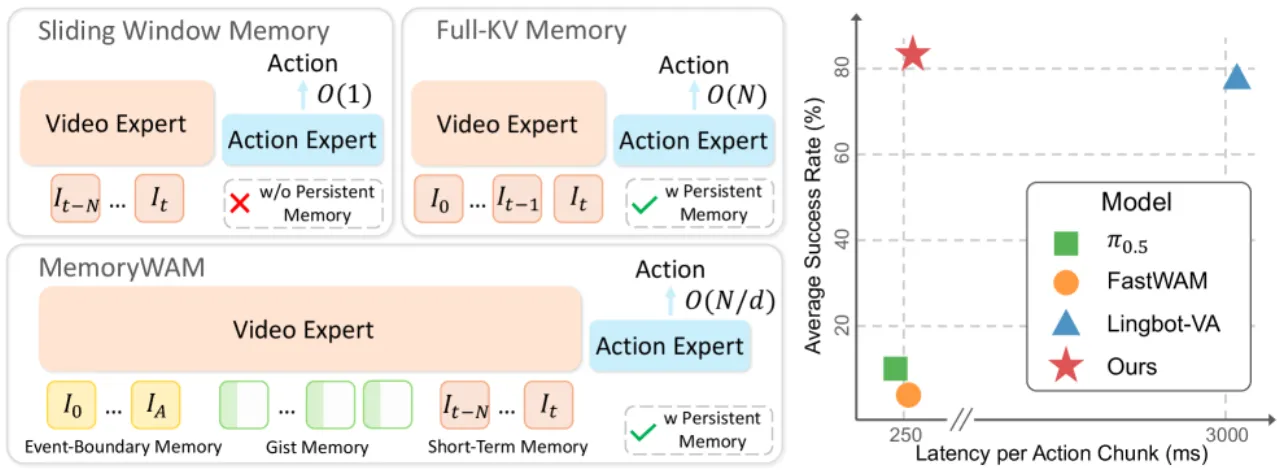
"Existing WAMs face a fundamental trade-off: methods with efficient inference typically condition only on a bounded window of recent observations and therefore struggle in non-Markovian environments, whereas methods that preserve long histories incur time and space costs that grow substantially with sequence length."
MemoryWAM 以 Mixture-of-Transformers (MoT) 架构为主干,将 video DiT(视觉动态建模)与 action DiT(动作预测)双路并行,并引入三层混合记忆机制,通过定制化注意力掩码实现高效持久上下文检索。
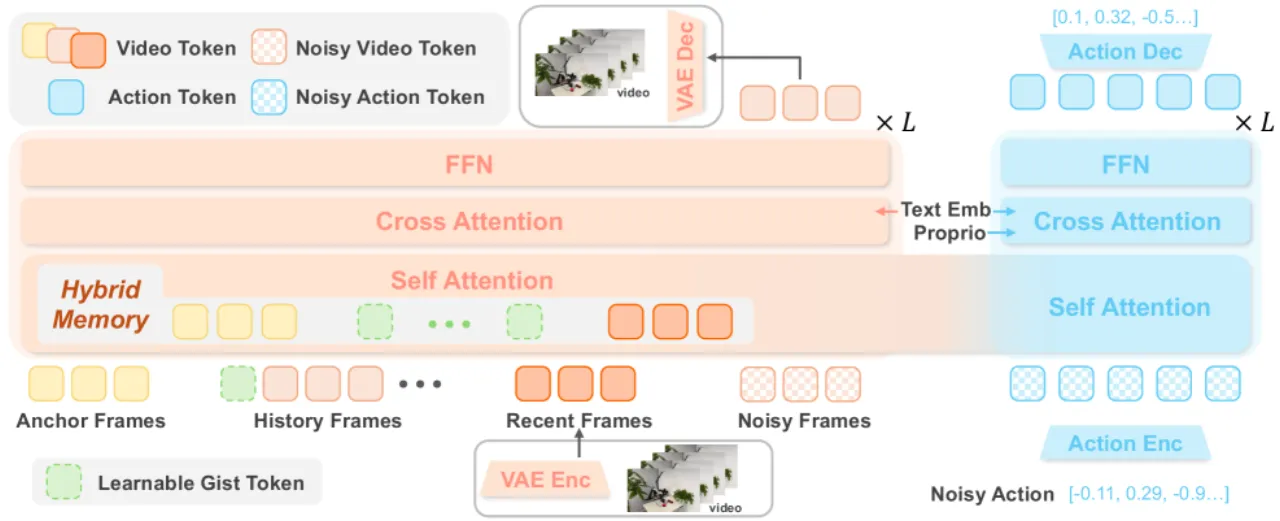
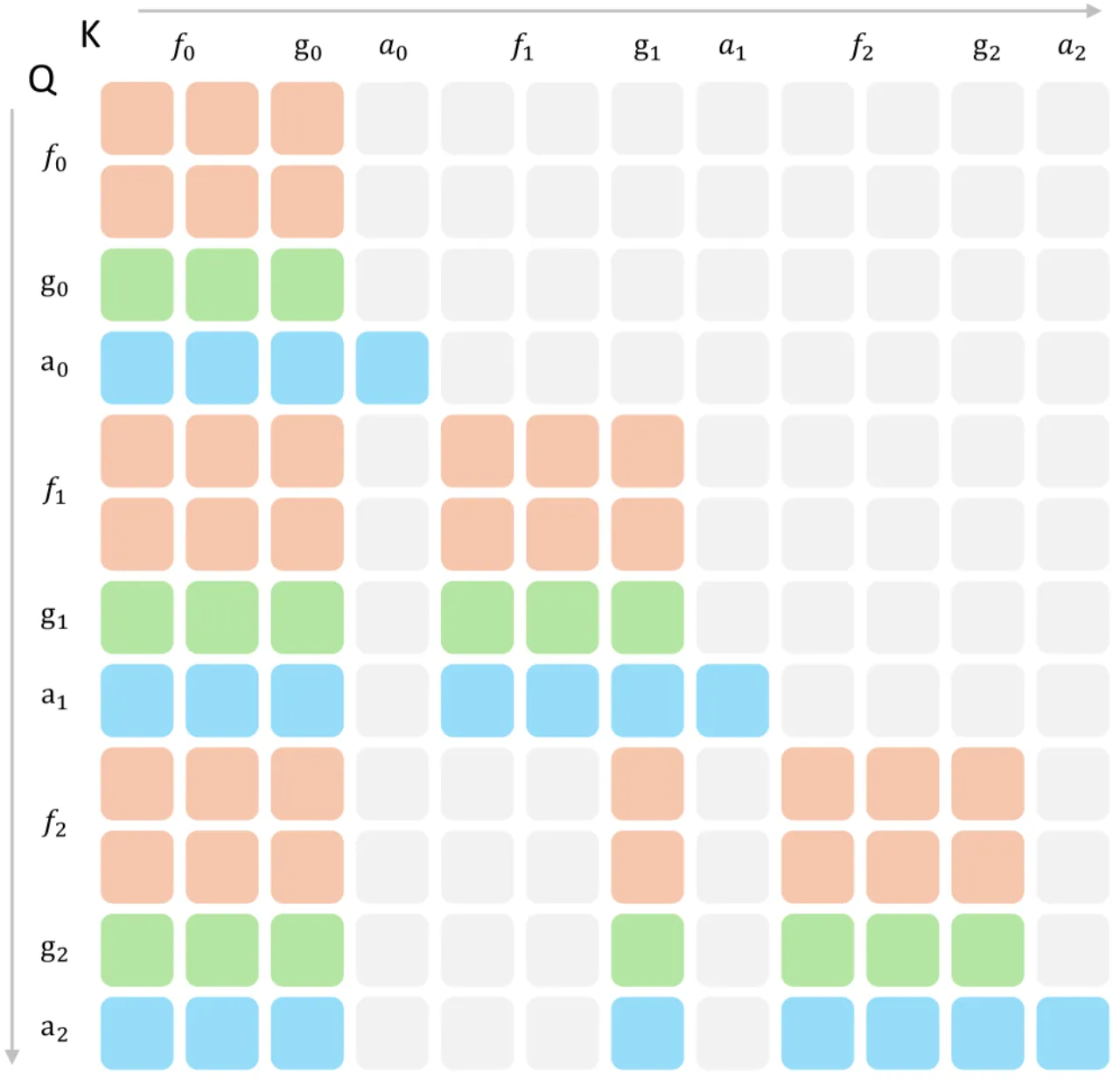
Figure 2 · 系统架构。MemoryWAM 由 video DiT (Φ_v) 与 action DiT (Φ_a) 构成 MoT 架构。训练时 video DiT 通过视频预测提供稠密监督;推理时仅前向一次当前帧更新 KV 缓存,无需生成未来帧。持久记忆保留初始锚帧的完整 token 与最近帧,并将长程历史压缩为少量 gist token。
混合记忆(Hybrid Memory)三层设计
短期记忆:Sliding Window
保留最近 N 帧的完整视觉 token,为当前动作规划提供高保真短期上下文。计算量固定为 O(N)(N 为滑窗大小,而非轨迹长度)。
Figure 5 · 真实世界任务示意。左:Shell Game——人手随机交换杯子后,机器人需识别藏有方块的杯子并抓取(需追踪遮挡物体)。右:Look and Press——机器人观察桌上两个数字,依次按对应次数的按钮,最后按下确认键(需计数工作记忆)。
任务
π₀.₅
LingBot-VA
Ours
Shell Game
5/20
13/20
18/20
Look and Press
0/20
14/20
15/20
真实机器人上 MemoryWAM 两项任务均最优。值得注意的是,LingBot-VA 高推理延迟导致其在 Shell Game 中错过杯子交换时机而失败——印证了效率本身也是操作性能的组成部分。
消融实验(Table 3)
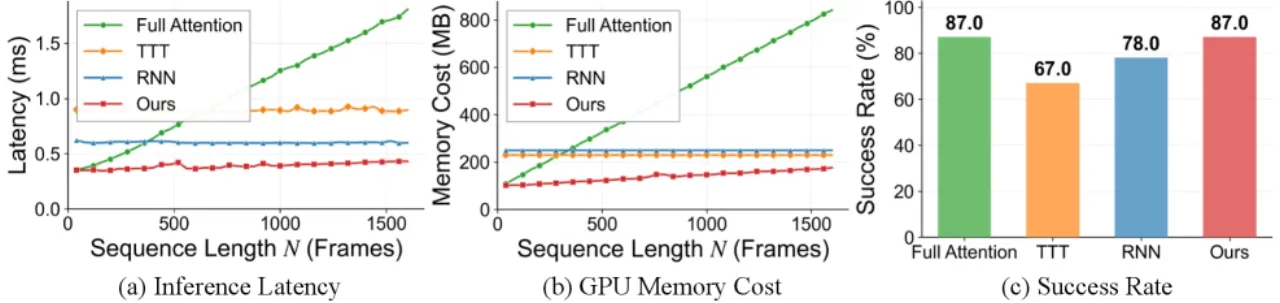
去除 gist token 导致最大性能下降,说明长程历史压缩是记忆依赖决策的核心。去除锚帧或滑窗均降低性能,证明三类记忆提供互补收益。Full Attention(保留所有历史)性能反而弱于混合记忆,说明"密集历史并非最优"——冗余信息增加检索难度。消融结论:"MemoryWAM's hybrid memory design is not merely an efficiency-oriented compromise, but an effective memory structure."
04 Limitations
Note: 本文无显式 Limitations 章节。以下局限性:前两点为论文结论/方法设计中直接推断(inferred from design),第三点基于实验规模。
压缩比 d 是固定超参数(inferred)
gist token 压缩比 d 在训练前固定,无法自适应任务难度或历史重要性动态调整。对于信息密度不均匀的轨迹,固定压缩可能导致部分关键帧被过度压缩或欠压缩。
锚帧选择依赖任务边界先验(inferred)
当前方案以任务初始帧作为锚帧("initial observations of a task"),需预先知道任务开始时刻。对于无明确起点或多阶段混合的连续操作场景,锚帧定义可能不够通用。
真实机器人实验规模有限(stated via experiment size)
真实机器人实验每任务仅 20 次 rollout,演示数据分别为 50(Shell Game)和 100(Look and Press)条。样本量相对较小,泛化性结论需更大规模验证。