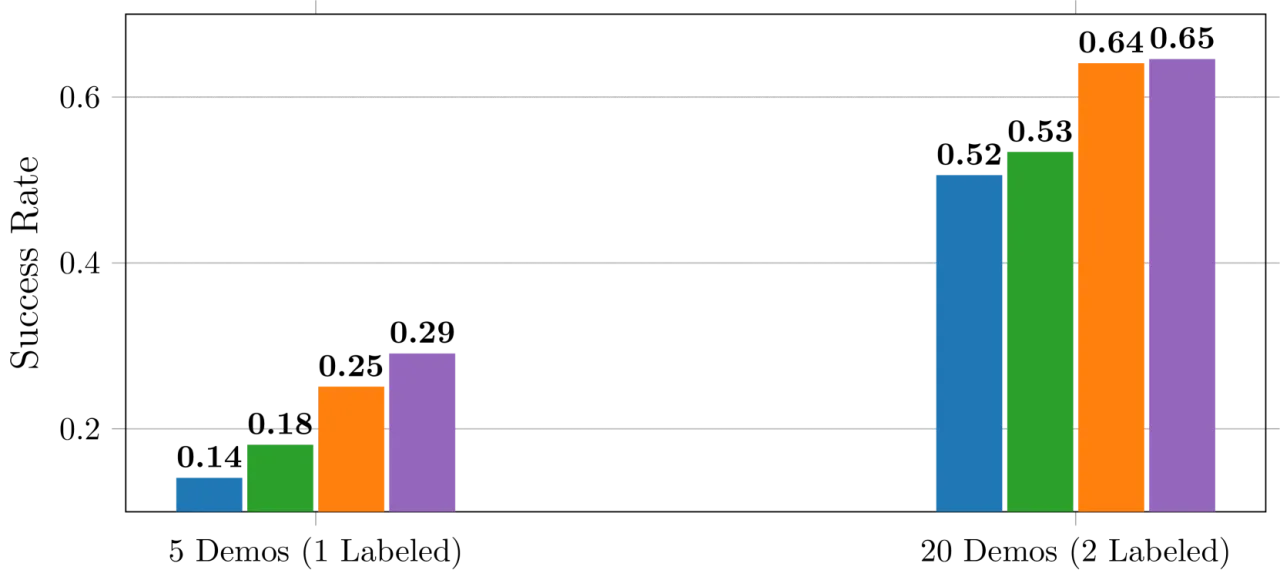01 Motivation
现实中的机器人示教数据往往只有图像目标,语言标注极为稀缺。如何在只有少量语言标注的情况下,让策略同时支持图像目标和语言目标的条件输入,是构建通用机器人操作系统的核心挑战。
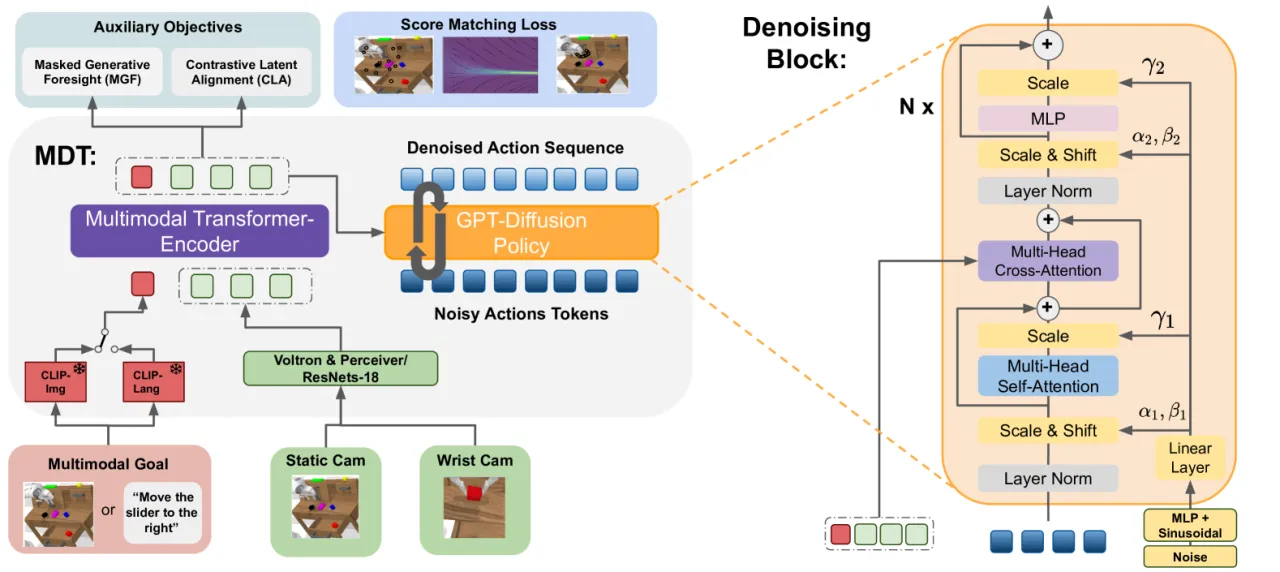
"We propose a multimodal diffusion policy that learns robot manipulation behaviors from multimodal goals with few language annotations."
4.52CALVIN ABCD→D
平均完成链长(MDT-V)
平均完成链长(MDT-V)
+15%超越 RoboFlamingo
在 ABCD→D 子集上的绝对提升
在 ABCD→D 子集上的绝对提升
2%语言标注比例
仍超越全标注 Transformer-BC
仍超越全标注 Transformer-BC
<10%相比 RoboFlamingo 所用
可训练参数量比例
可训练参数量比例
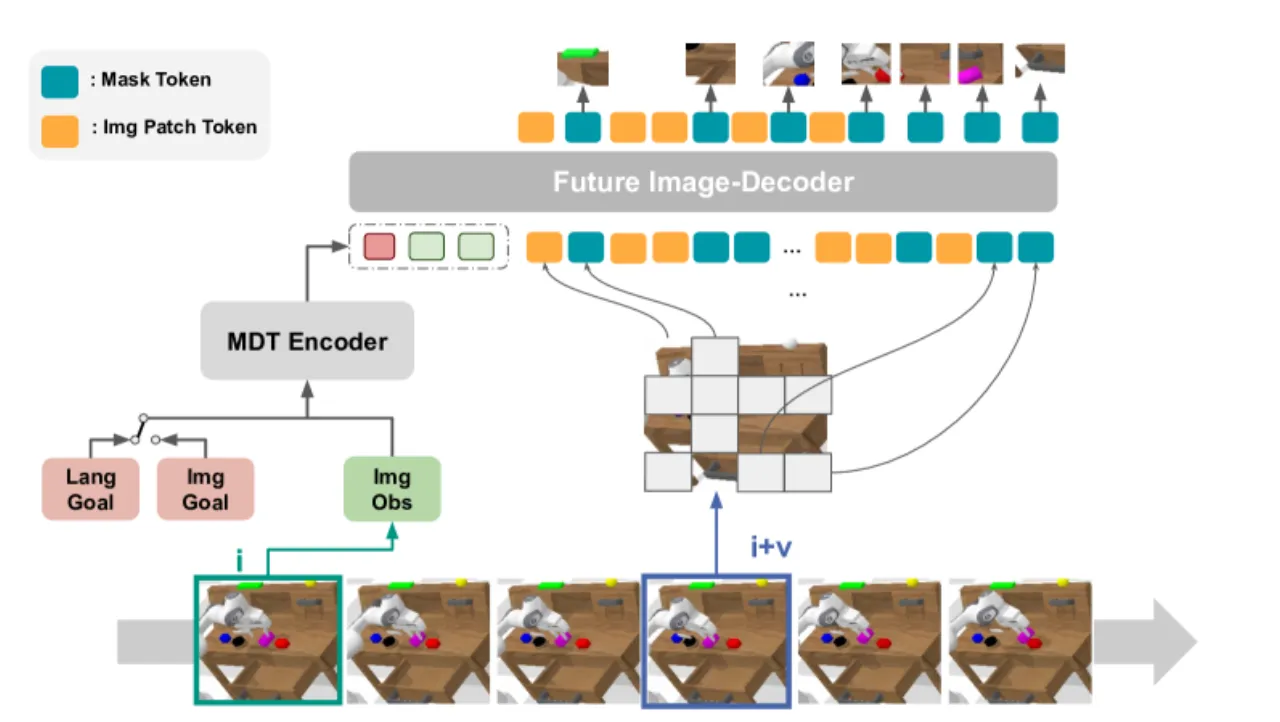
在大多数现实数据集中,语言指令只覆盖小部分演示,而图像目标(goal image)则可以免标注地从轨迹末帧获取。MDT 通过同时支持两种目标模态,充分利用了这类不完整标注数据集。与依赖大规模预训练(如 RoboFlamingo)的方法相比,MDT 无需预训练,参数量更少,却取得更好的效果。