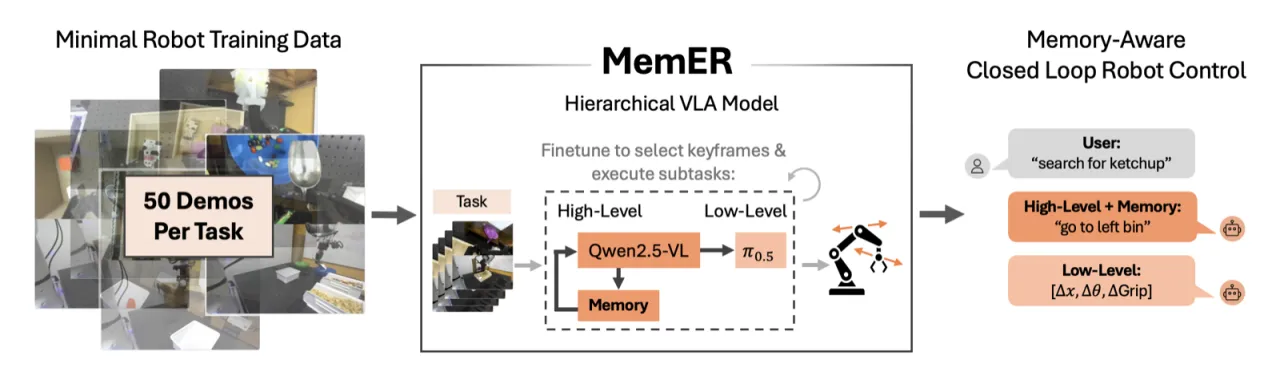
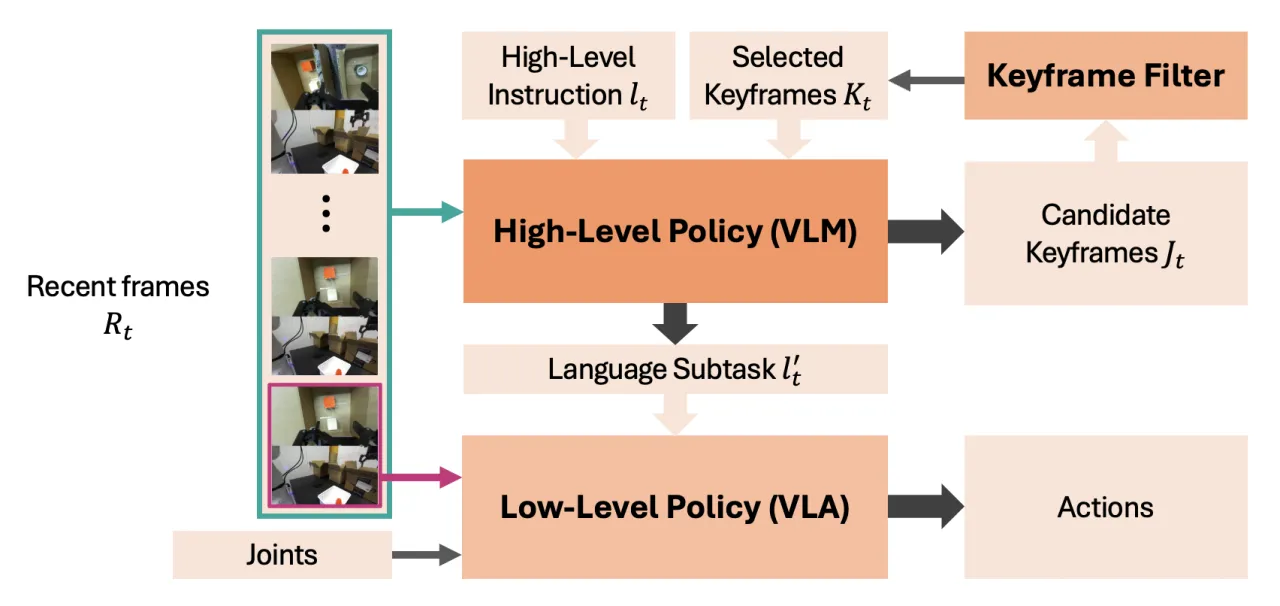
"Naively conditioning on long observation histories is computationally expensive and brittle under covariate shift,
while indiscriminate subsampling of history leads to irrelevant or redundant information."
Note:以下限制均为论文作者在 Discussion and Future Work 部分明确陈述(stated)。
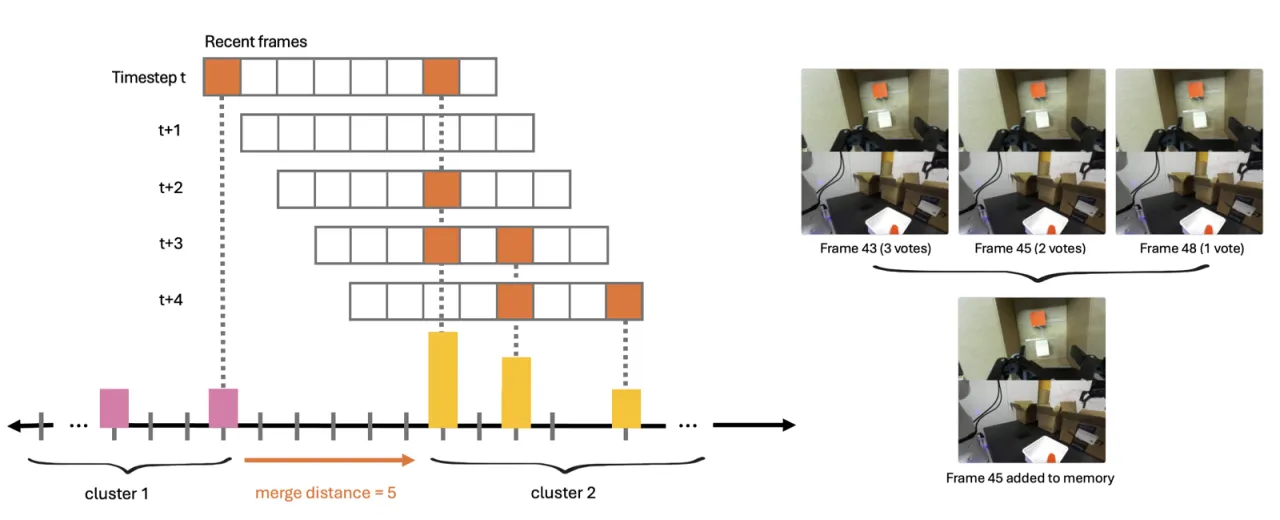
记忆无上限——缺乏关键帧遗忘机制
MemER 持续累积信息性关键帧,但目前缺乏在关键帧数量过多时主动丢弃的机制。
对于需要数小时记忆的任务,这一问题可能导致上下文溢出。
论文指出:"enabling the high-level policy to reason about which keyframes to not only add but also delete
for modifiable long-term memory is an exciting direction for future work."
当前 MemER 的记忆完全基于图像帧,未纳入触觉、音频等其它感知模态。
论文认为"incorporating other sensory modalities such as tactile or audio is a promising extension."
仅在单一机器人本体 / 单房间场景上验证
所有实验均在 Franka 手臂 + DROID 台架上进行,未测试移动机器人或跨房间任务。
论文指出扩展到"mobile manipulation and multi-room tasks, where memory must interleave spatial mapping
with episodic recall"是使系统更接近人类记忆能力的重要一步。