01 动机
当前 VLA(Vision-Language-Action)模型通常针对单一任务或单一机器人形态进行微调,难以扩展至多技能通才场景。 模型合并(model merging)是一种无需重新训练即可整合多个专家知识的技术, 但直接将多个 VLA 专家合并会导致几乎为零的成功率,根本原因在于两类不可合并性。
"directly merging VLA experts trained on different tasks results in near-zero success rates."

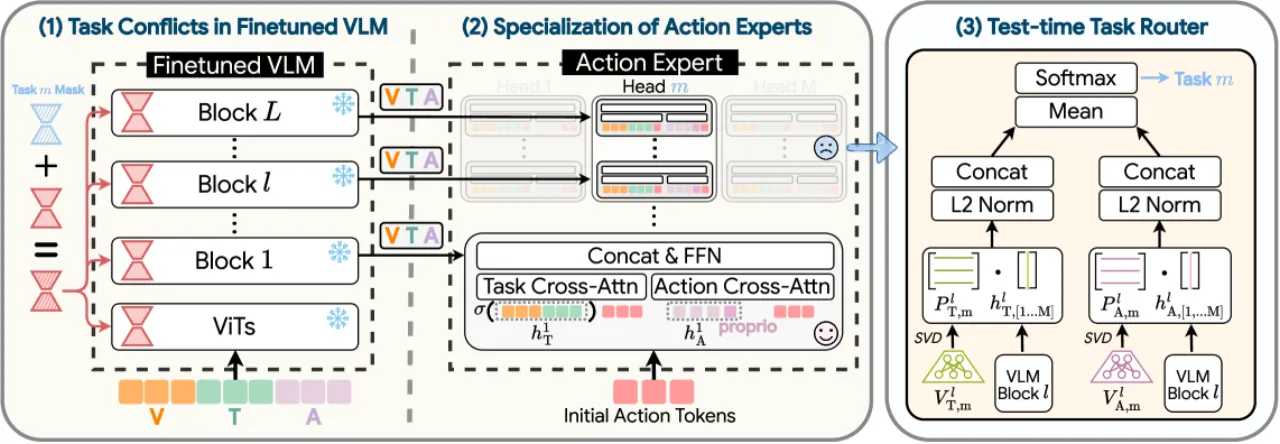
问题一:LoRA 参数干扰
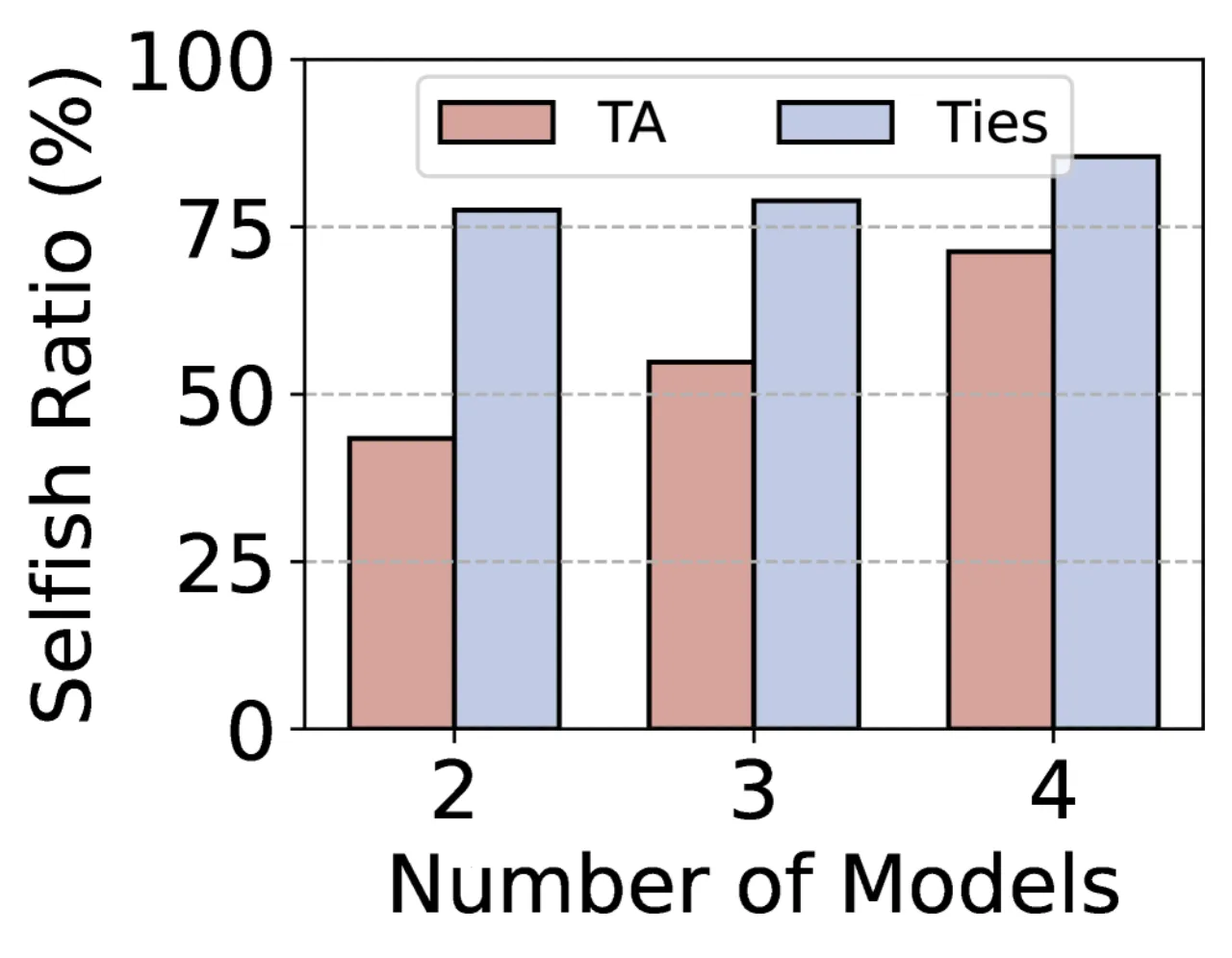
不同任务的 LoRA 微调更新激活了几乎互不相交的参数子集。 分析显示,超过 75% 的参数是"自私的"(selfish)——仅与一个任务相关, 直接合并时这些参数会互相干扰,导致性能崩溃。
问题二:Action Expert 架构不兼容
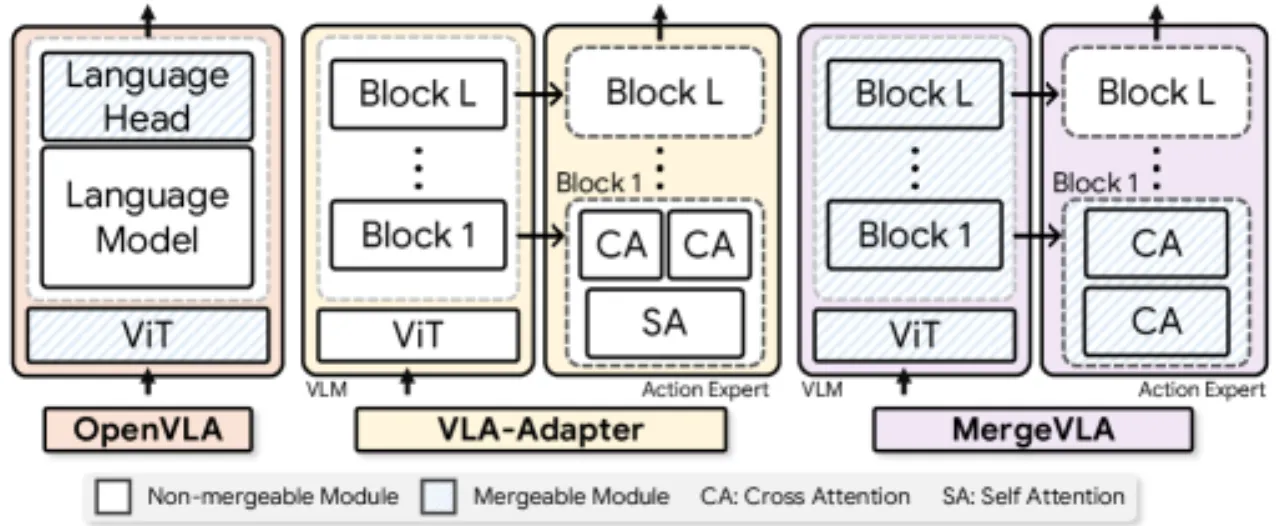
传统 VLA-Adapter 中 action expert 含有 self-attention 层, 训练过程中不同任务的 self-attention 会在各层之间积累任务特定的依赖关系(inter-block dependencies), 导致合并后信息混乱、难以区分任务。
~0%直接合并 VLA-Adapter 的成功率
75%+参数为"selfish"(仅属于单一任务)
90.2%MergeVLA 合并后 LIBERO 平均成功率
90%真实 SO-101 机械臂平均成功率