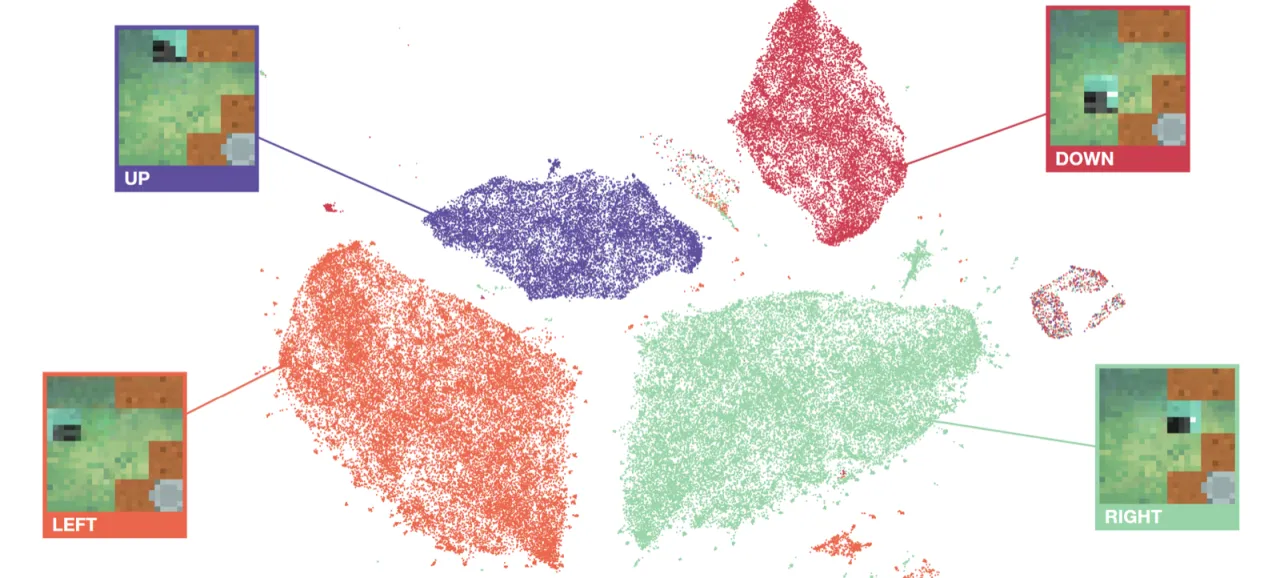
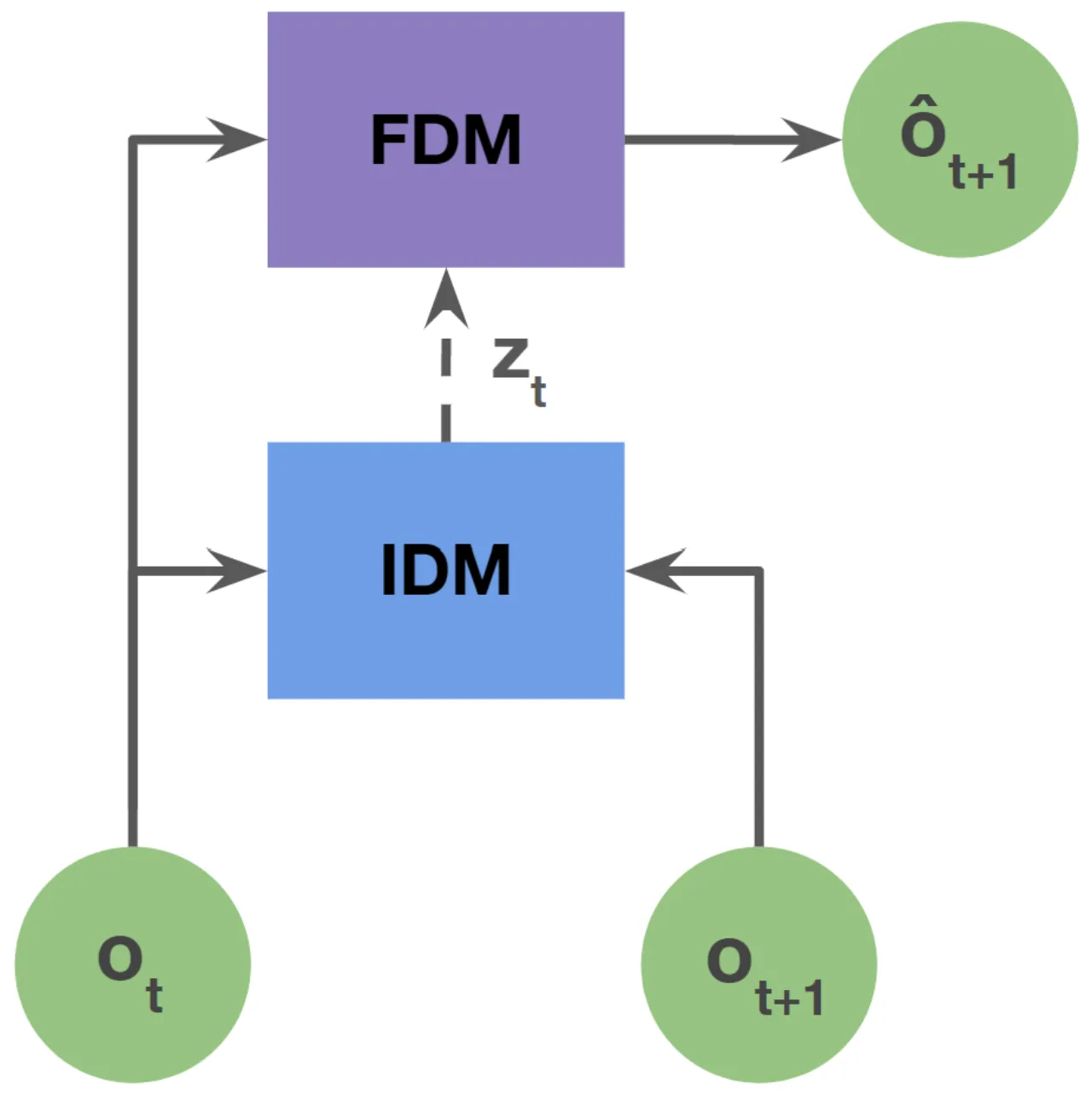
IDM 以 (ot, ot+1) 为输入,输出连续的 latent action 向量,再经过 VQ 离散化。VQ 作为信息瓶颈的关键作用在于:若无约束,IDM 可以直接"抄写"未来帧信息绕过真正的动作推断;VQ 压缩迫使模型只保留状态转变中最关键的那部分信息,即
"the IDM learns to encode only the difference between ot+1 and ot…rather than full information about ot+1."
实验表明,去掉 VQ 后(no-VQ ablation)虽然 FDM loss 更低,但下游策略性能显著下降,印证了 VQ 的不可或缺性。
"Actions that have a delayed effect in observations will be predicted to take place with the same delay."——若某个动作在视觉上的效果延后若干帧才出现,IDM 学到的 latent action 会对应延迟后的可见变化,而非动作本身发生的时刻。作者指出可通过多时间步架构(multi-timestep architectures)加以缓解。
环境随机性(Stochasticity)
"Significant stochasticity can make it difficult for the IDM to compress the useful bits of information among the noise."——高随机性环境中,状态转变中的噪声与真实动作信号混杂,IDM 难以准确分离,导致 latent action 质量下降。更大的数据集可部分缓解此问题。
大规模训练的扩展挑战(Scaling Challenges)
"Training on much larger datasets…would require scaling up the model architecture, which introduces new challenges in balancing the strength of the FDM and the capacity of latent actions representations."——在互联网规模视频数据上训练需要更大的模型,但 FDM 能力与 latent action 容量之间的平衡尚未得到充分研究,是迈向通用视频预训练策略的开放问题。