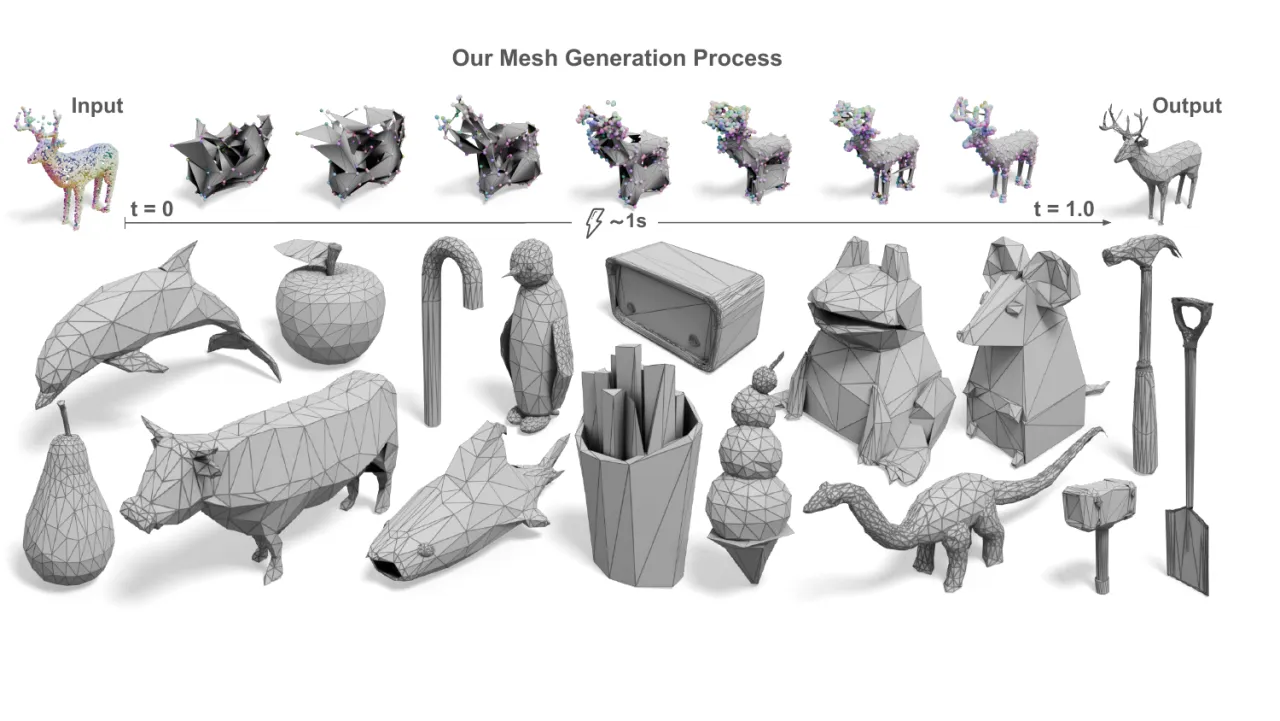
02 方法 MethodMeshFlow 由两个核心模块串联而成:MeshVAE (将离散网格压缩为连续隐向量)和 Flow-based Diffusion Transformer (在隐空间并行去噪生成)。
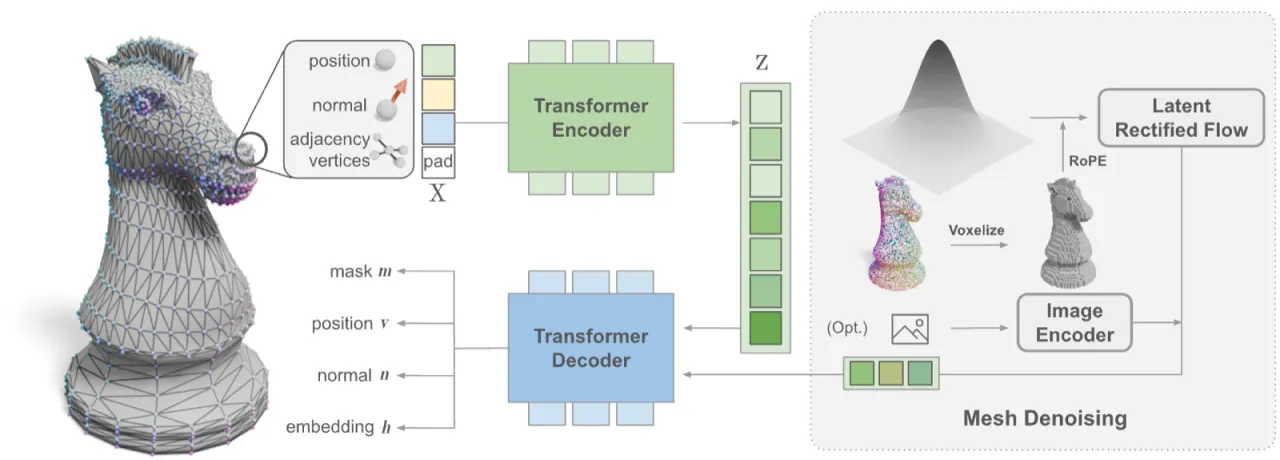
Figure 2 (方法总览). MeshFlow 将顶点位置、法线以及离散的 adjacency 关系一同编码进 MeshVAE 的连续隐空间;Flow-based DiT 对所有 latent token 并行去噪;最后由 Mesh Decoder 恢复出顶点、法线与完整的网格连通性。
网格表示(Mesh Representation)
一个三角网格 M 可以表示为顶点集 V = (v₁, …, vₙ) 和面集 F。MeshFlow 不直接对面进行编码,而是对边(edges) 编码。若排除三角边环退化情形,面 F 可由边集 E 完整恢复。核心创新在于:借鉴 SpaceMesh 的思路,用每个顶点的连续 edge embedding eᵢ ∈ ℝᴰ 来隐式表达 adjacency:两顶点间距离 d(eᵢ, eⱼ) ≤ τ 则判定存在边。此外,每个顶点还携带一个 outward normal nᵢ 用以恢复面的方向。因此,整个网格被表示为三元组 (v, n, e),全部为连续量,彻底避免了面 token 的离散化。
顶点比面更紧凑 :网格通常拥有 2–3 倍于顶点数的面,因此顶点级别的表示天然比面级别的 tokenizer 更短,压缩比显著更优。
MeshVAE — 连续隐空间压缩
MeshVAE 的目标是将网格的三元组 (v, n, A) 压缩至低维连续隐向量 z,再从 z 解码出 (v̂, n̂, ê, m̂)。
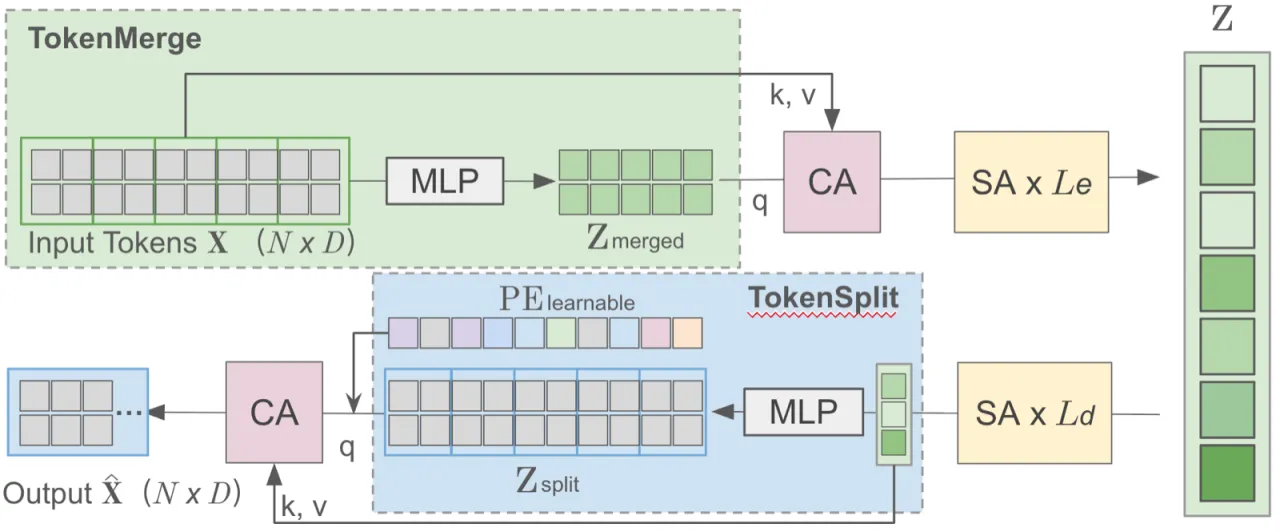
Figure 3 (MeshVAE 详细结构). Encoder 先对顶点与法线做 Fourier Positional Encoding,再通过 TokenMerge (类似 pixel-shuffle 操作)将 N 个顶点 token 下采样为更少的 latent token n < N,随后经 Cross-Attention 和多层 Self-Attention 得到 latent z。Decoder 对称设计:SplitToken 将 n 个 latent 映射回 N 个位置,输出顶点、法线、edge embedding 与 mask。
Encoder :对每个顶点拼接位置、法线的 Fourier PE 及其邻居坐标;TokenMerge 下采样;Cross-Attention + Self-Attention 得到 latent z。Decoder :SplitToken 将 latent 映射回 N 个 token;Cross-Attention + learnable Positional Embedding 输出 (v̂, n̂, ê, m̂)。训练损失 :顶点与法线 MSE + 顶点 mask BCE + 对比学习 adjacency loss (正边拉近 embedding 距离,负边推开)+ KL 正则。TokenMerge 关键性 :对比 Q-Former(随机初始化可学习 query)和 FPS(最远点采样),TokenMerge 才能保证训练收敛和高保真重建(edges F1 = 99.78 vs Q-Former 的 49.47)。
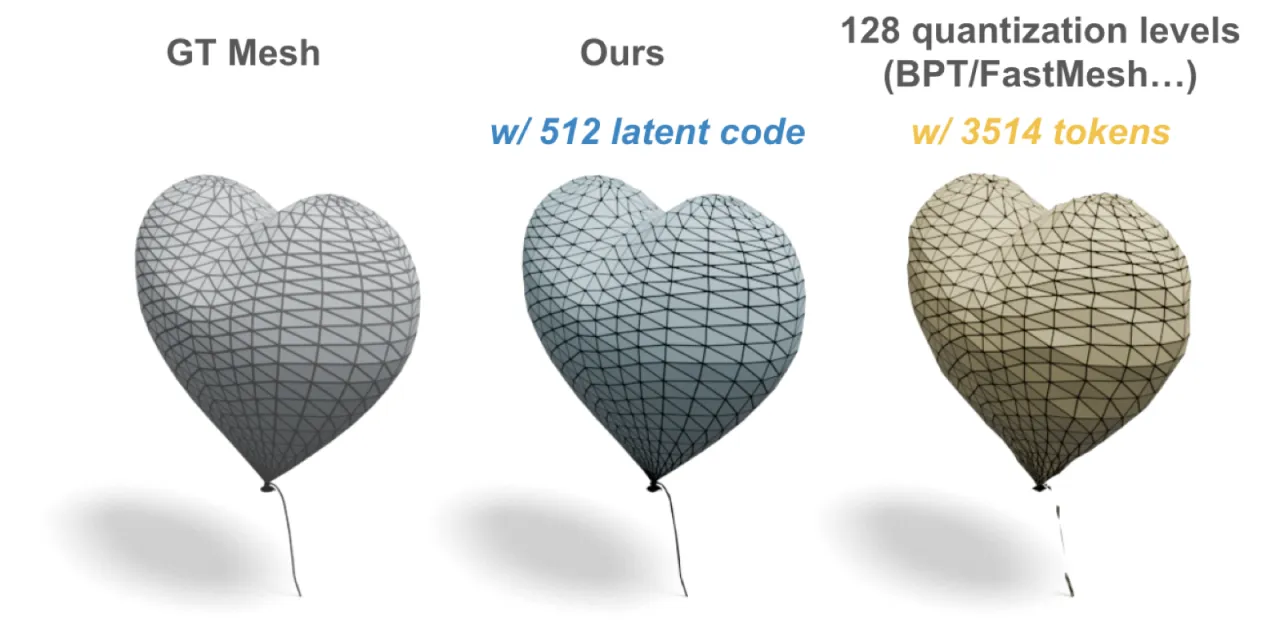
Figure 4 (VAE 对比). AR 方法必须对坐标做量化(128 级),导致精细几何细节丢失。MeshVAE 在连续空间重建,忠实保留了输入网格的精细纹理与拓扑。
Flow-based Diffusion Transformer(Mesh Generation)
生成阶段采用 Rectified Flow (RF) ,其直线 ODE 公式避免了路径交叉、最小化时间步离散误差。模型训练目标为 Conditional Flow Matching (CFM):
"v_θ(RoPE3D(x_t, c_vox), t) → (ε − x₀)"
条件生成中,输入点云先做体素化,再通过 3D RoPE 位置编码与噪声 latent 融合,同时将顶点数量拼入时间 embedding 作为全局条件。DiT 采用 18 个 Transformer block、1024 维隐层,共 427M 参数;MeshVAE 的 encoder/decoder 各 8 层、1024 维,共 233M 参数。推理时还采用 Flash Attention + BF16 混合精度加速,并使用 EMA 提升稳定性与泛化。
训练末期引入 logit-normal timestep 采样(借鉴 SD3),推理时采用 timestep shifting 3.0 ,促使模型在生成阶段更关注精细几何细节。
对于生成结果的后处理:检测 boundary edge(仅属于一个三角面的边),若 k < 5 的边环则自动三角化修补,增强生成结果的鲁棒性。