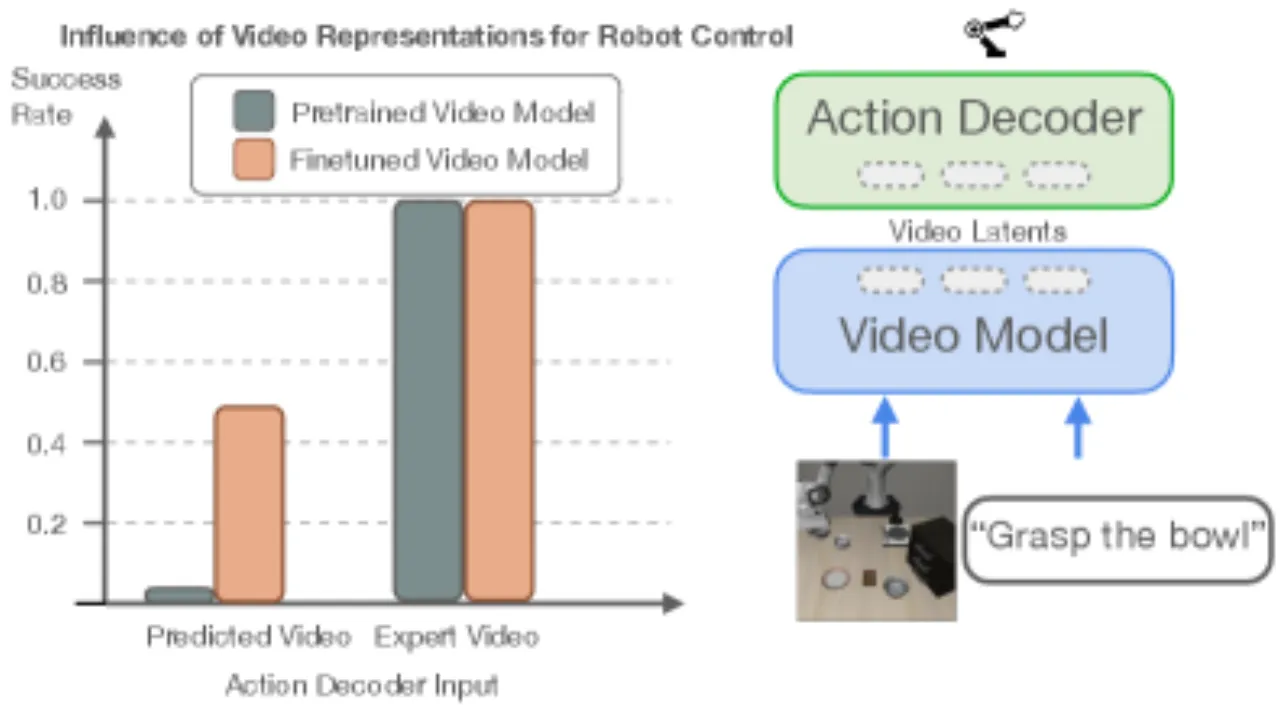
当前主流 VLA 模型将视觉-语言预训练迁移到机器人控制,但其预训练数据(互联网图文) 本质上是静态的,无法捕捉物理世界的时序动态。这意味着机器人的物理理解能力必须完全从 稀缺且昂贵的机器人演示数据中从头学习。
"the pretraining data, while massive in scale, is inherently static." — 作者的核心出发点:用视频模型天然编码的时序动态替代静态视觉-语言预训练。
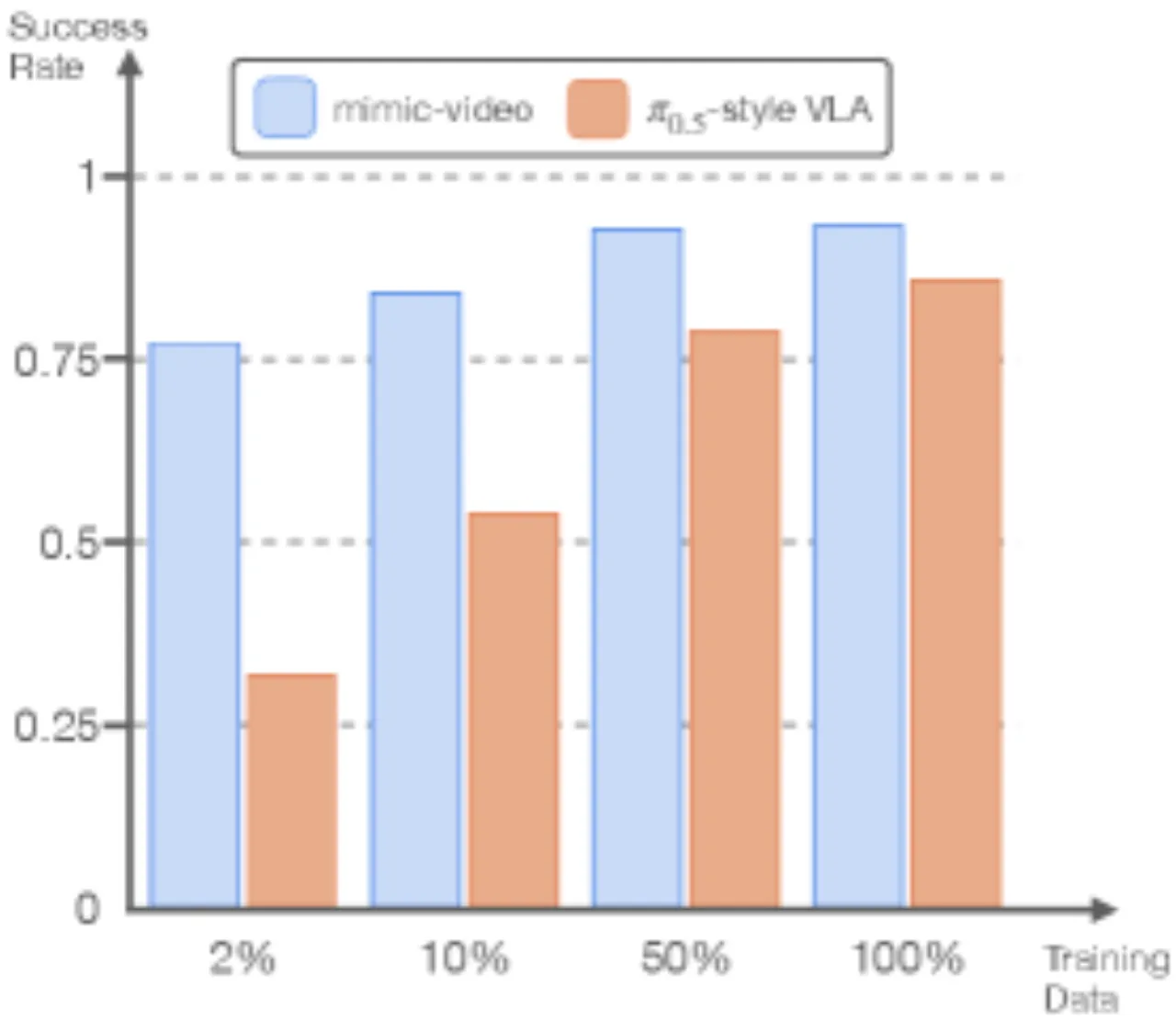
10×样本效率提升
vs. VLA baseline
vs. VLA baseline
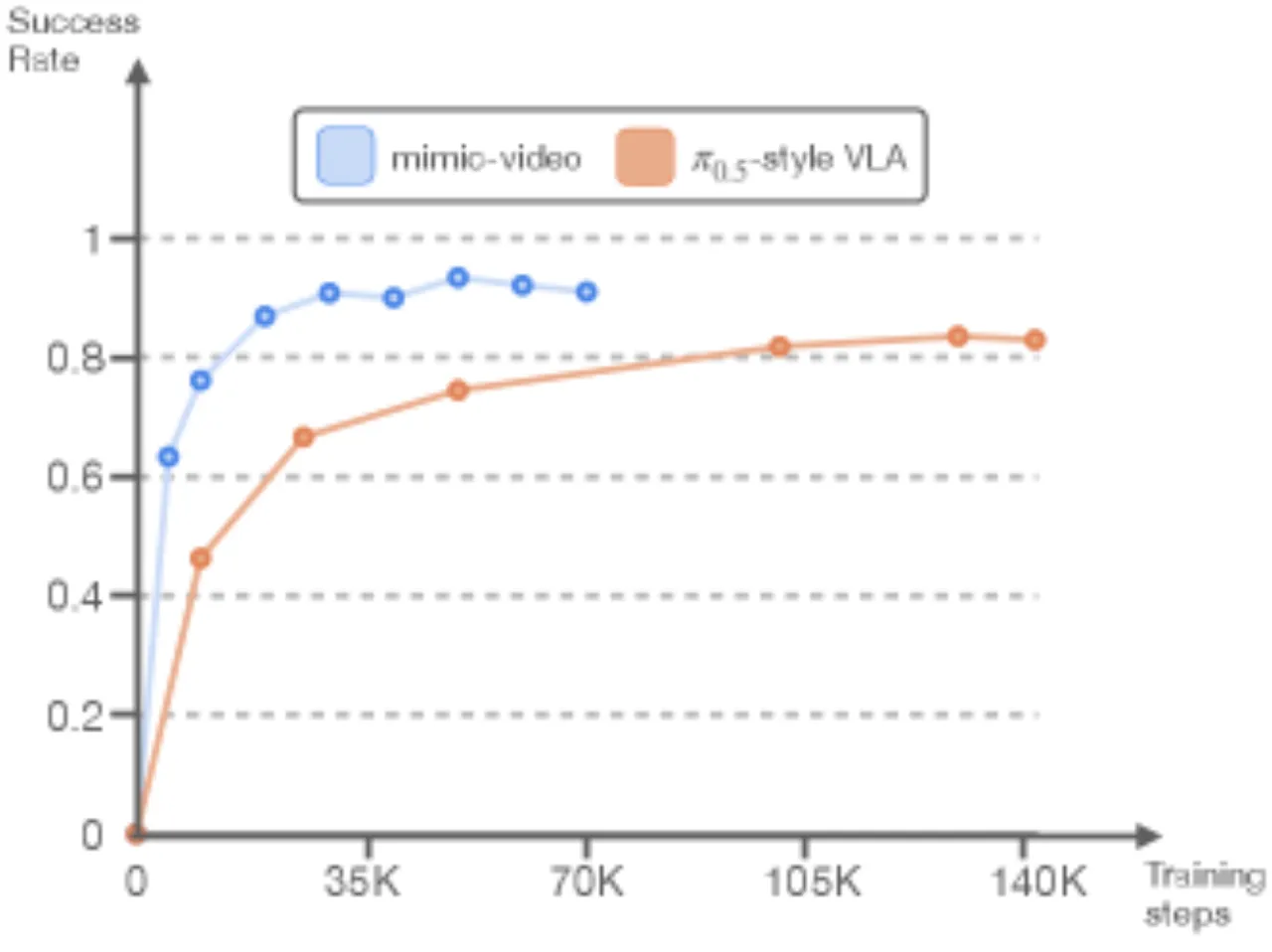
2×收敛速度加速
vs. VLA baseline
vs. VLA baseline
56.3%SIMPLER-Bridge 平均成功率
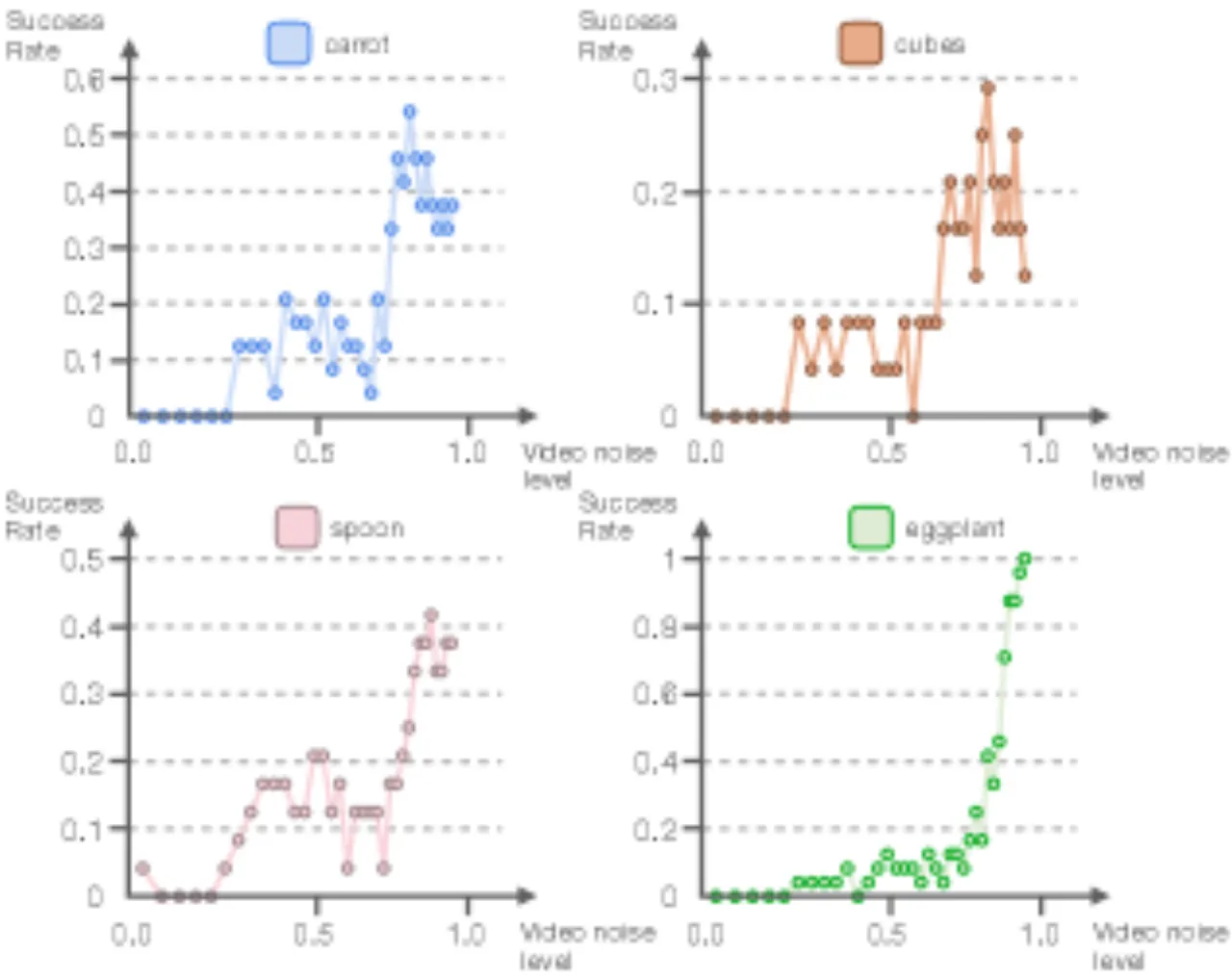
(per-task τᵥ 设置)
(per-task τᵥ 设置)
93%真实双臂抓取
Package Handover 成功率
Package Handover 成功率