02 方法
LPS 分三步:① 以光流为动作表征在多形态数据上预训练视觉世界模型;
② 用少量目标形态演示微调世界模型并训练 Robust Value Function;
③ 推理时对 diffusion policy 采样的多条动作规划进行隐空间评估,选取价值最高的计划执行。
Flow-as-Action:形态无关的世界模型预训练
传统世界模型以具体机器人动作(如关节角度或末端位姿)为条件,无法直接跨形态迁移。
LPS 将光流替换为动作输入:卷积编码器将光流场压缩为 n 维向量(n 等于目标形态的动作空间维度),
迫使网络捕获与形态无关的显著运动特征,同时抑制噪声和形态差异。
该设计使预训练数据可来自任意机器人甚至人类演示。
目标形态微调与 Robust Value Function
在获得少量目标形态(如 Franka)演示后,将光流编码器替换为归一化的机器人真实动作,
同时联合训练世界模型与价值函数。
价值函数需处理 distribution shift 问题——推理时策略访问的状态可能偏离训练分布。
为此,作者设计了Robust Value Function ,同时在专家演示状态和策略访问状态上训练,
并引入 cosine similarity 奖励惩罚偏离专家轨迹的行为:
"rt:t+h′ = rt:t+h + (sim(st:t+h , st:t+h′ ) − 1) / 2"
其中 st:t+h 为专家隐状态序列,st:t+h′ 为策略在世界模型中展开的状态。
该奖励促使价值函数在 out-of-distribution 状态下仍能给出保守估计,避免高估偏差。
推理时隐空间策略引导(Latent Policy Steering)
给定当前观测,从 diffusion policy 采样 B 条候选动作规划,规划长度为 h 。
世界模型将每条规划在隐空间中前向展开,得到未来隐状态序列,
再由价值函数以加权平均(未来时刻权重更大)计算规划级价值。
执行价值最高的规划前 1 步后重新规划,实现滚动决策。
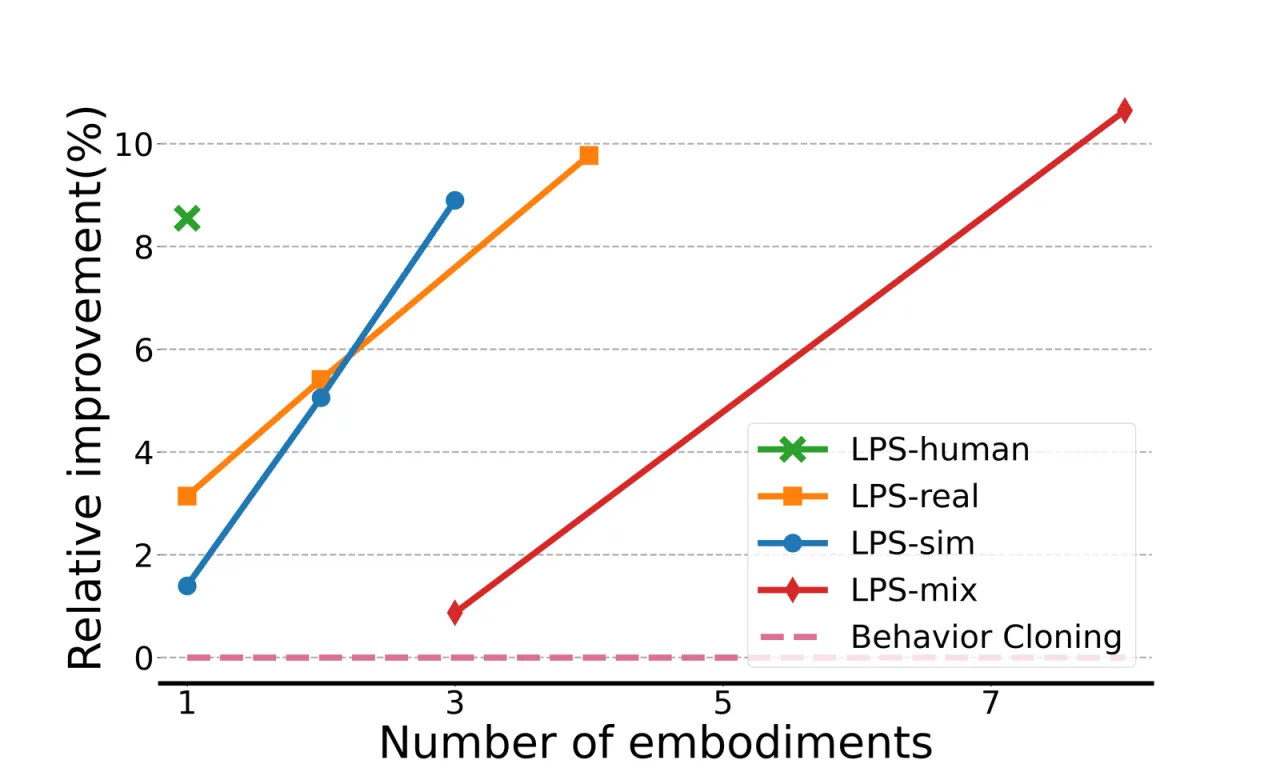
图 3:形态数量对性能的影响(Embodiment Scaling)。
在 Robomimic 上评估不同预训练形态组合(IIWA、UR5e、Kinova3)对 Franka 目标策略的提升效果。
随着预训练混合数据中形态种类增加,LPS 性能稳步提升,验证了多形态预训练的可扩展性。