01 动机 Motivation
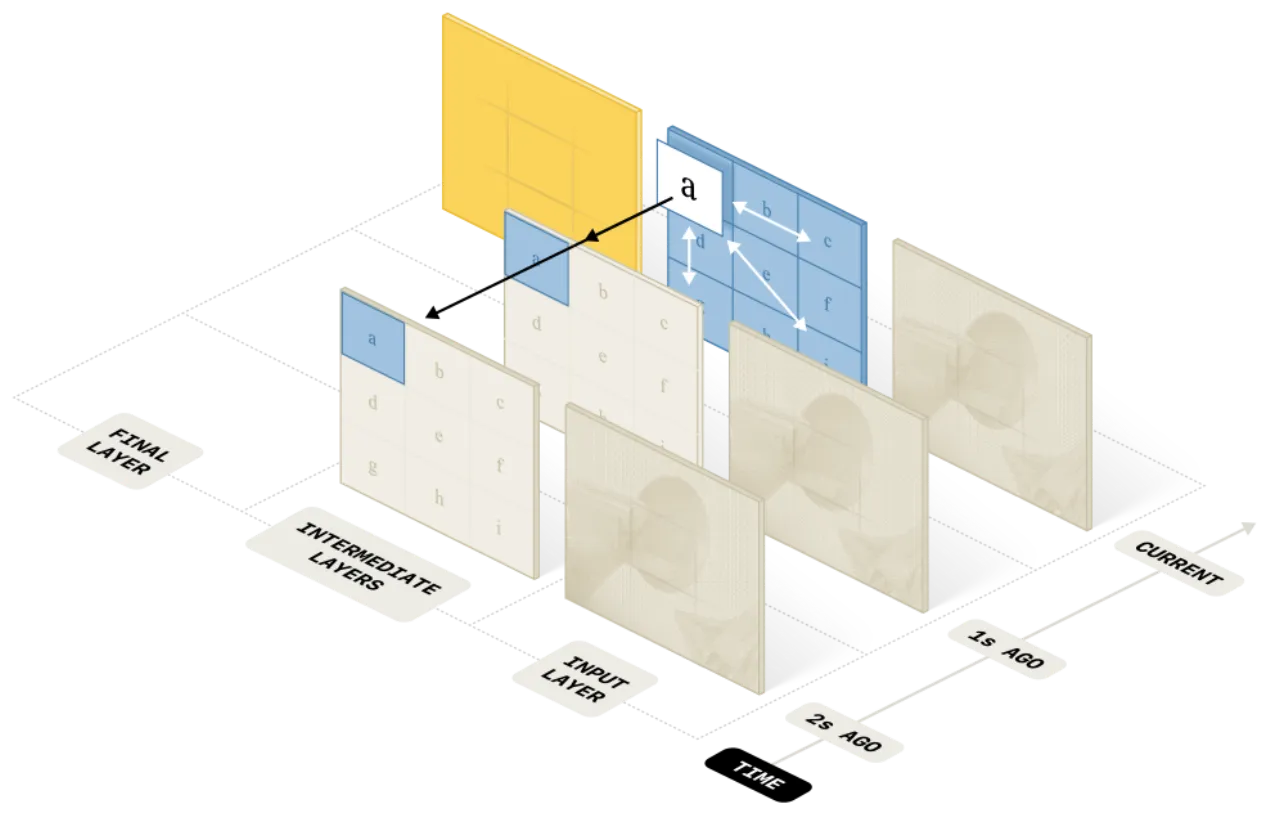
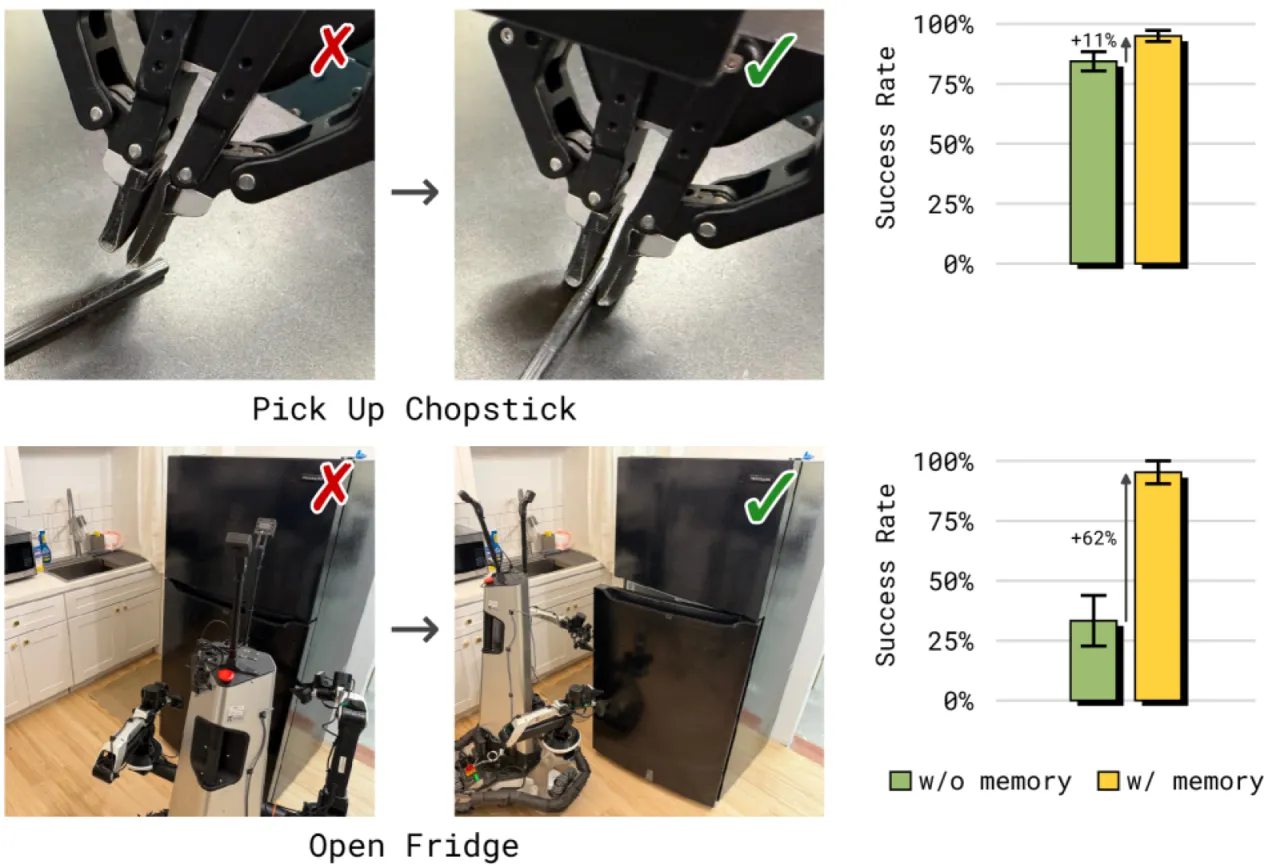
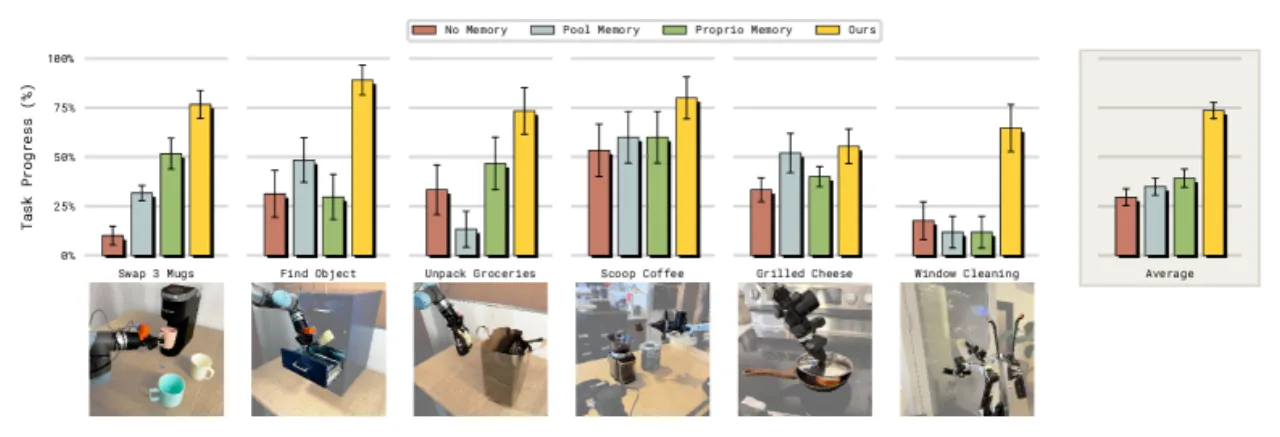
现有 VLA 模型(如 π₀.₆)在处理单步或短时操作任务时表现出色,但面对需要数分钟乃至十余分钟记忆的长时程任务时,性能急剧下降。它们缺乏一种既能捕捉细粒度局部操作动作、又能跟踪宏观任务状态的记忆机制。
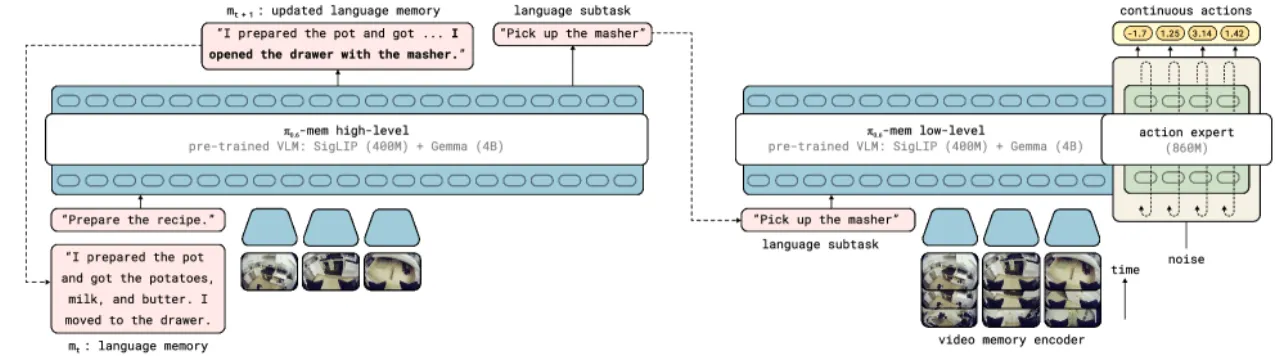
"Effective robotic memory should operate across multiple levels of abstraction: a short-horizon memory to track recent observations at a fine-grained level, and a long-horizon memory to track the state of a task at a semantic level." — 论文核心论点
15 min支持的最长任务记忆时长
54 s短时视频记忆覆盖的观测时长(推理时)
42Recipe Setup 训练菜谱数(5 道菜在未见场景评测)
4th每第 4 层插入一次 temporal attention
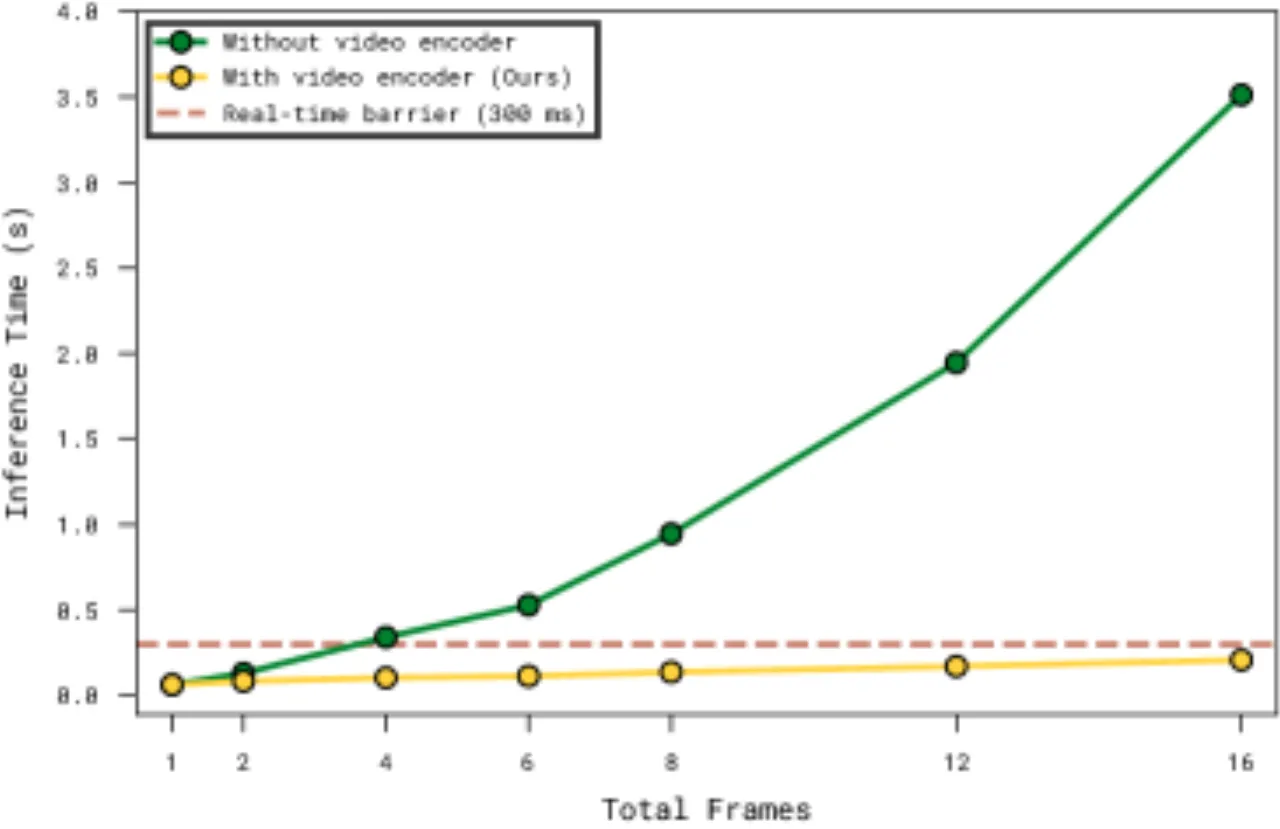
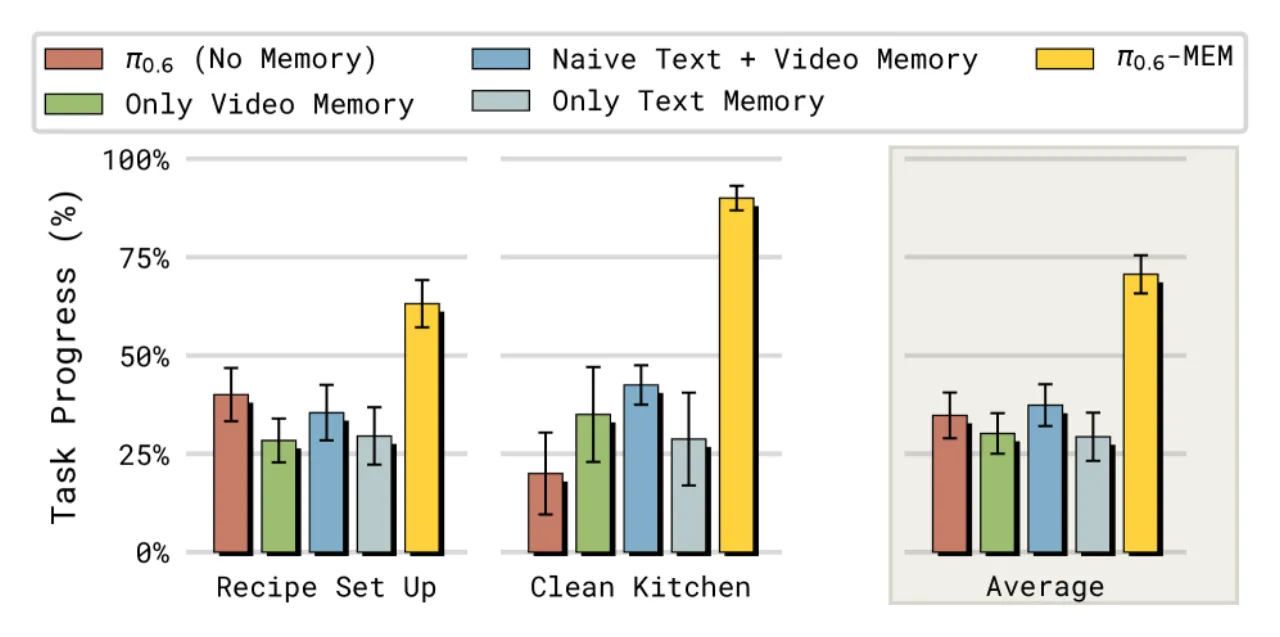
核心挑战在于:简单地将多帧图像拼接送入 VLA backbone 会导致推理延迟急剧增加,无法满足实时控制需求;而仅依赖文本记忆则无法捕捉精细的操作细节(如擦拭表面的时间长短、当前抓握状态等)。MEM 通过两级异构记忆的组合解决这一矛盾。