01 动机
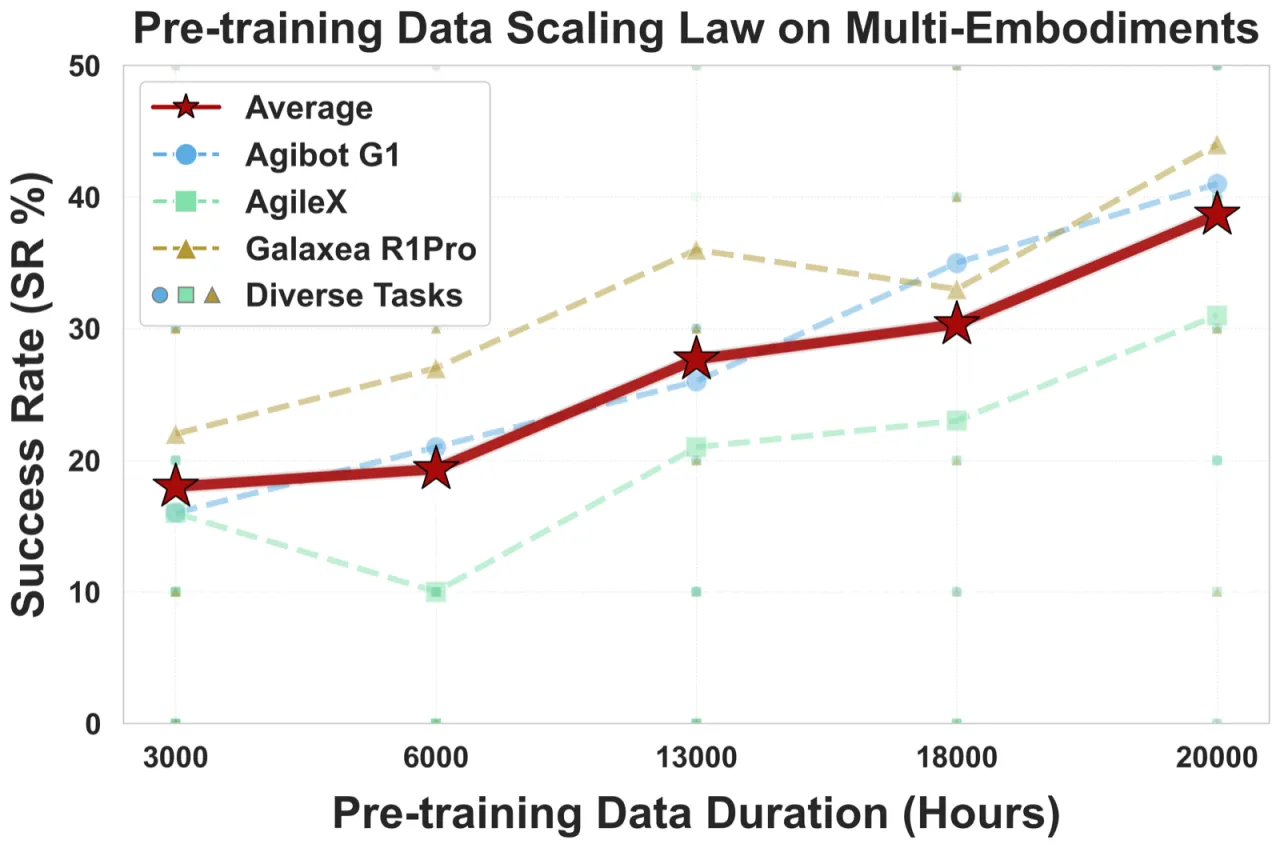
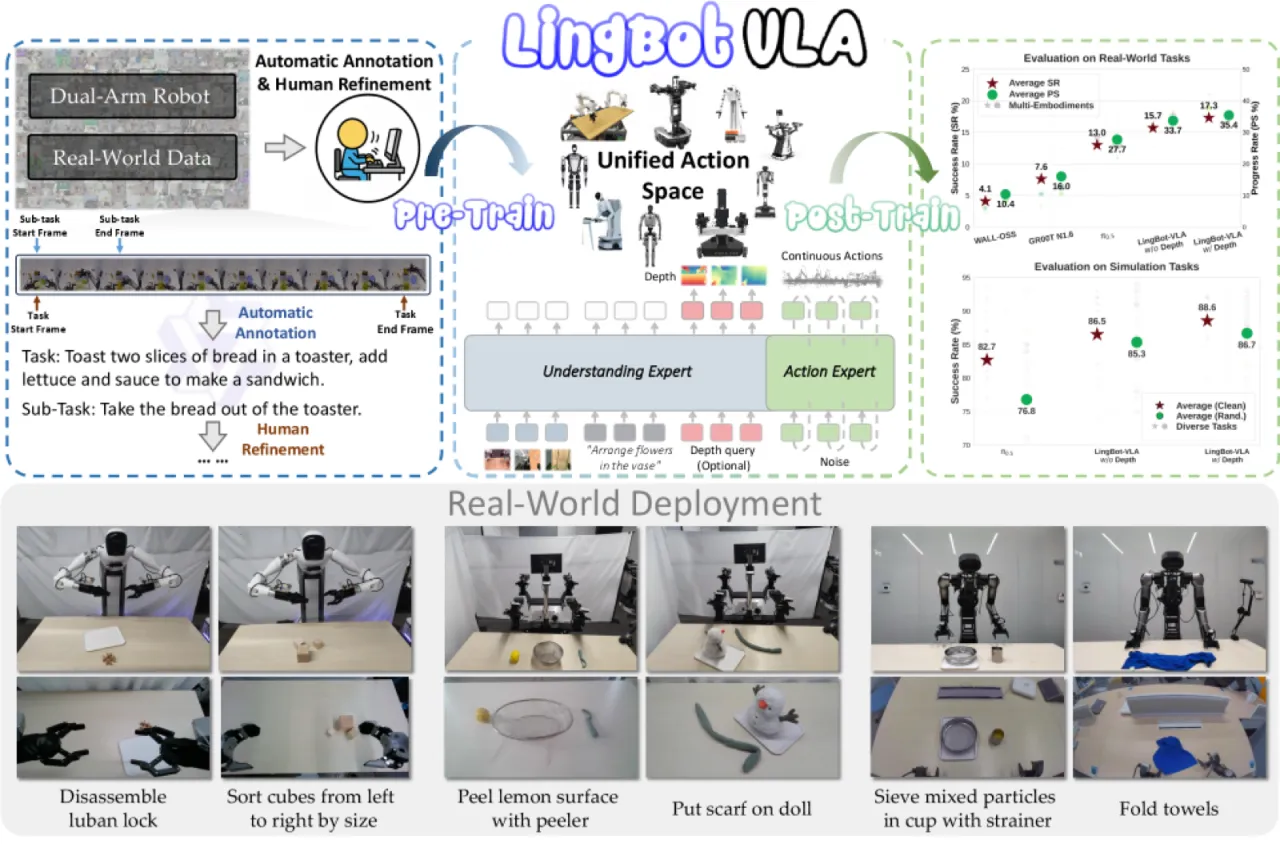
当前 VLA 模型面临两大核心挑战:数据规模不足与训练效率低下。大多数方法仅在数千小时数据上训练,且缺乏能在海量数据上高效扩展的训练框架,难以验证真正意义上的 scaling law。LingBot-VLA 的目标是构建一个务实可用的 VLA 基础模型——覆盖 9 种真实双臂机器人、2 万小时遥操作数据,并在 100 项任务的标准化基准上与主流方法直接对比。
"We present LingBot-VLA, a vision-language-action system trained on around 20,000 hours of real-world data from 9 popular dual-arm robot configurations."
~20,000h真实遥操作预训练数据
9种双臂机器人平台
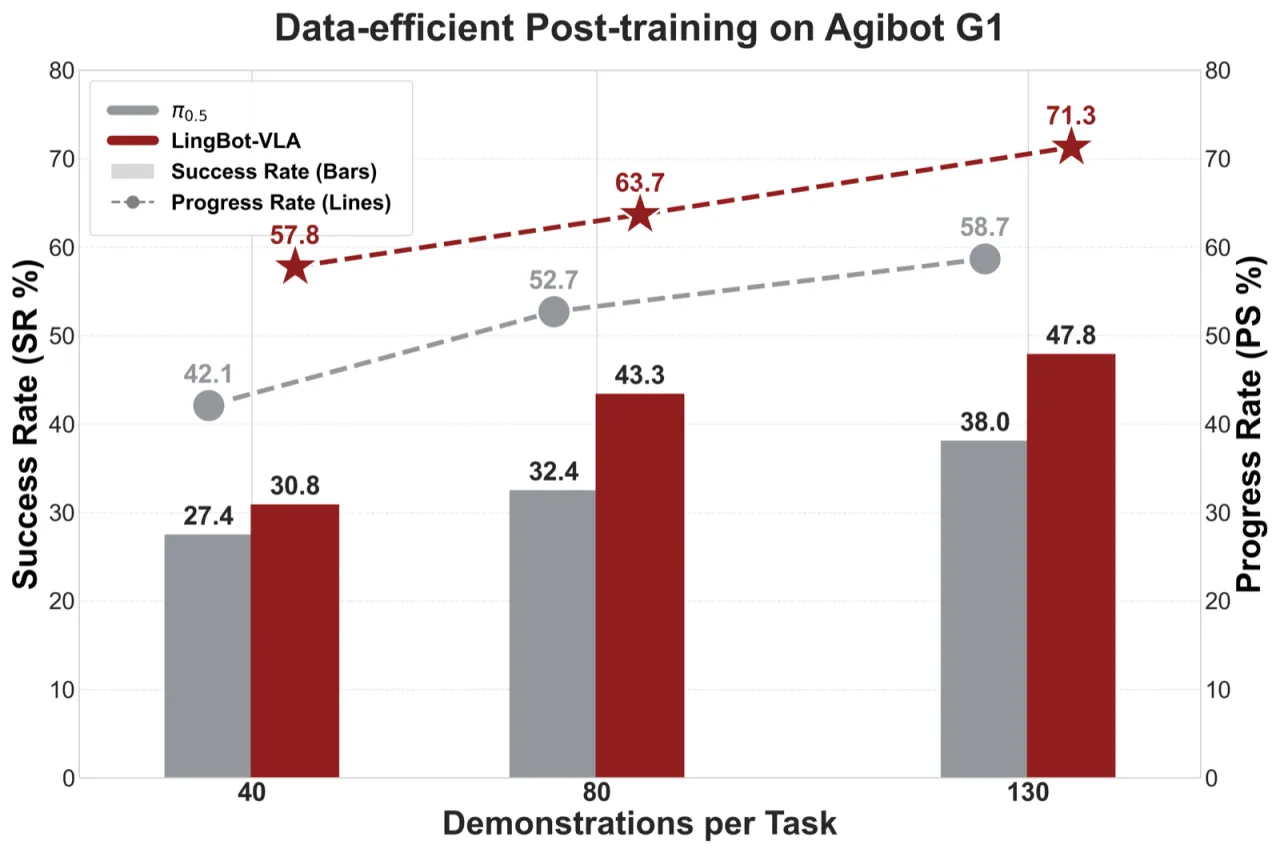
+4.28%平均 SR 超越 π₀.₅(GM-100)
261samples/s(8-GPU 训练吞吐)