01 动机
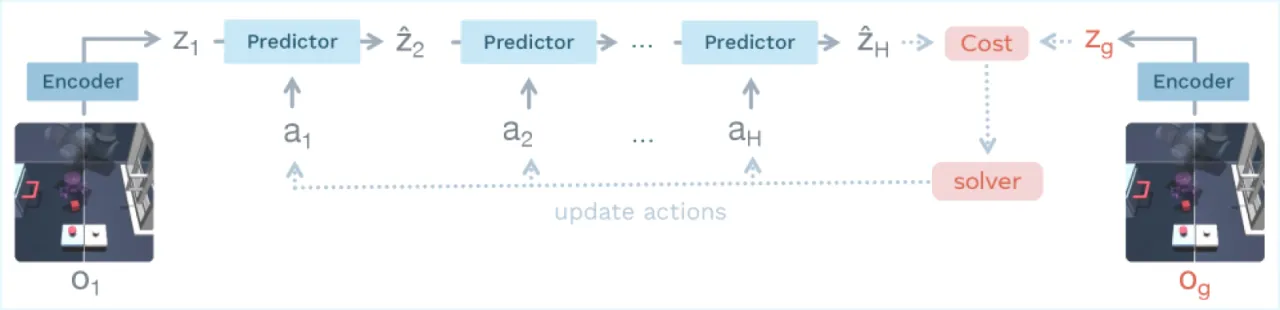
训练 Joint Embedding Predictive Architecture (JEPA) 的核心难题是表征坍塌(representation collapse):若不加约束,编码器会将所有输入映射到同一点或低秩流形,预测误差趋零但表征毫无意义。现有方案须依赖复杂的多项损失、指数移动平均(EMA)目标网络、预训练编码器或辅助监督,工程复杂度高且超参数众多。
"Existing methods for training JEPAs from pixels rely on complex multi-term losses, exponential moving averages, pre-trained encoders, or auxiliary supervision."
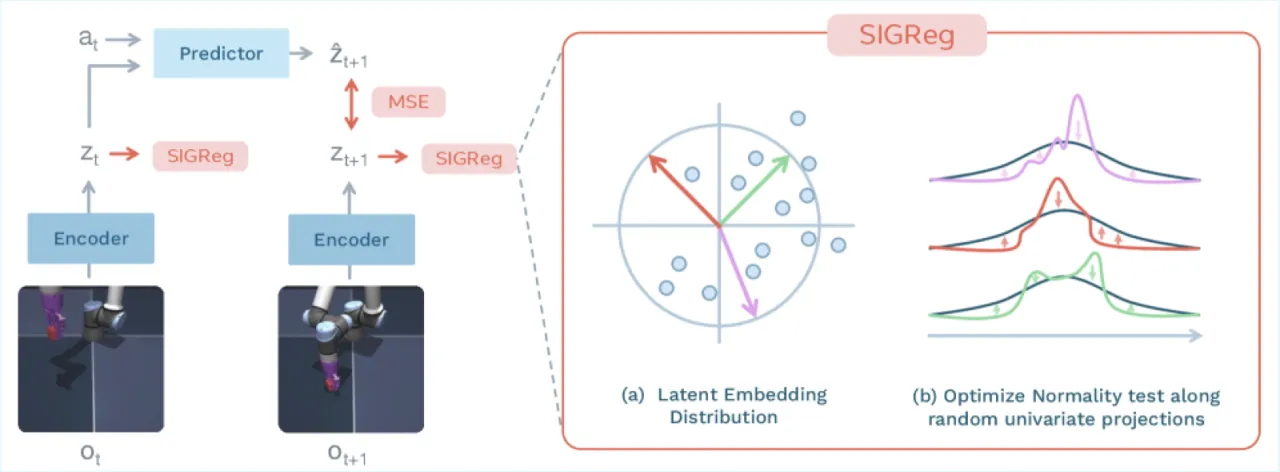
2训练所需损失项数量(vs. PLDM 的 7 项)
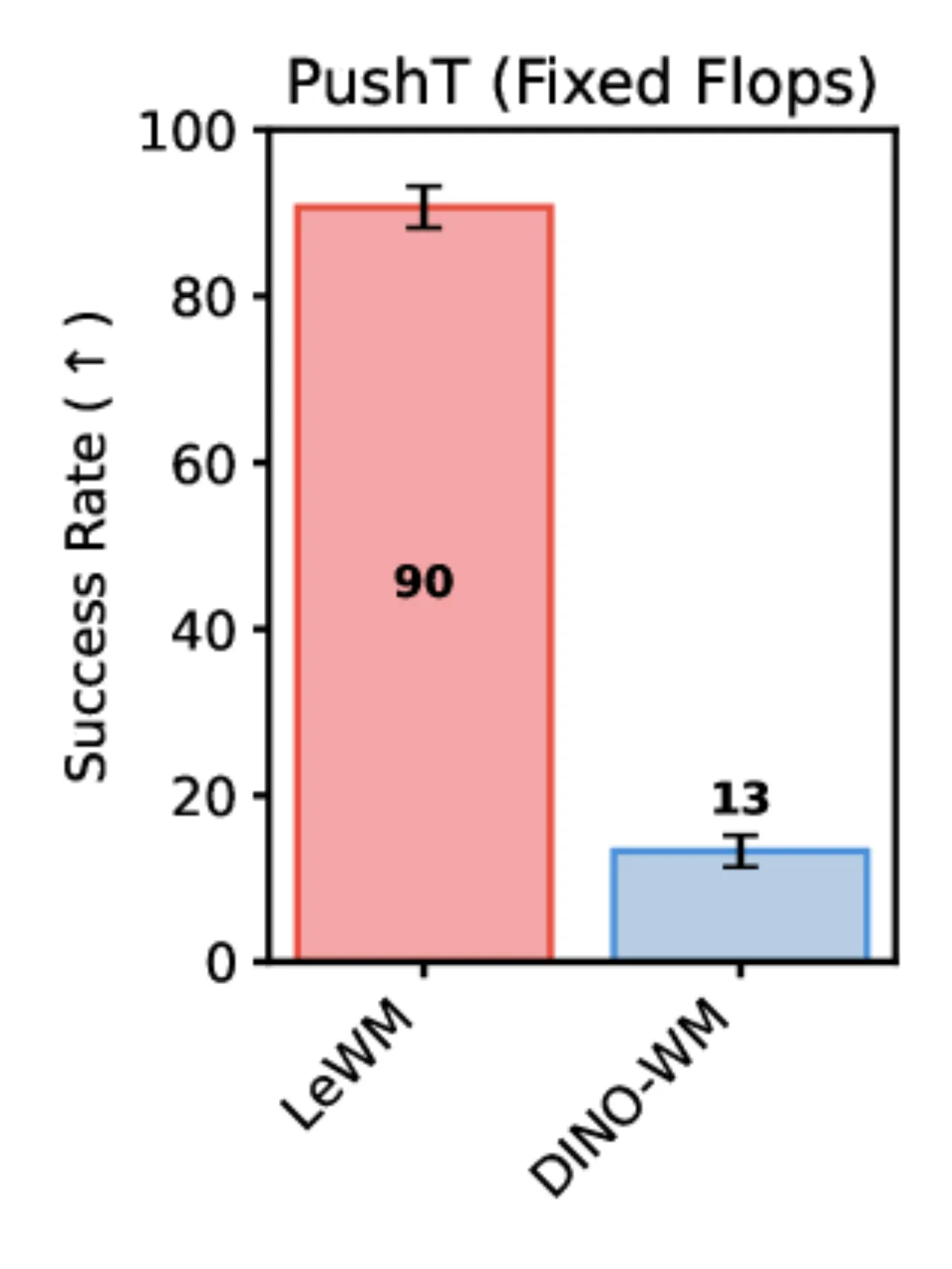
48×相比 DINO-WM 的规划加速比
15M模型参数量
数小时单 GPU 上的训练时长