01 动机 Motivation
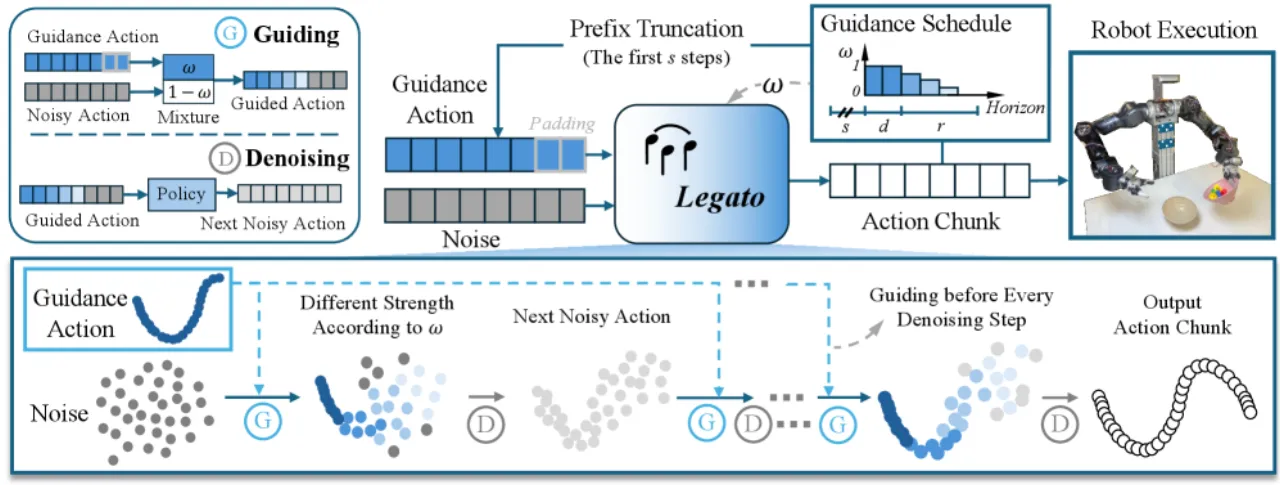
Action chunking 是让大型 VLA 模型在机器人上实时运行的关键技术——每次推理预测一段动作序列(chunk),避免逐帧调用昂贵模型。然而,当前一个 chunk 执行完毕、新的 chunk 接续时,两段轨迹之间往往出现明显的跳变与不连续。
问题一:chunk 边界不连续
原始 action chunking 的执行在 chunk 边界处会产生速度/加速度跳变,机械臂抖动明显,影响任务成功率。
问题二:RTC 存在外部 patch 缺陷
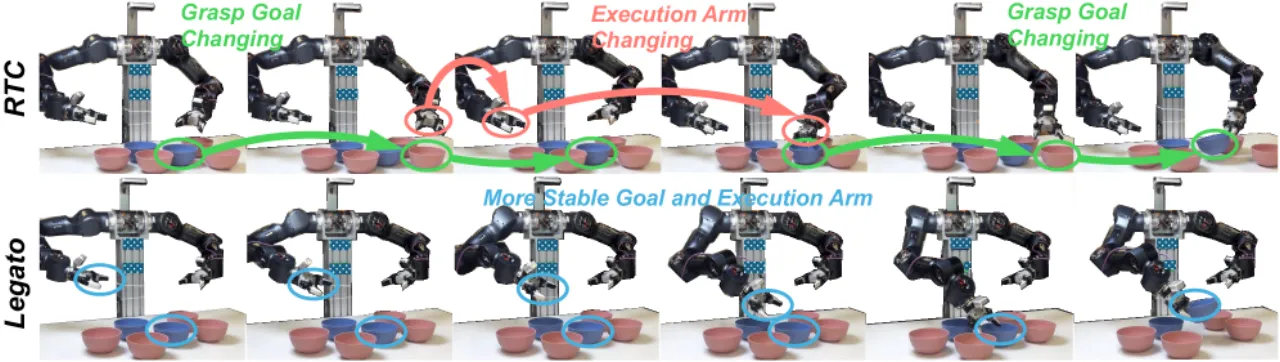
Real-Time Chunking (RTC) 在推理时做 inpainting,将已执行动作作为约束注入去噪过程。但它与训练目标不一致,导致虚假模态切换(spurious multimodal switching)——机械臂在不同抓取目标和执行臂之间反复横跳,产生大量犹豫动作。
"RTC applies inference-time inpainting... leading to spurious multimodal switching and trajectories that are not intrinsically smooth."
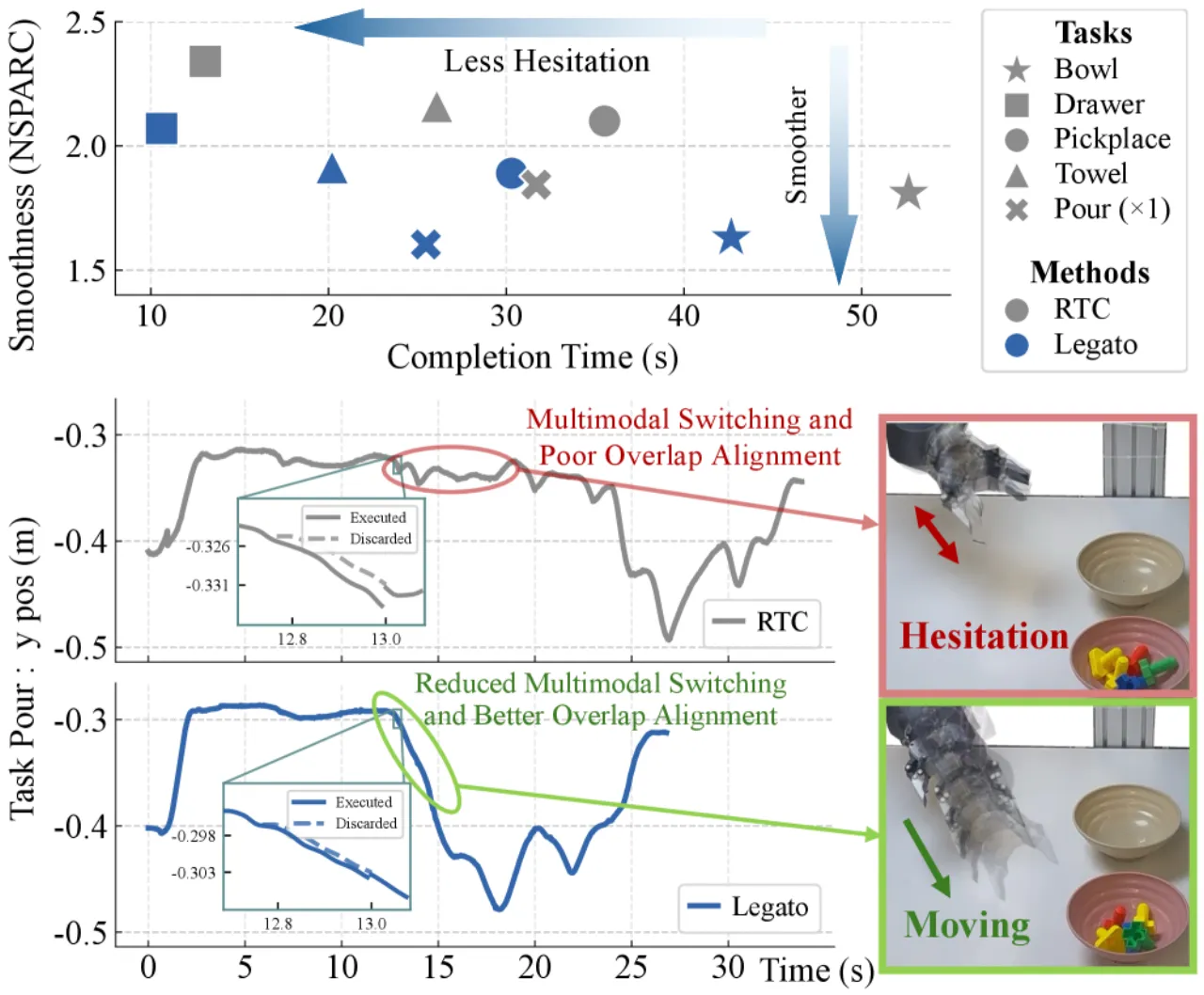
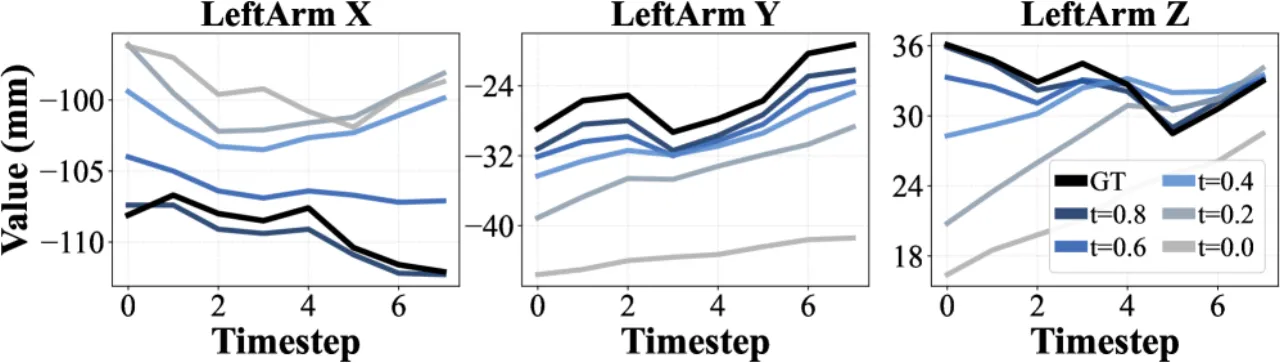
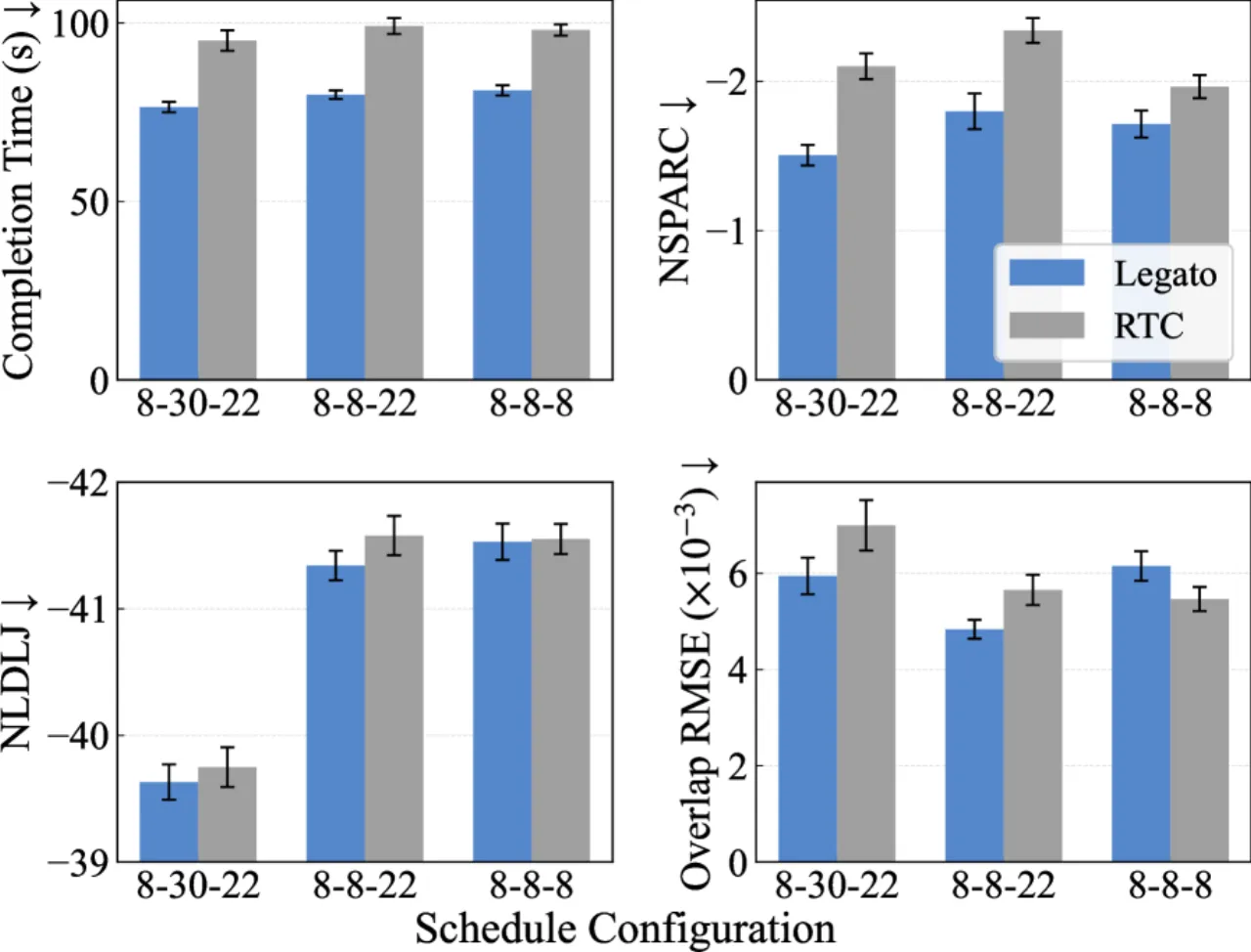
~10%轨迹平滑度提升(NSPARC↓)
~10%任务完成时间缩短
5项真实双臂操作任务
<31%Overlap RMSE 降低(Pour 任务)