01 动机
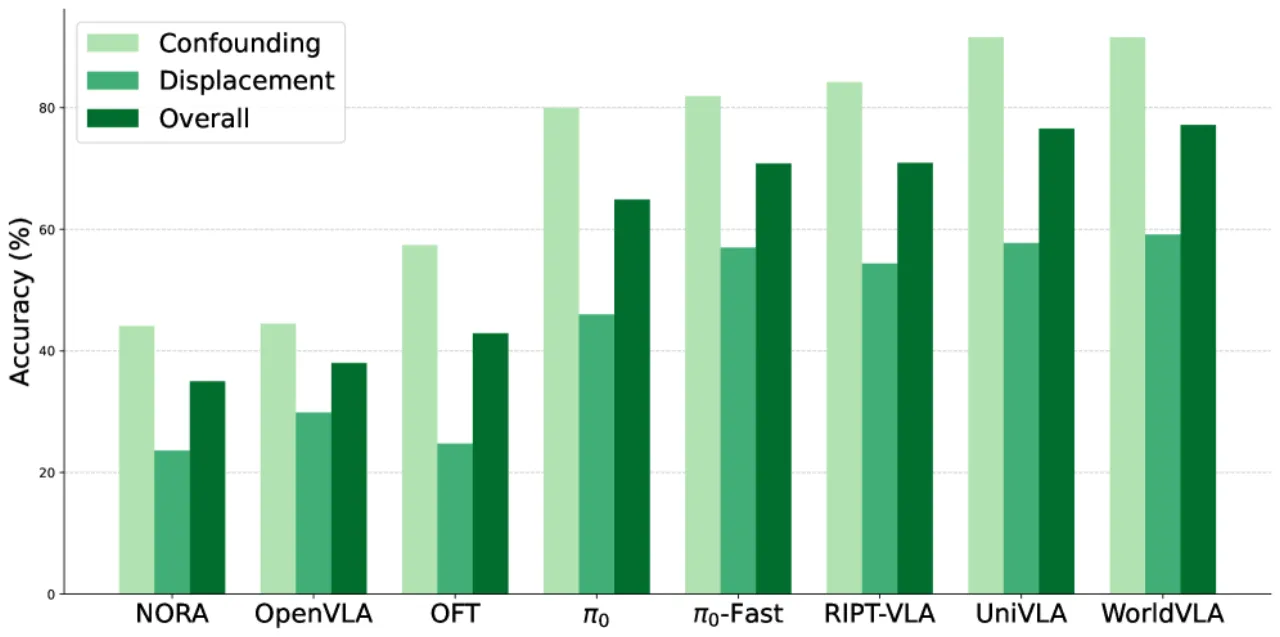
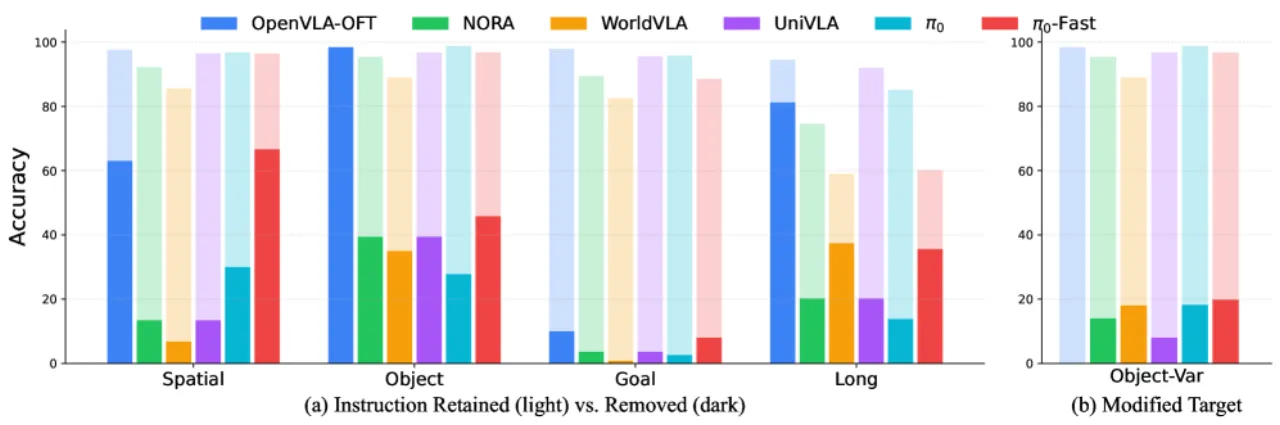
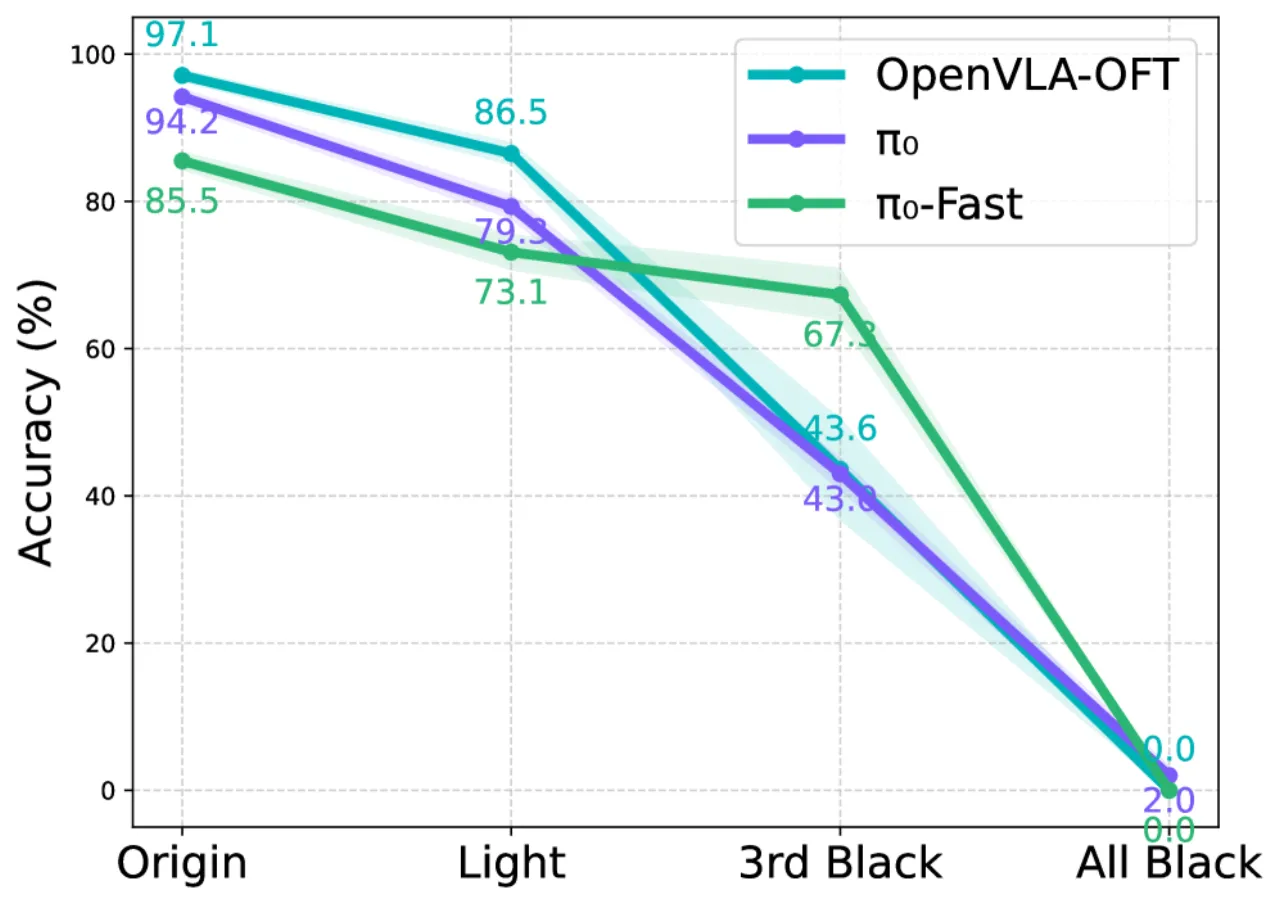
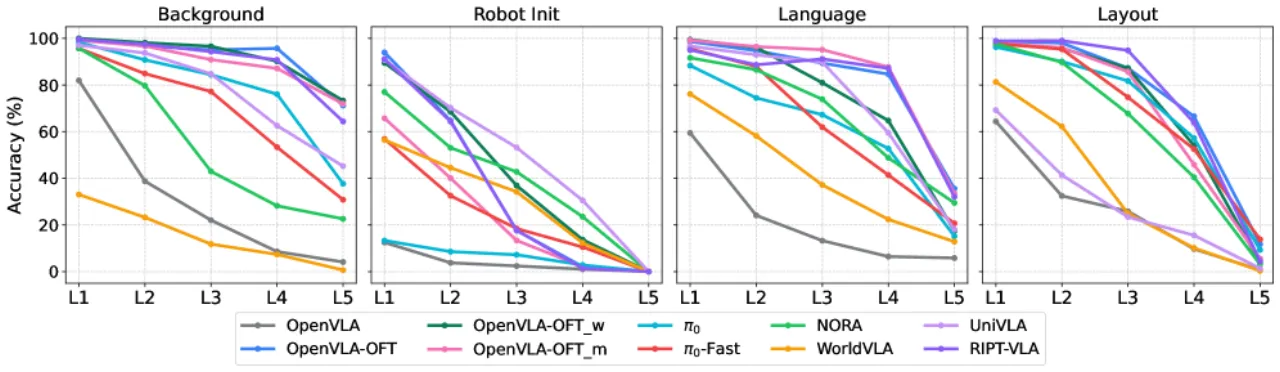
VLA 模型在标准机器人操作基准上屡创新高,然而这些基准场景高度受控,难以反映真实部署环境中的变化。当摄像头视角、场景光照、背景纹理或语言描述稍作调整,模型性能会如何变化?现有研究缺乏对多维度扰动的系统性探索。
"Visual–Language–Action (VLA) models report impressive success rates on robotic manipulation benchmarks, yet these results may mask fundamental weaknesses in robustness."
95%→<30%典型模型在摄像头视角扰动下的性能骤降范围
10参与评估的最新 VLA 模型数量
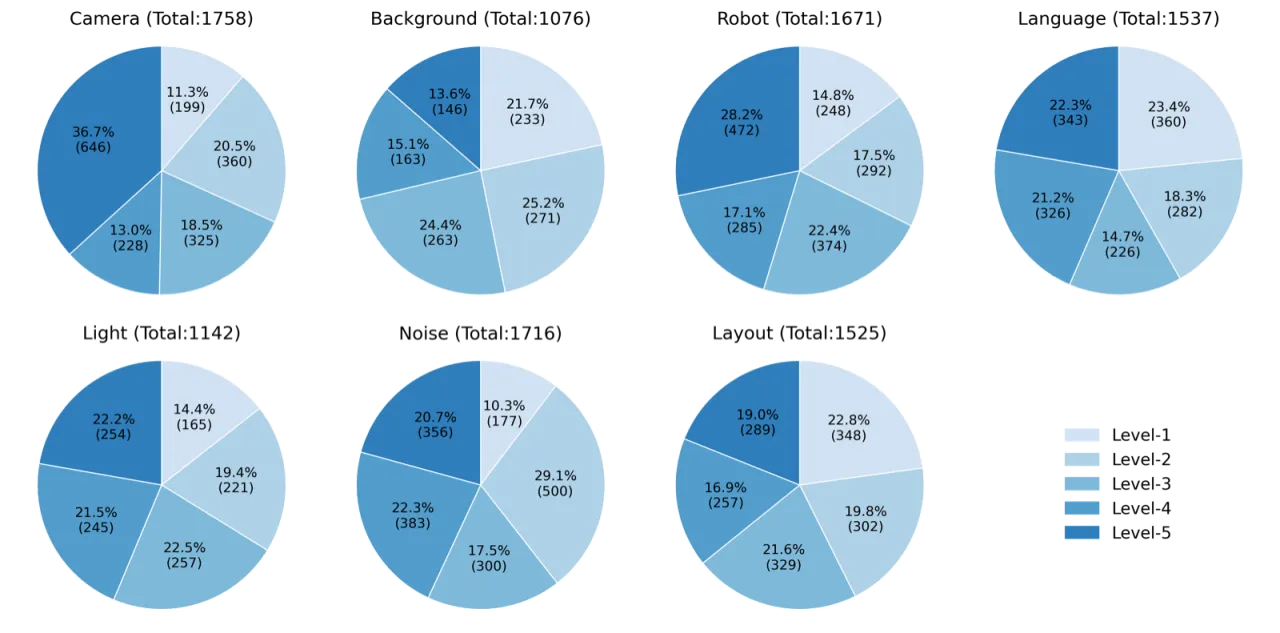
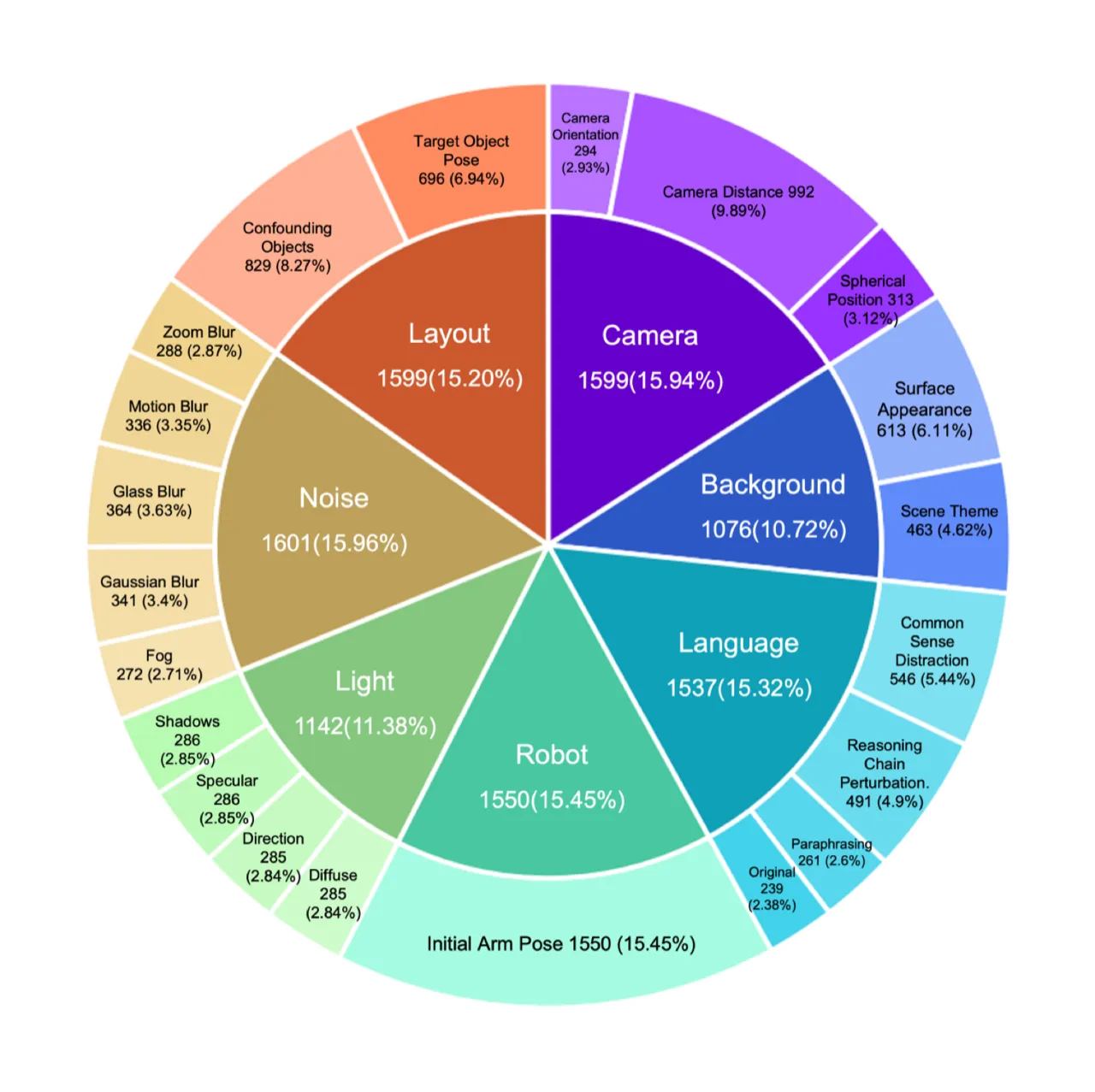
10,030LIBERO-Plus 基准任务总数
7扰动维度(含 21 个子维度)
现有机器人操作基准(如 LIBERO、AGNOSTOS、COLOSSEUM 等)在扰动维度覆盖、细粒度分析和自动化生成等方面存在明显不足。LIBERO-Plus 正是为弥补这一空白而设计:在标准 LIBERO 场景基础上,自动化地注入 7 类扰动并按难度分级,从而构建可重复、可扩展的鲁棒性评估框架。