01 动机
灵巧手操作是迈向通用机器人的关键一步,但大规模带动作标注的灵巧操作数据极为稀缺。人类手部动作数据虽然规模庞大、场景多样,却存在视觉外观与机器人差距大、数据格式不统一等挑战,导致现有 VLA 模型难以直接利用。
"The bottleneck of scarce large-scale action-annotated dexterous manipulation data… Human data offers vast scale and diverse manipulation behaviors, [but] prior work faces limited scenarios and large visual gap between human and robots."
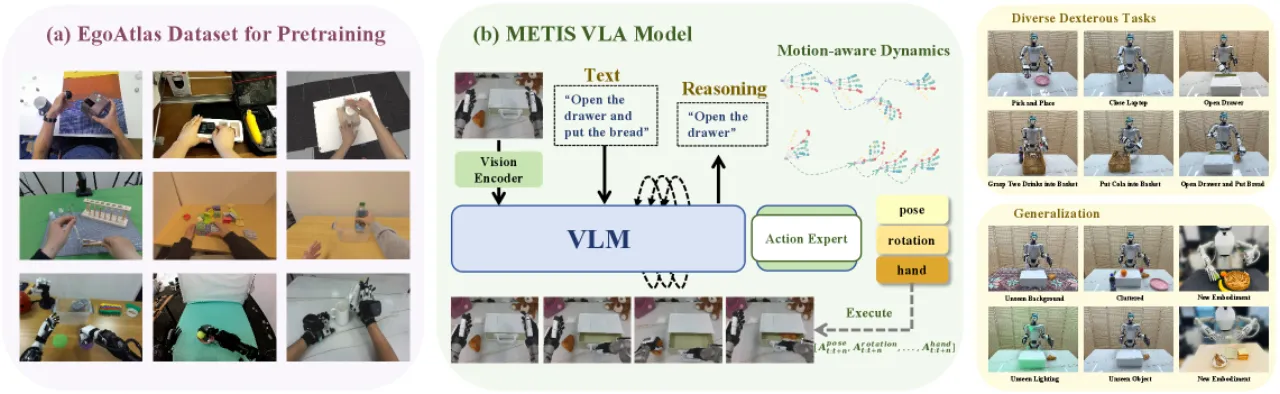
343KEgoAtlas 轨迹总数
89.72M图像-动作对总量
8数据来源(人类 + 机器人)
6真实世界灵巧任务
与仅依赖单一机器人数据的方法相比,METIS 的核心洞察是:将人类手部操作数据与机器人遥操作数据在统一动作空间下对齐,能显著提升模型的泛化能力。这一思路类比于大语言模型的预训练范式——先在海量异构数据上学习通用表征,再在下游任务上微调。