01 动机
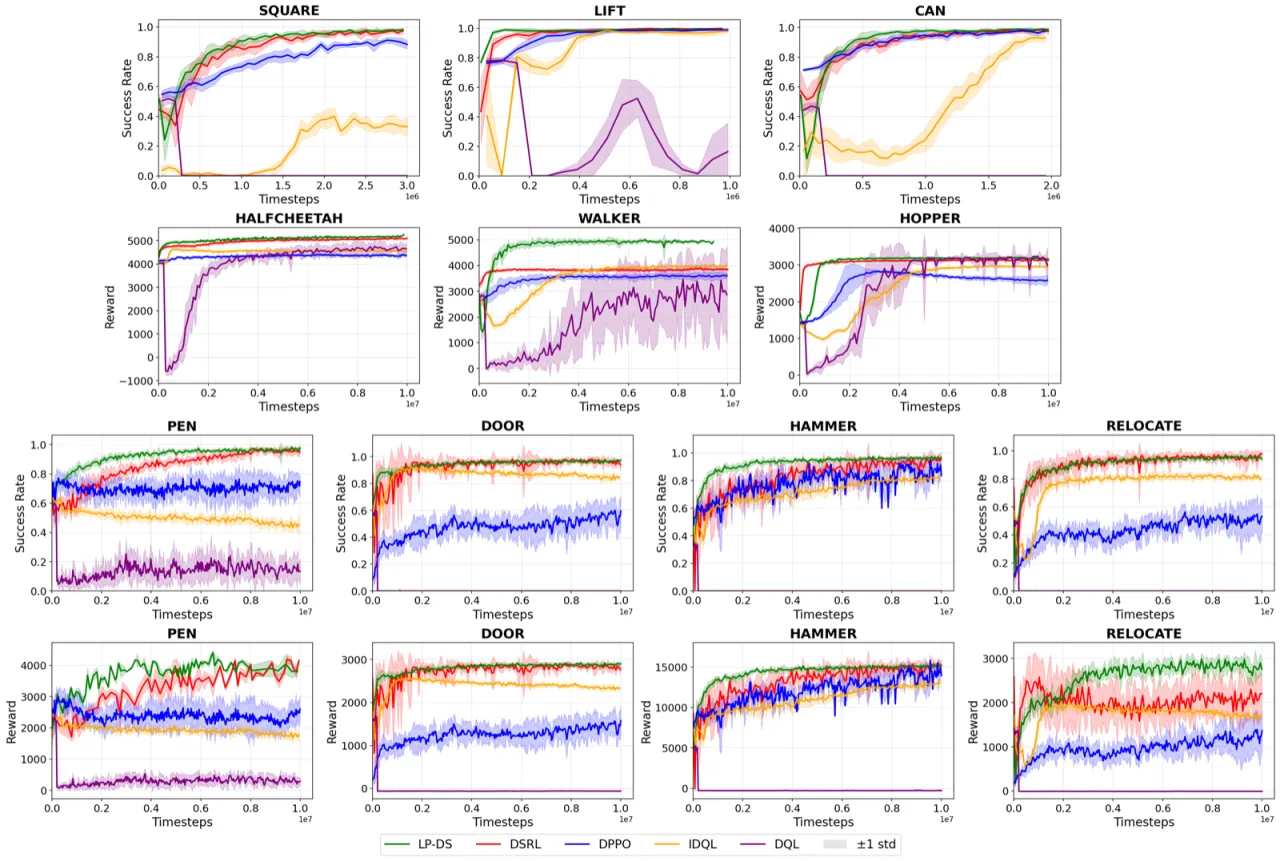
基于行为克隆(Behavior Cloning)的高容量生成策略在模仿学习中表现优异,但受限于演示数据覆盖范围不足以及分布偏移问题。 直接用强化学习(RL)微调大型生成解码器往往不稳定且样本效率低下。 已有的噪声空间引导方法 DSRL 虽能绕开解码器修改,却存在潜在查询漂移和行为模式坍塌两大缺陷。
"LP-DS shifts Gaussian noise inputs via w = ε + Δθ(s) and optimizes Δθ with a Lagrangian trust-region objective that improves downstream value while limiting deviation from the latent prior."
核心挑战:DSRL 的两大失败模式
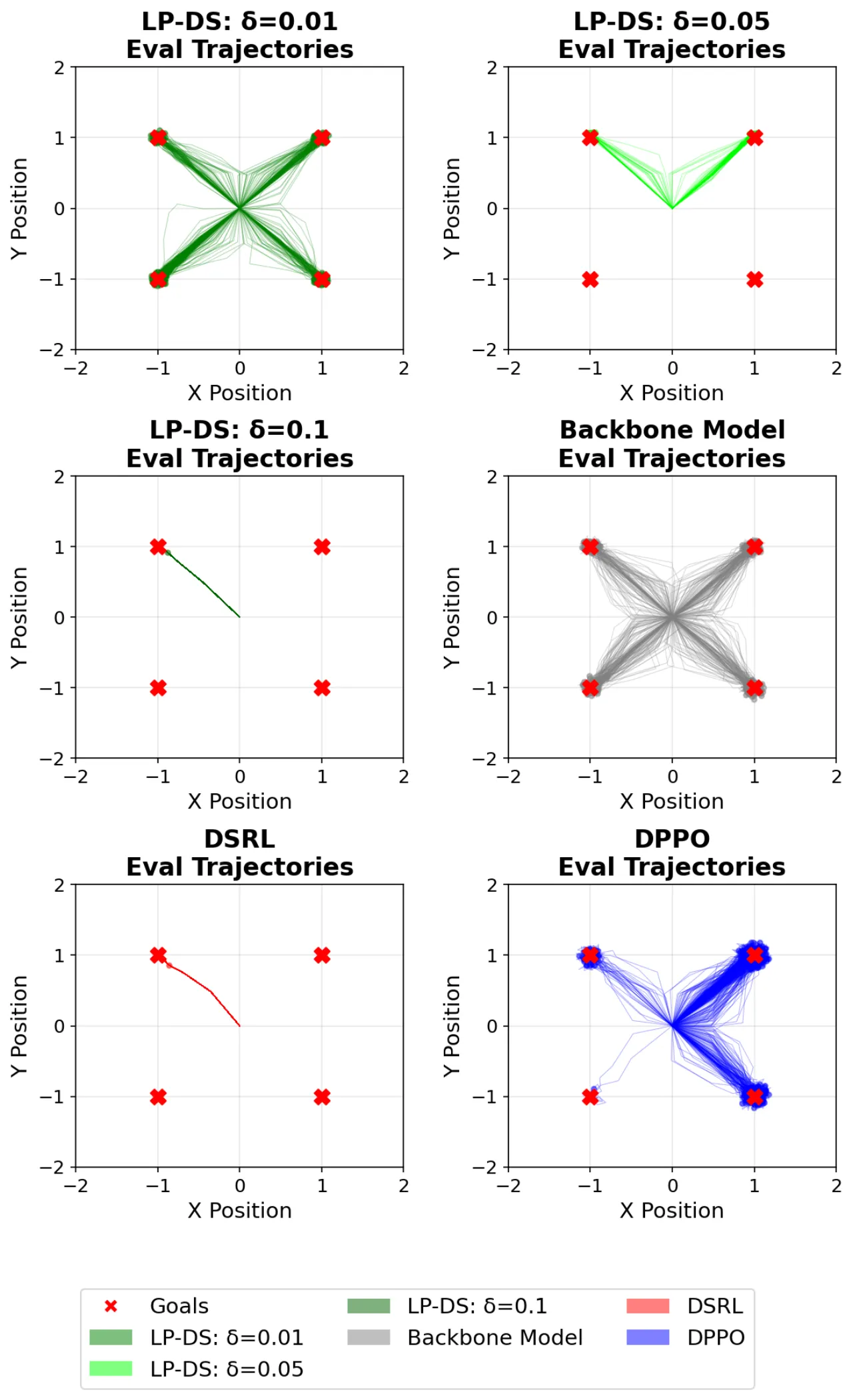
① 潜在查询偏离流形
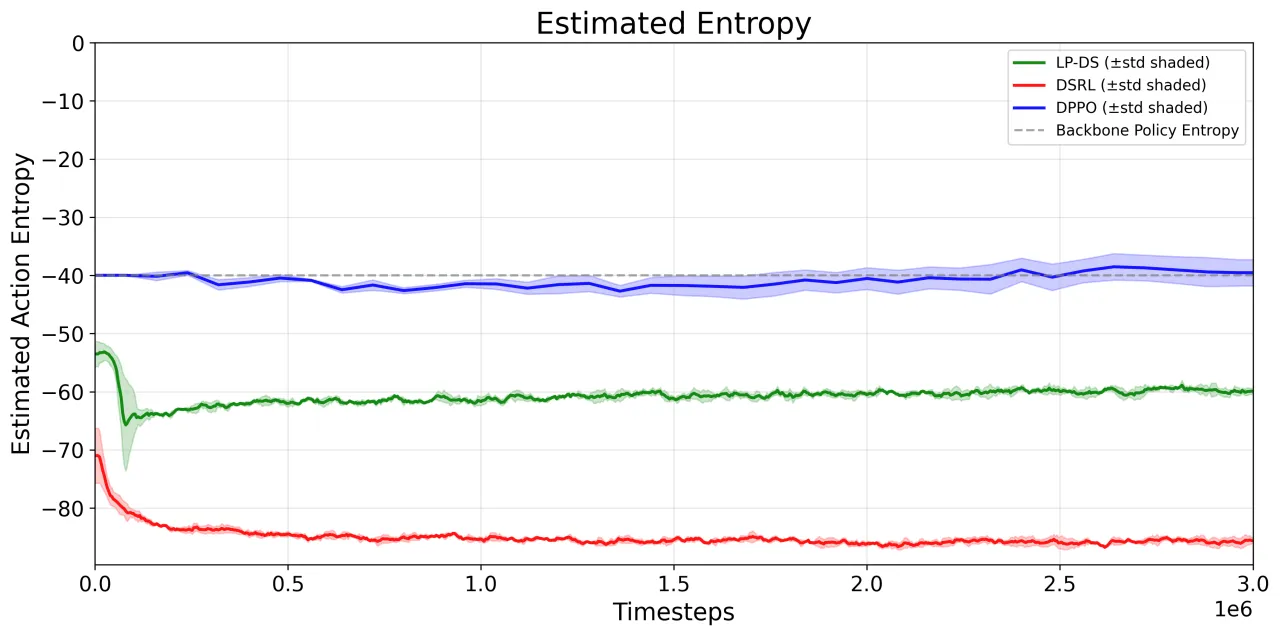
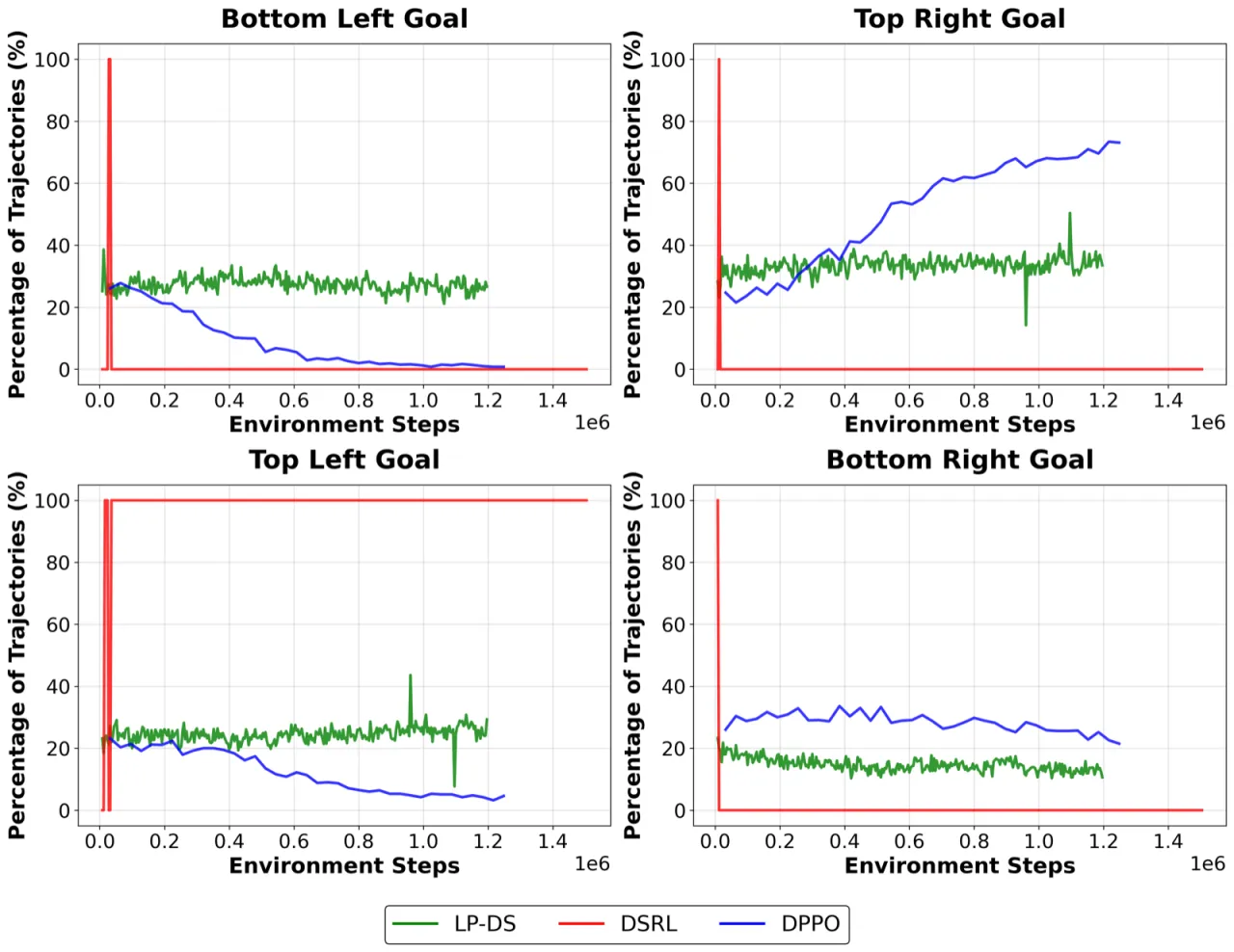
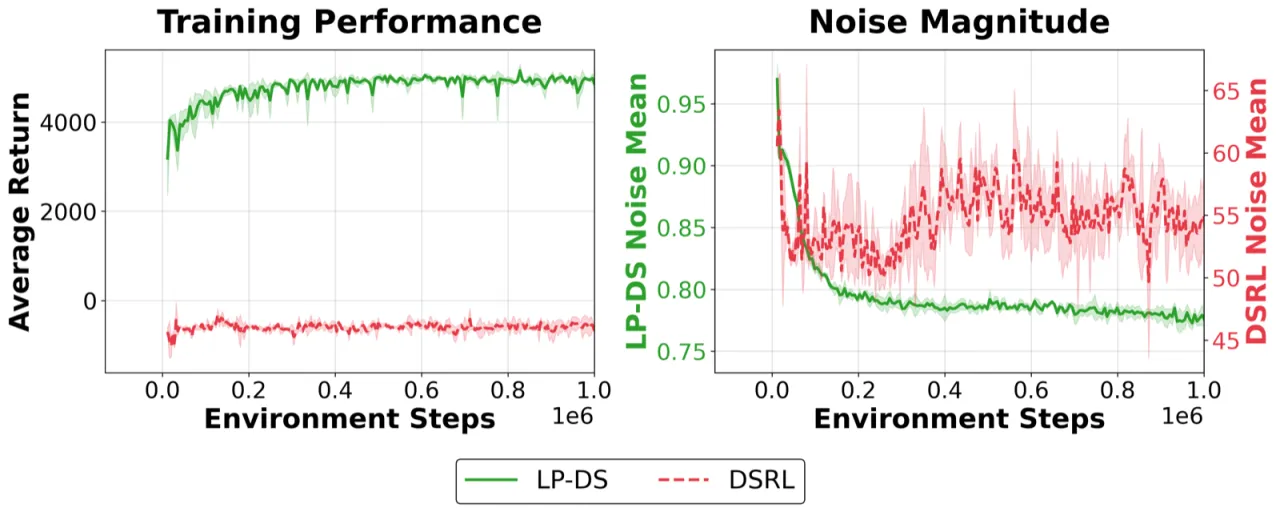
DSRL 用无约束潜在策略替代预训练先验(prior),导致生成的噪声向量偏离解码器训练时所用的标准高斯分布支撑集, 引发不规则动作输出和性能退化。图2 清晰展示了这一现象:DSRL 预测出高幅值潜在查询, 与解码器不稳定行为高度相关。
② 行为多样性坍塌
无约束的潜在空间优化会将概率质量集中到少数高奖励区域, 骨干策略的多模态结构(multimodal structure)随之消失。 LP-DS 通过拉格朗日信任域机制显式约束扰动幅度,防止过度激进的模式集中。
25%Walker2D 回报提升(对比最强 baseline)
33/40Franka 真实机器人拾放成功率(冻结 baseline 为 18/40)
17/20Franka 挂杯成功率(冻结 baseline 为 11/20)
δ=0.35多数实验中默认信任域目标值,对超参不敏感