01 动机 Motivation
语言条件机器人操控任务需要在非结构化环境中完成复杂的物体交互。现有的感知类方法(perceptive methods)提取语义特征做动作预测,而生成类方法(generative methods)通过自监督重建 3D 场景来辅助学习——但两类方法都忽略了一个关键因素。
"Conventional robotic manipulation methods...ignore the scene-level spatiotemporal dynamics that depict the physical interaction among objects during manipulation."
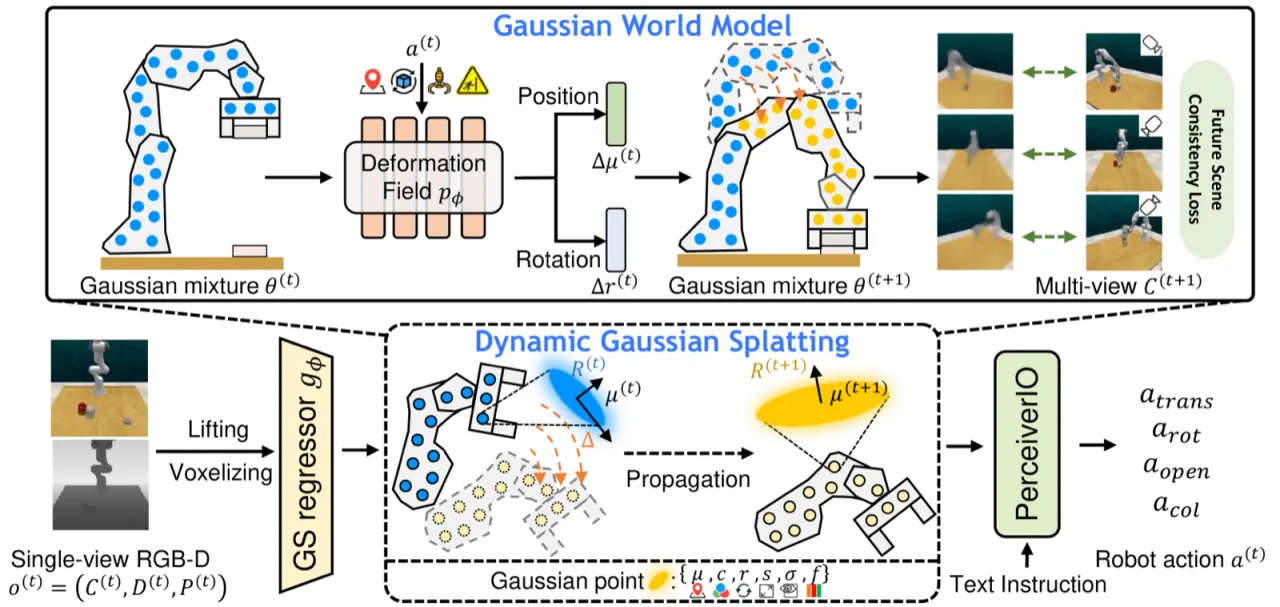
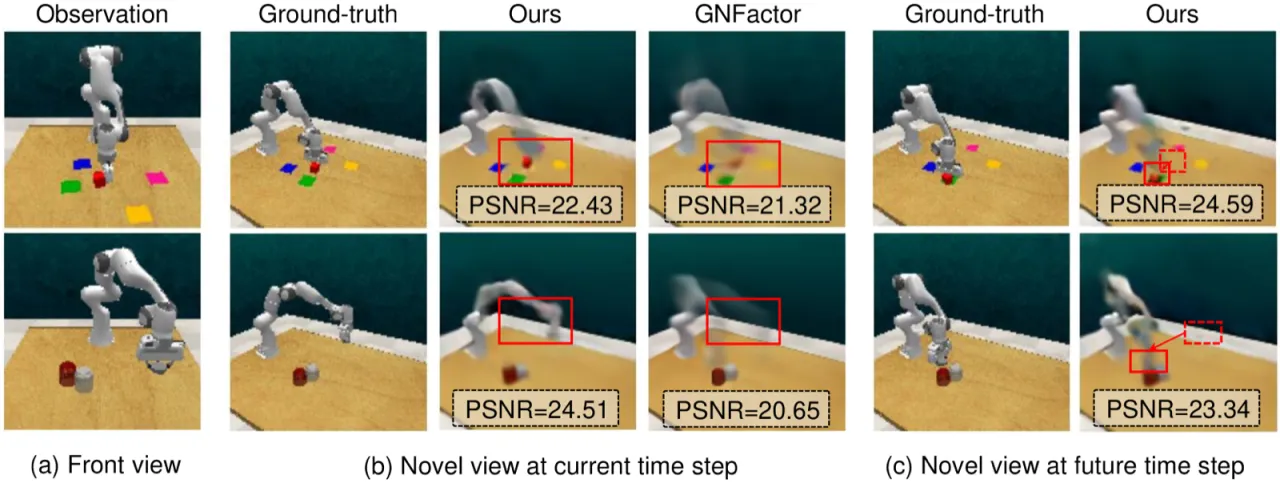
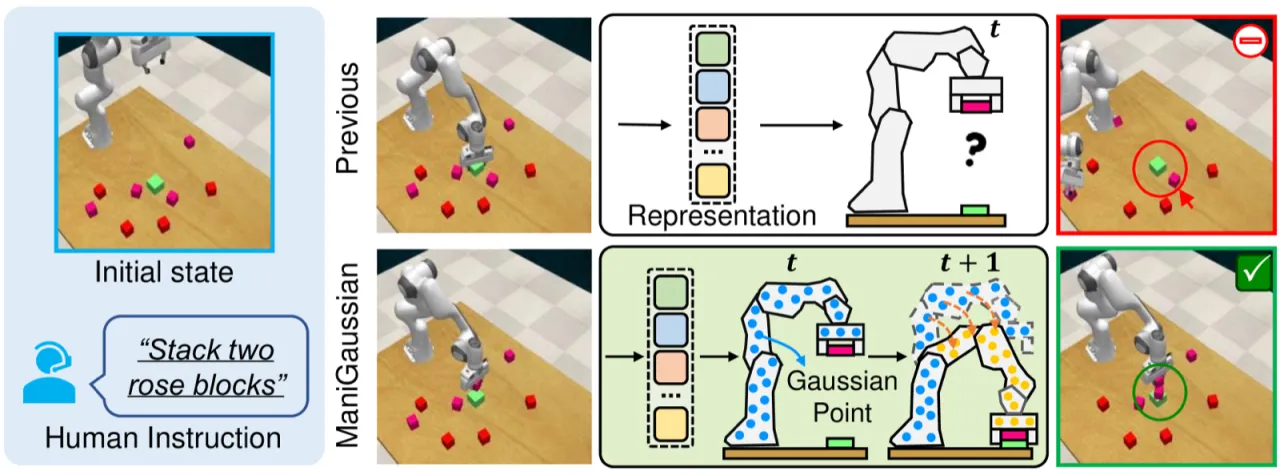
机器人在推、抓、拧、滑等任务中,物体之间存在时序上的因果依赖:夹爪移动如何引发物体位移?下一帧场景会如何变化?若模型无法建模这种时空动态,就难以在 long-horizon 或需要多步推理的任务中保持稳定。ManiGaussian 的核心思路是:以「预测未来场景」作为额外监督信号,迫使模型内化场景动态。
44.8%平均成功率(10 tasks)
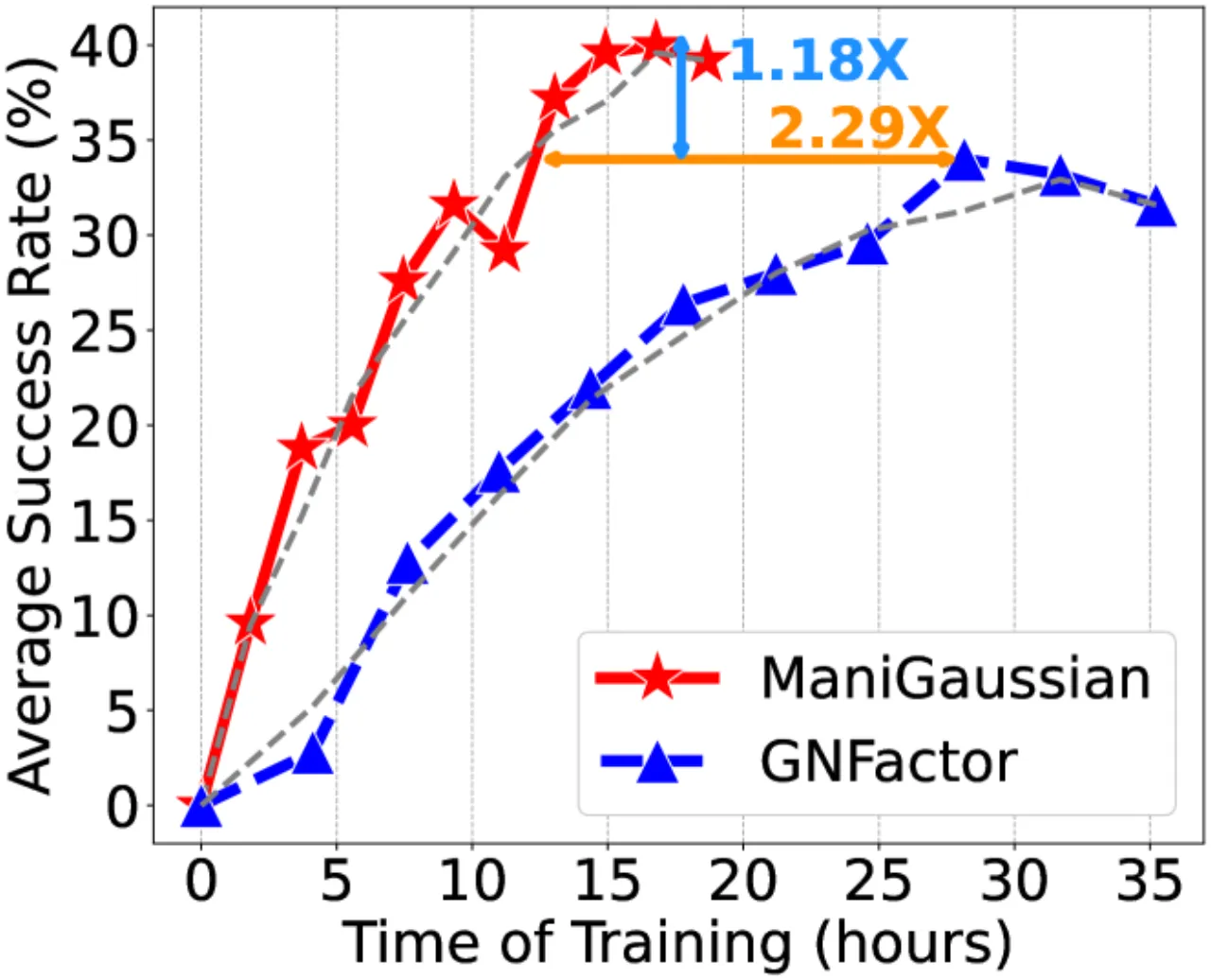
+13.1%超越 GNFactor(SOTA)
2.29×训练速度(相同性能)
166任务变体总数