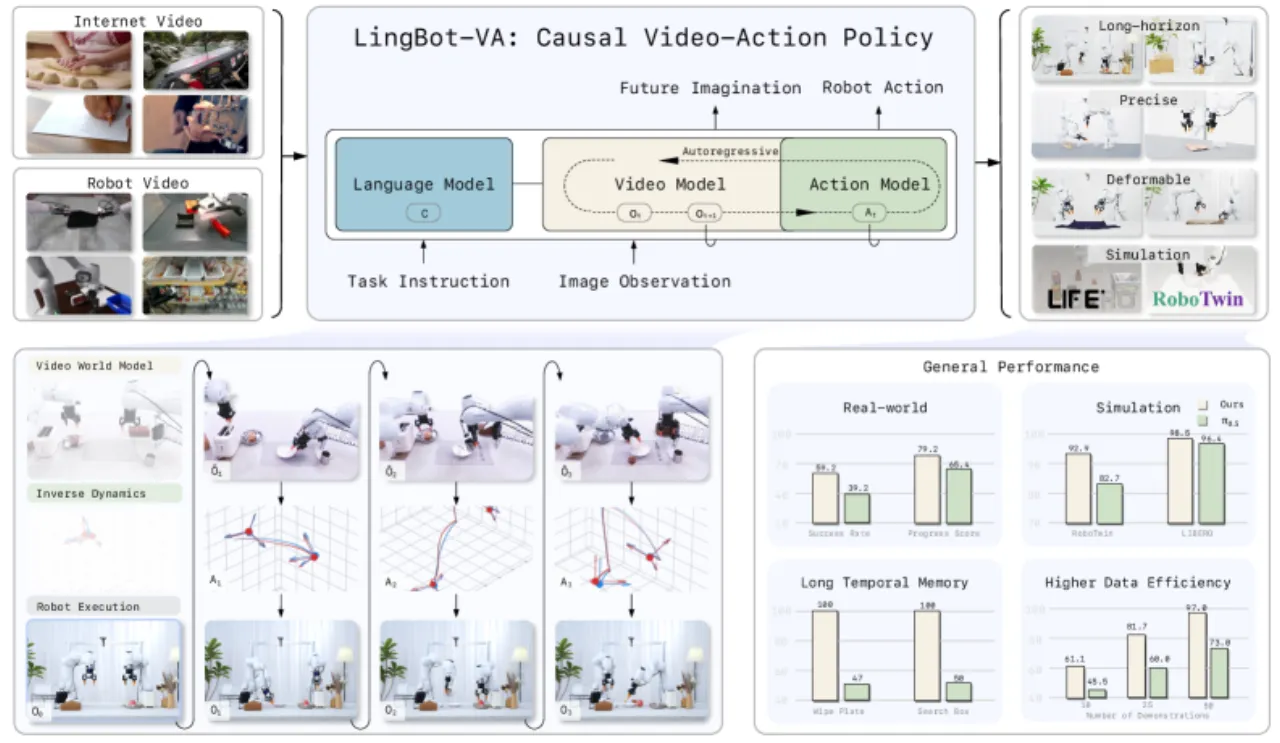
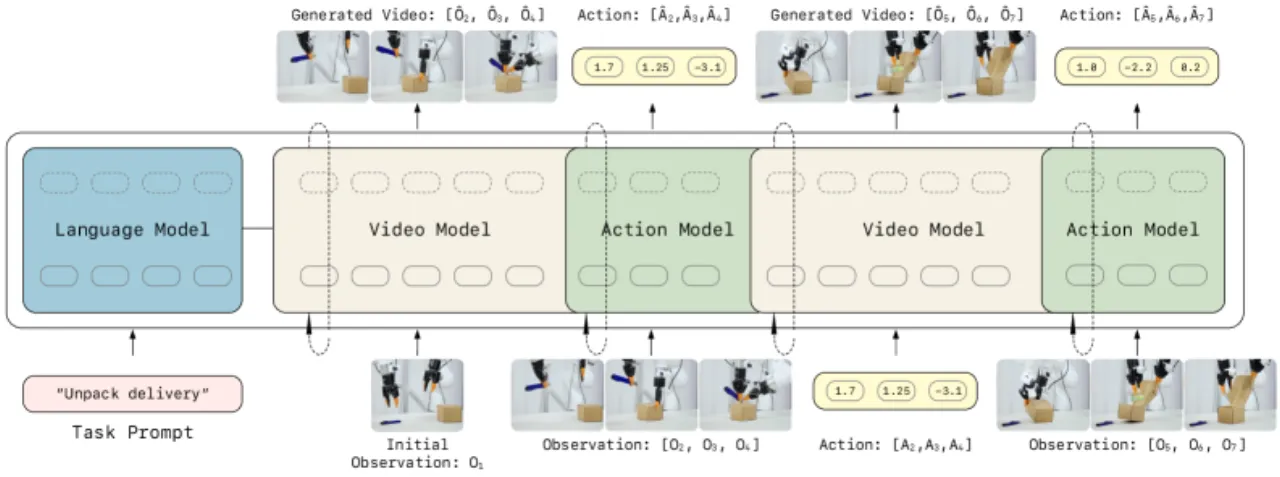
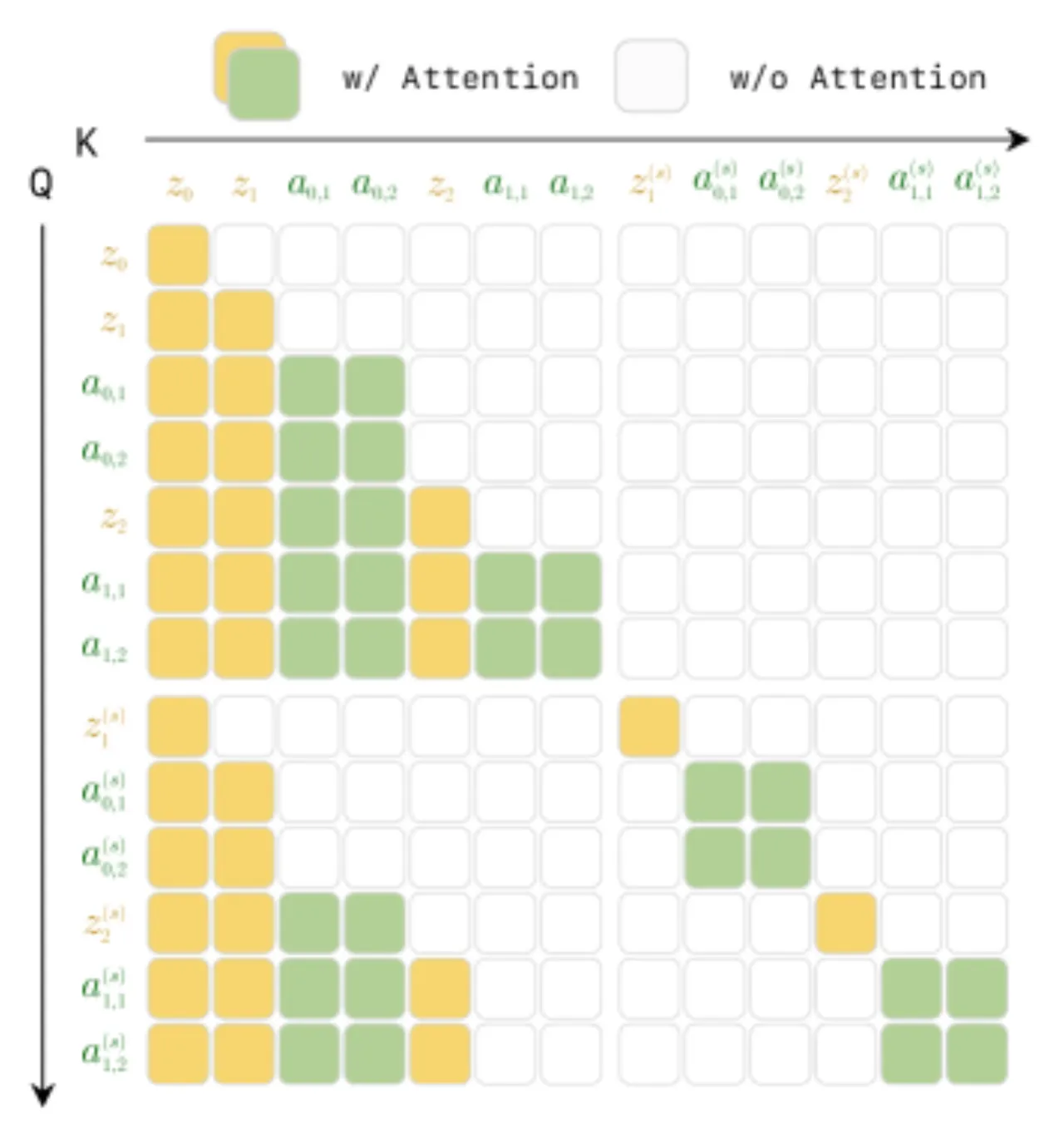
LingBot-VA 使用 Teacher Forcing 训练策略:"Each token can only attend to preceding tokens in temporal sequence",在强制因果一致性的同时实现高效的并行训练。训练时随机采样 chunk size K ∈ [1,8],使得部署时可灵活权衡闭环修正频率与计算效率。另一关键技巧是 Noisy History Augmentation:"During training, randomly augment video history with noise; enables partial denoising (s=0.5 instead of s=1.0) at inference, halving video generation steps."动作网络权重初始化采用视频权重插值并以 α=√(dv/da) 缩放,确保训练梯度平稳收敛。
异步推理流水线与 FDM Grounding
图4:异步流水线设计。同步流水线因视频生成耗时导致动作执行延迟;Naive async 则因"open-loop degradation"使模型偏好时序平滑的幻想序列;FDM-grounded async 引入 Forward Dynamics Model 将真实观测重新对齐后再做预测,在速度与精度间取得平衡。
部署阶段 KV-cache 将历史计算缓存,"Only new tokens require full attention computation; cached history tokens are reused",显著降低推理延迟。为解决 Naive async 带来的开环退化问题,引入 Forward Dynamics Model(FDM):模型利用最近的真实反馈想象施加动作后的视觉状态,强迫与环境观测重对齐后再向前预测。