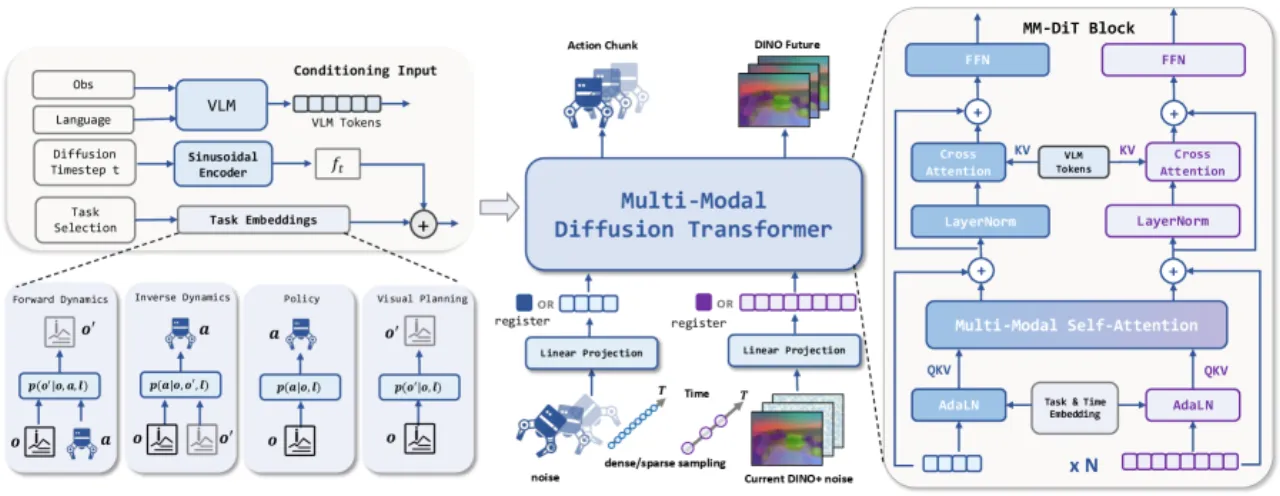
01 动机
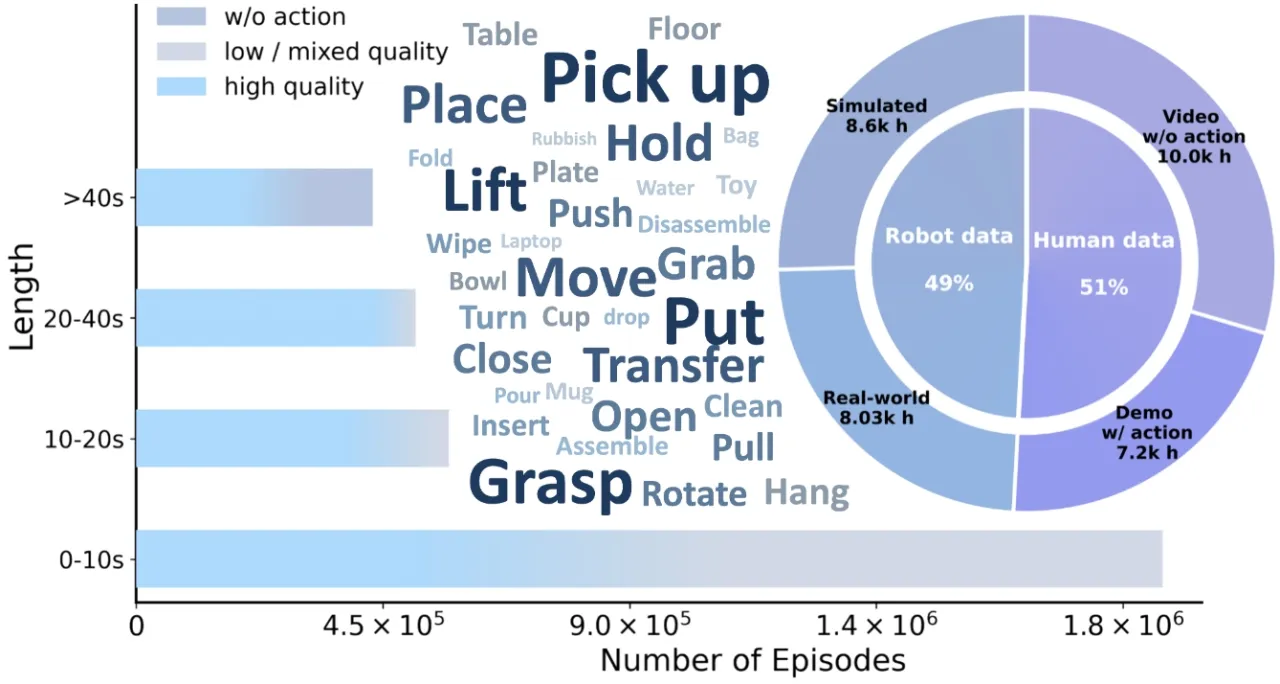
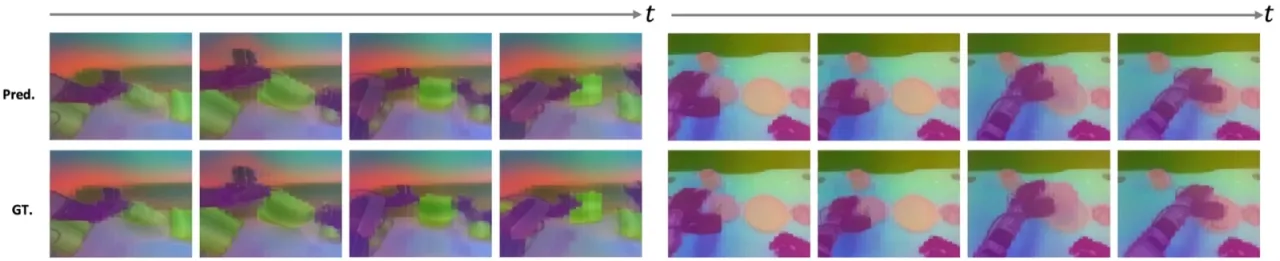
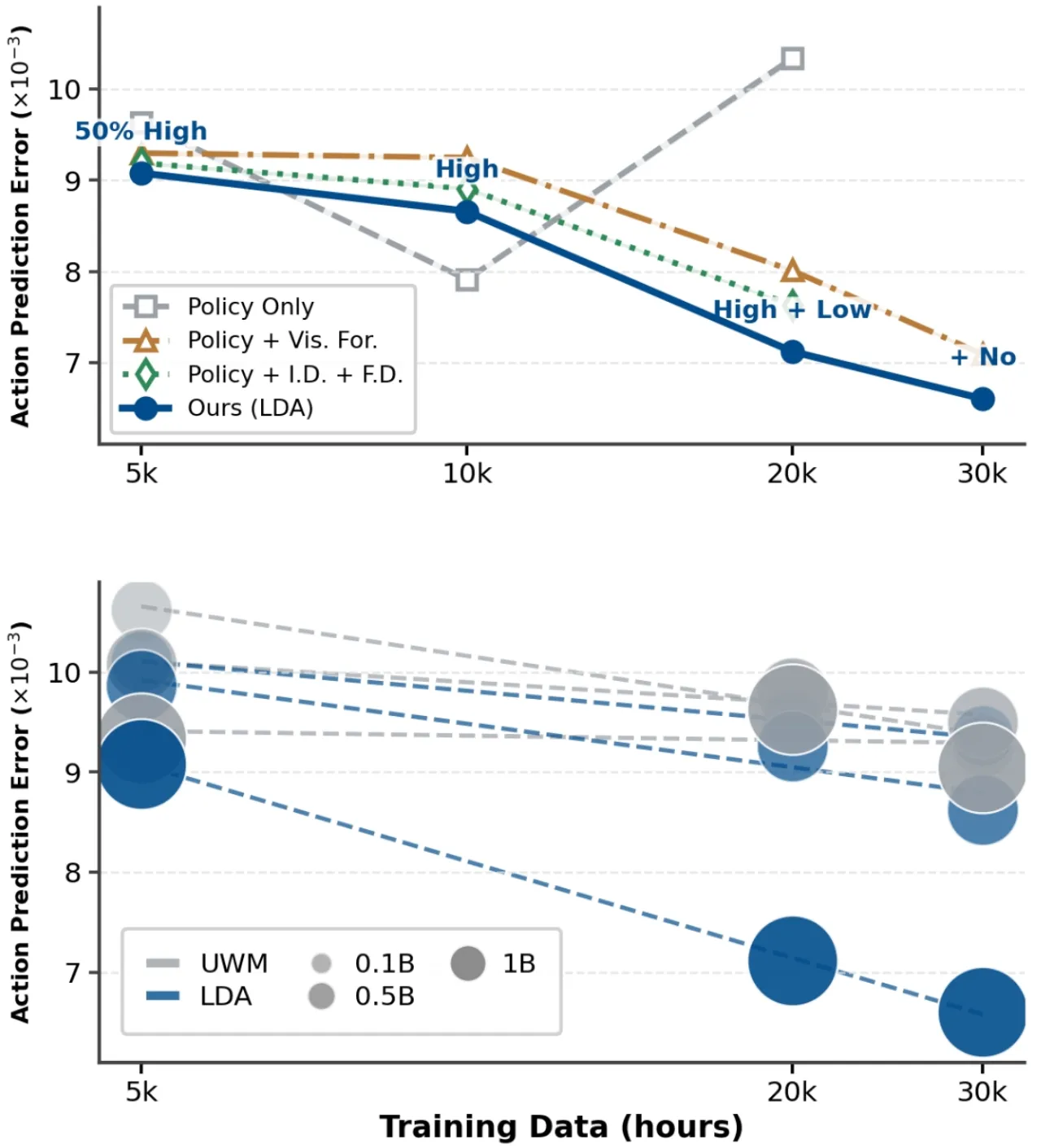
现有机器人基础模型主要依赖行为克隆(behavior cloning),无法充分利用异质具身数据中蕴含的可迁移动力学知识;统一世界模型(Unified World Model)虽然有潜力,却受限于"coarse data usage and fragmented datasets"。如何将数十万小时的人类视频、低质量轨迹与高质量机器人轨迹统一纳入训练,是提升可扩展性的核心挑战。
"Existing methods primarily rely on behavior cloning, which discards transferable dynamics knowledge embedded in heterogeneous embodied data."
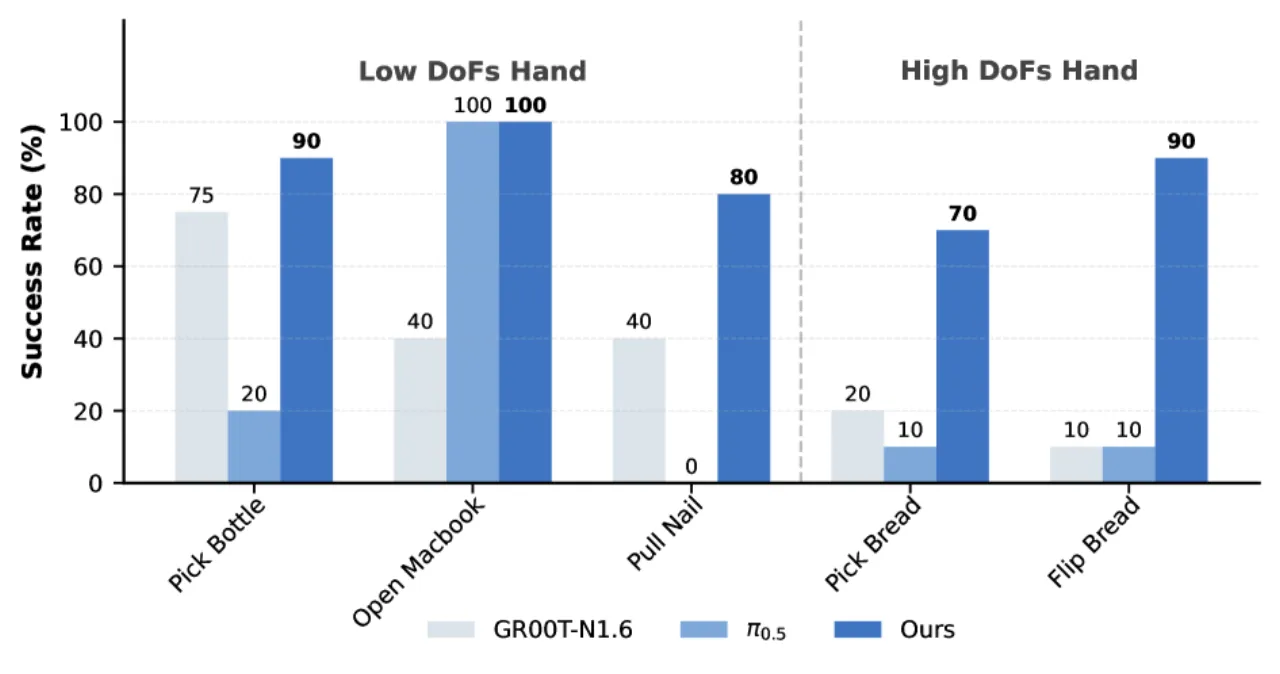
+21%contact-rich 操作相对 π0.5 提升
+48%灵巧操作相对 π0.5 提升
+23%长视野任务相对 π0.5 提升
30k+EI-30k 数据集小时数