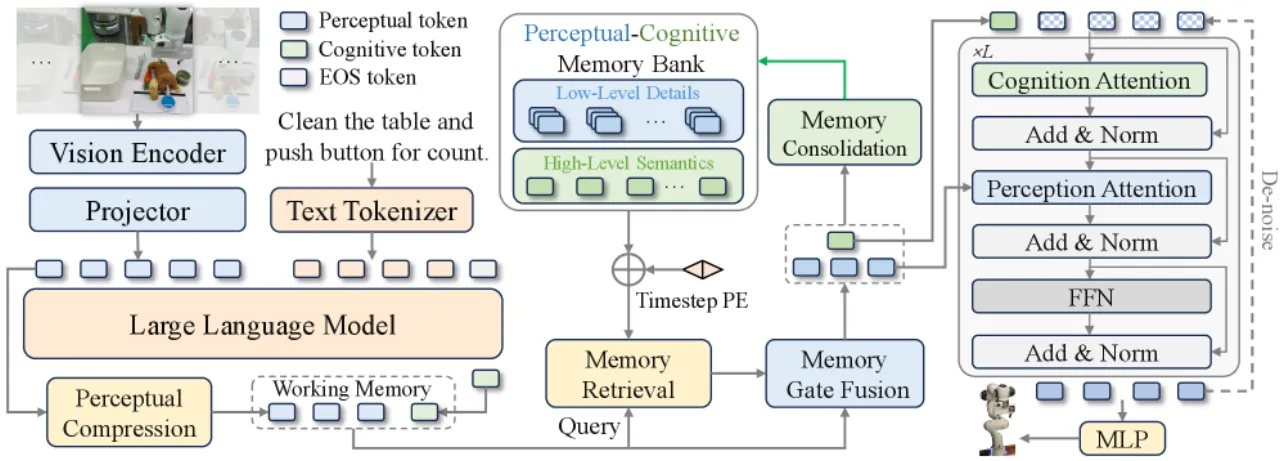
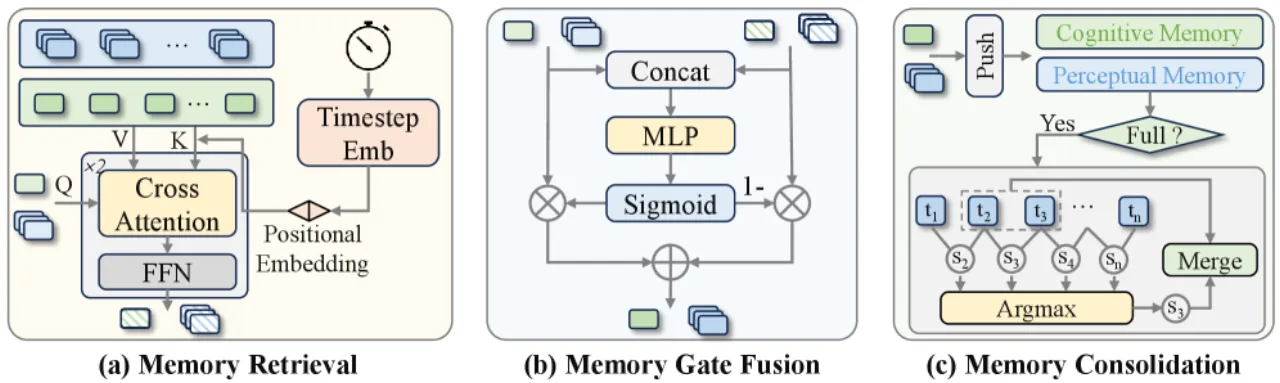
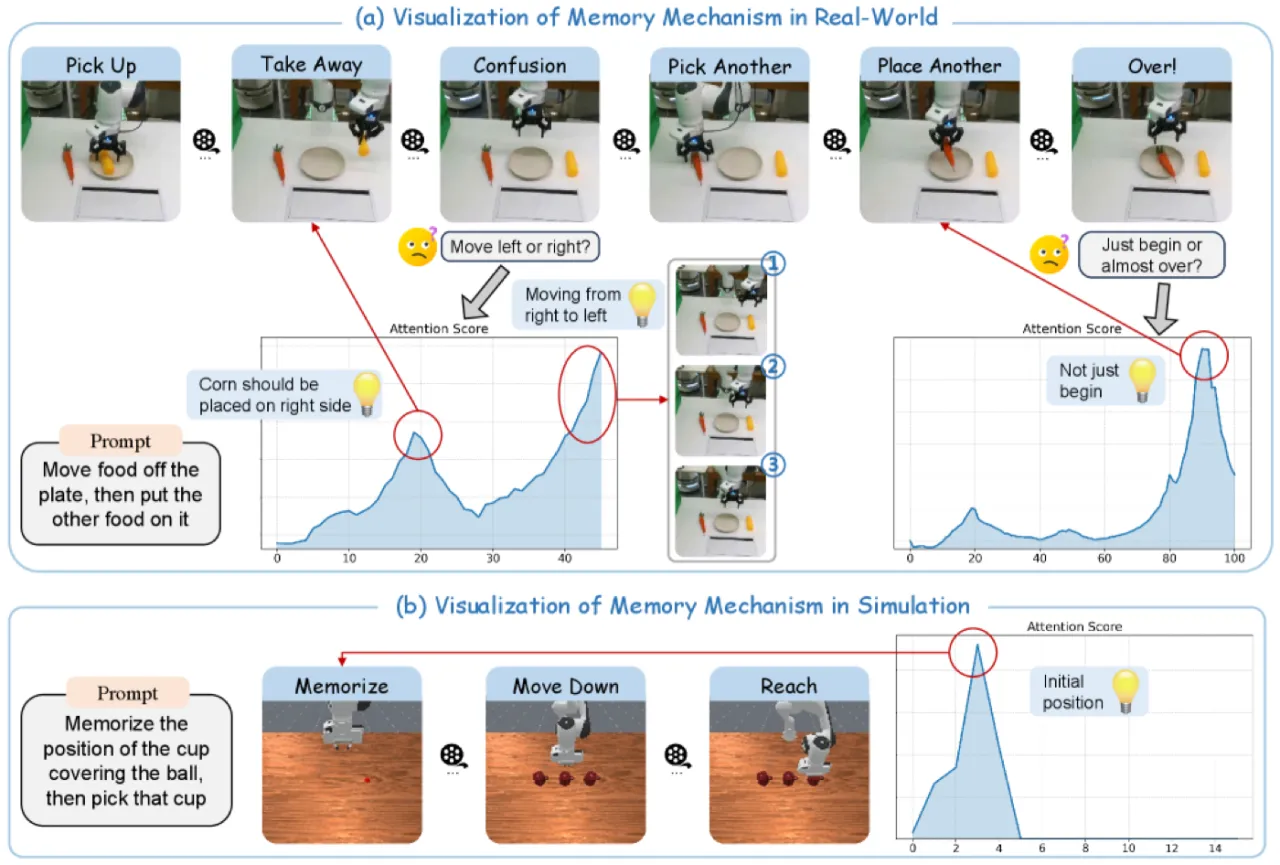
01 动机
机器人操作天然具有非马尔可夫性:早期动作决定后续状态,单帧观测往往不足以完成任务。然而,当前主流 VLA 模型均依赖当前帧,忽略了时序依赖,在需要历史记忆的任务(如顺序按按钮、记忆颜色后取物)上表现不佳。
"Robotic manipulation is inherently non-Markovian, and earlier actions influence later decisions, calling for temporal modeling."
朴素方案——直接拼接多帧——面临两大障碍:
(1)自注意力的二次复杂度严重限制了可用的时序上下文长度;
(2)多帧输入与模型在单帧机器人数据上预训练的分布不匹配。
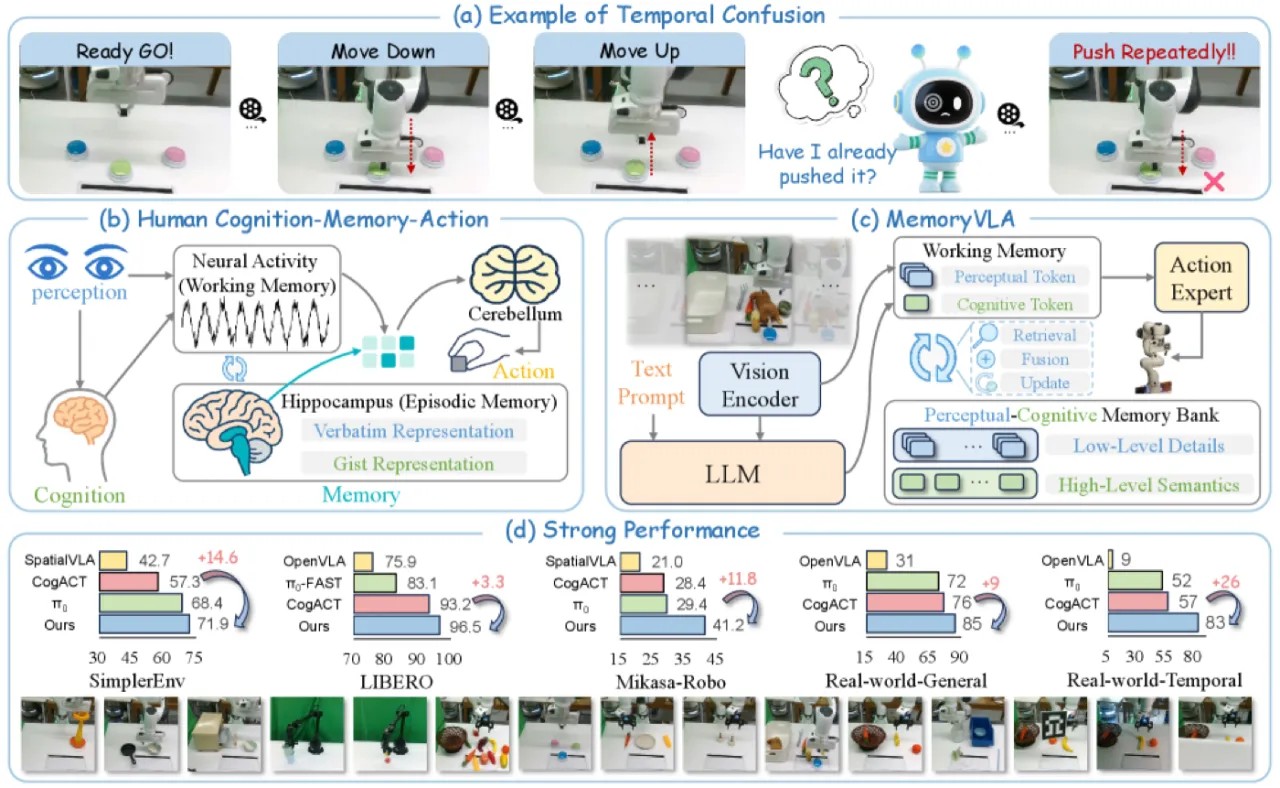
71.9%SimplerEnv-Bridge 成功率
+14.6 pts over CogACT
+14.6 pts over CogACT
83%真实长时程任务成功率
+26 pts over CogACT
+26 pts over CogACT
96.5%LIBERO 整体成功率
+3.3 pts over CogACT
+3.3 pts over CogACT
+3.6%推理延迟增量
0.194 s @ RTX 4090
0.194 s @ RTX 4090