02 方法
论文从理论角度分析 LeJEPA:在满足独立性、平稳性、加性噪声三条假设的"世界"类中,证明带高斯正则化的对齐目标可线性恢复高斯潜变量,并给出近似可识别性界和最优规划保证。
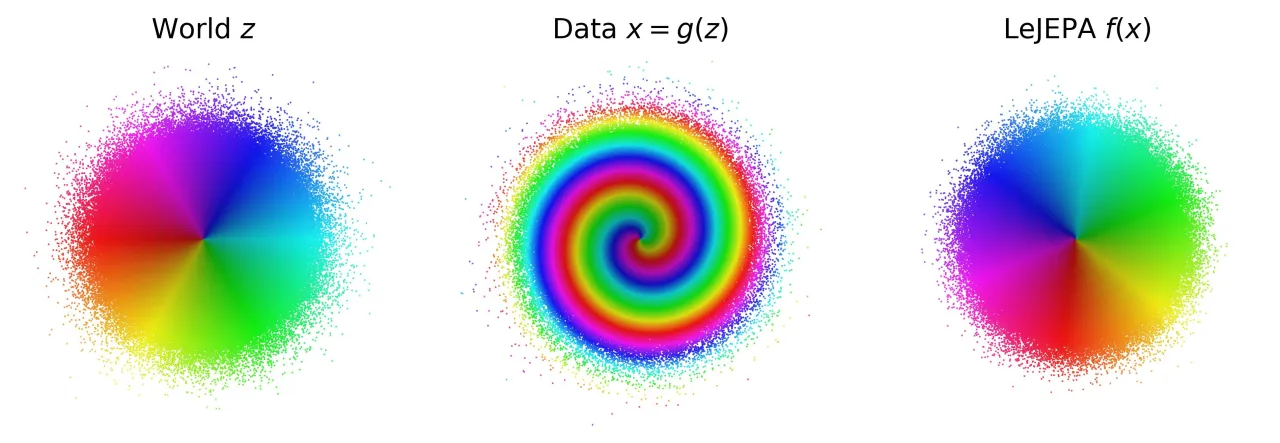
 图 2(示意):LeJEPA 理论框架。(左)世界具有干净的高斯潜变量结构,正样本对高度相关;(中)未知非线性映射产生观测数据;(右)LeJEPA 以"拉近正样本对"(对齐)加"保持嵌入分布为高斯"(SIGReg)两个目标训练编码器——理论证明学到的表示必为真实潜变量的旋转。
图 2(示意):LeJEPA 理论框架。(左)世界具有干净的高斯潜变量结构,正样本对高度相关;(中)未知非线性映射产生观测数据;(右)LeJEPA 以"拉近正样本对"(对齐)加"保持嵌入分布为高斯"(SIGReg)两个目标训练编码器——理论证明学到的表示必为真实潜变量的旋转。
世界模型假设
设世界潜变量 z ∈ ℝⁿ 通过未知非线性映射 g 生成观测 x = g(z)。论文对世界施加三条假设:
- 独立性(Independence):各维潜变量及其转移相互独立,即 p(zᵢ) ⊥ p(zⱼ) 且转移独立。
- 平稳性(Stationarity):两个视图 z, z′ 共享相同的边缘分布 p(z) = p(z′)。
- 加性噪声(Additive noise):转移形如 z′ᵢ = mᵢ(zᵢ) + ηᵢ,噪声 ηᵢ 与 zᵢ 独立。
在高斯潜变量世界中,满足上述假设的唯一转移为 Ornstein–Uhlenbeck(OU)过程:
z′ = ρz + √(1−ρ²)η,η ∼ N(0,Iₙ),η ⊥ z
其中 ρ ∈ (0,1) 控制视图间相关性。
LeJEPA 学习目标
编码器 h = f∘g: ℝⁿ → ℝⁿ 通过最小化如下目标训练:
LeJEPA 目标
minh L(h) = 𝔼[‖h(z′) − h(z)‖²] s.t. h(z) ∼ N(0, Iₙ)
= 对齐损失(Alignment) + 高斯性约束(Gaussianity / SIGReg)
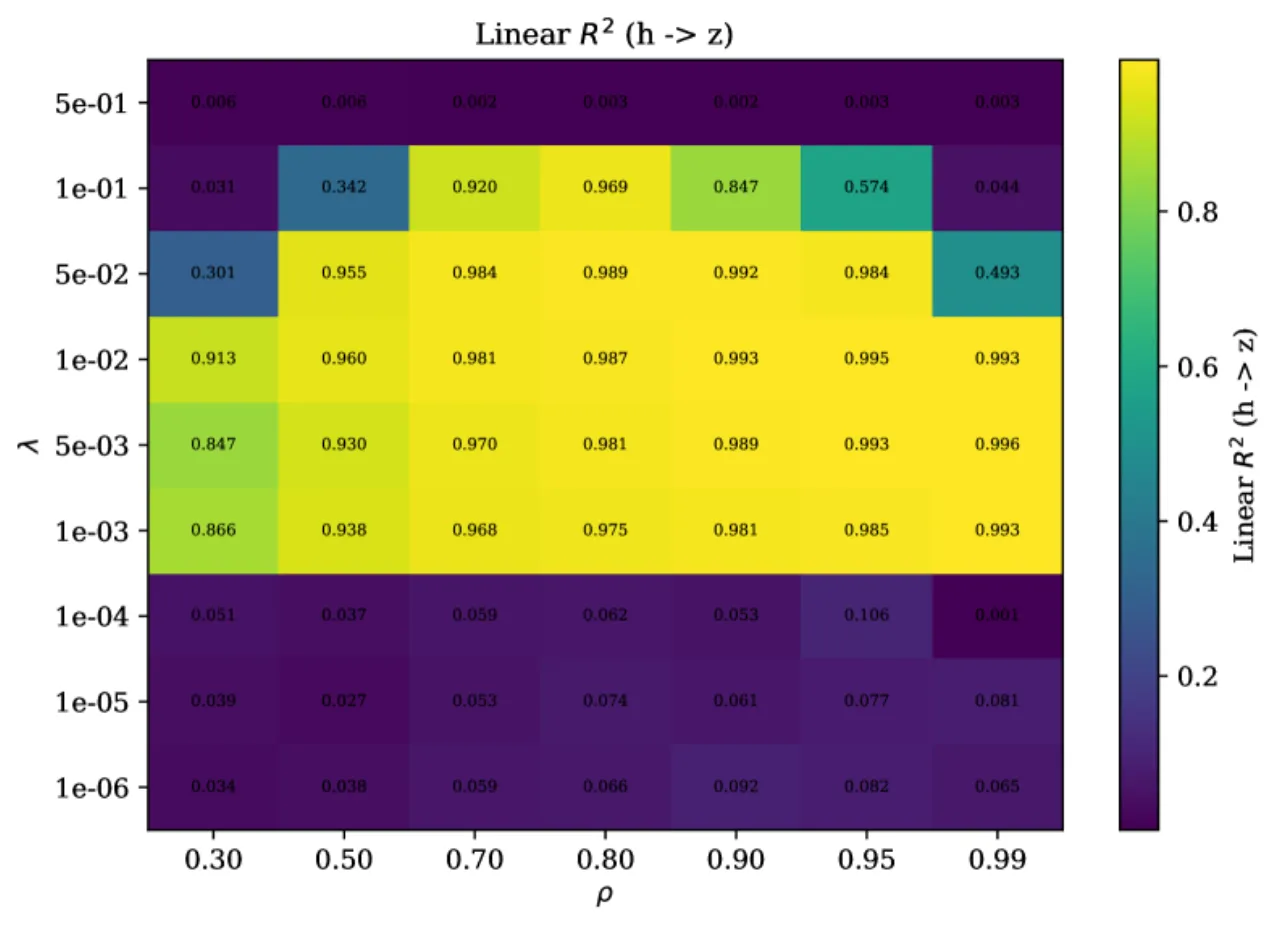
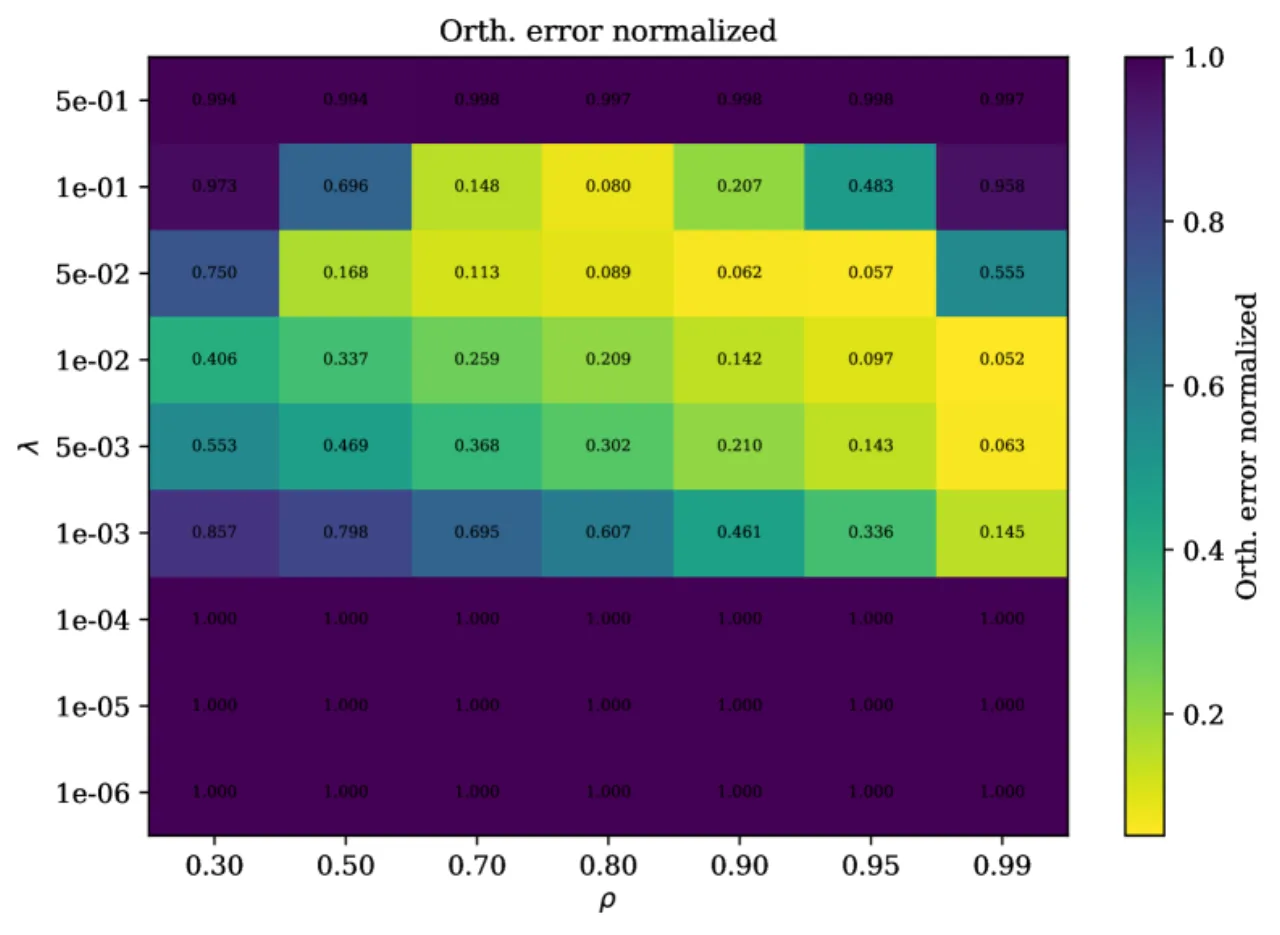
在白化(Cov(h(z)) = Iₙ)条件下,目标化简为最大化正样本对相关之和:L(h) = 2n − 2Σᵢ 𝔼[hᵢ(z′)hᵢ(z)]。
核心理论结果
定理 5.1(线性可识别性 — 正方向)
对于高斯世界,设 h: ℝⁿ→ℝⁿ 满足 h(z)∼N(0,Iₙ),则 L(h) ≥ 2(1−ρ)n,等号成立当且仅当 h(z) = Qz,其中 Q ∈ O(n)(正交矩阵)。证明关键:Hermite 多项式分解使每个非线性度 d≥2 受到严格惩罚,线性映射是唯一最优解。
定理 5.2(高斯唯一性 — 逆方向)
在满足三条假设的所有世界中,若对齐约束加白化的唯一最小化器是线性映射 h(z) = Qz,则 z 必须是高斯分布。证明借助 Sturm–Liouville 谱理论,排除了全部非高斯替代方案。
定理 5.3(近似可识别性)
设近似对齐间隙为 δ,近似白化误差为 ε,令 D = δ / (2ρ(1−ρ))。则存在 Q ∈ O(n) 使得:
𝔼[‖h(z) − Qz‖²] ≤ D + (ε + D)²
恢复误差随 δ、ε 连续平滑退化。
定理 5.4(最优潜空间规划)
设 h(z) = Qz(Q ∈ O(n)),对任意旋转不变代价函数的有限水平最优控制问题,有 V̂*(h(z₀)) = V*(z₀),即在学到的潜空间与真实潜空间中规划等价。
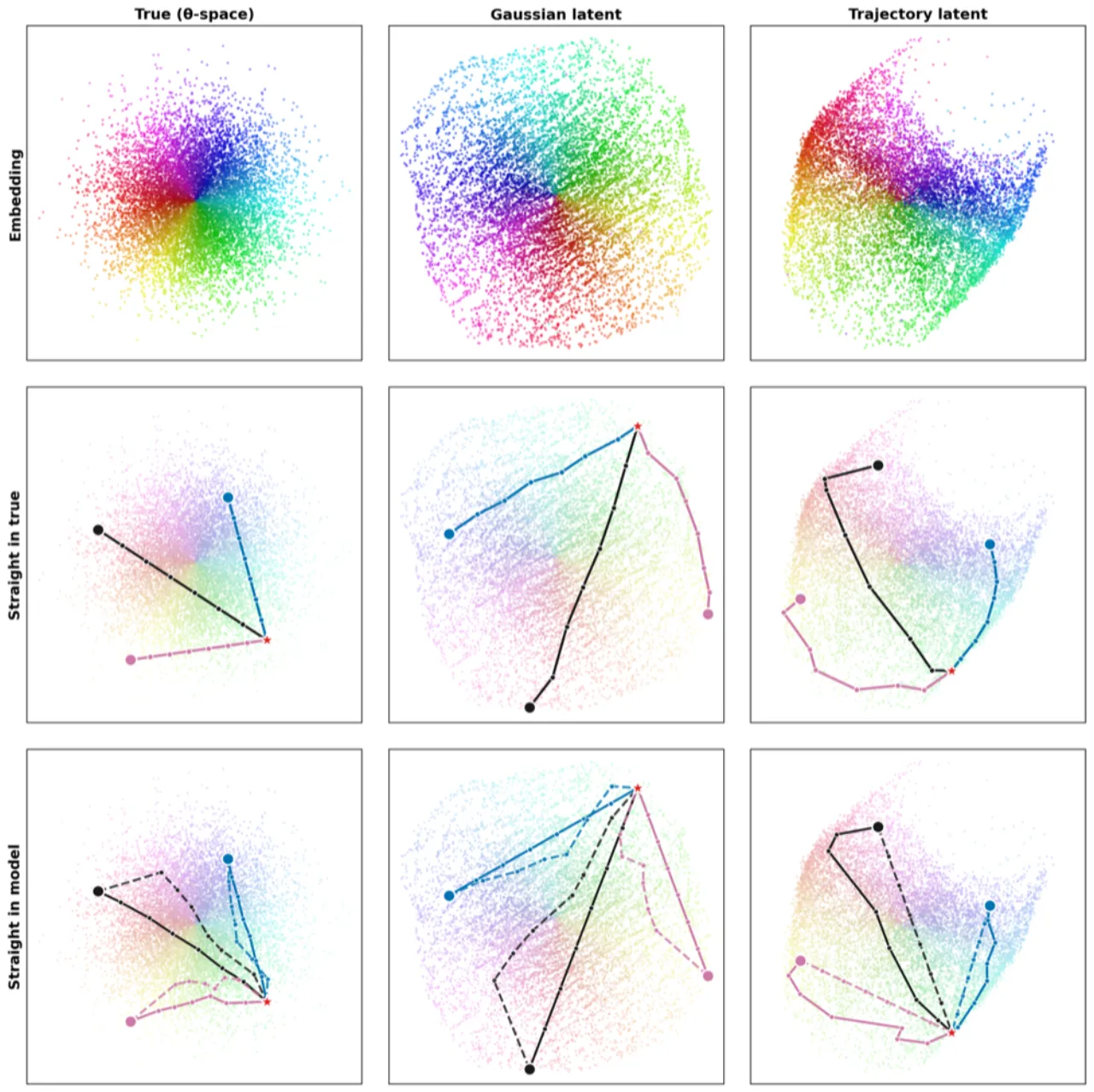
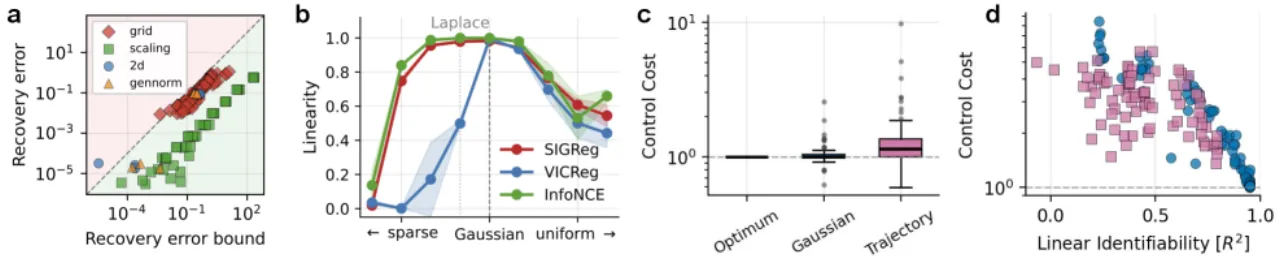 图 3:2D 模拟实验(图示)。颜色编码真实潜变量的极坐标角度与半径。三种非线性混合(抛物线剪切、正弦剪切、RealNVP 耦合层)下,LeJEPA 均将各向同性高斯结构恢复至旋转等价,与定理 5.1 吻合。
图 3:2D 模拟实验(图示)。颜色编码真实潜变量的极坐标角度与半径。三种非线性混合(抛物线剪切、正弦剪切、RealNVP 耦合层)下,LeJEPA 均将各向同性高斯结构恢复至旋转等价,与定理 5.1 吻合。