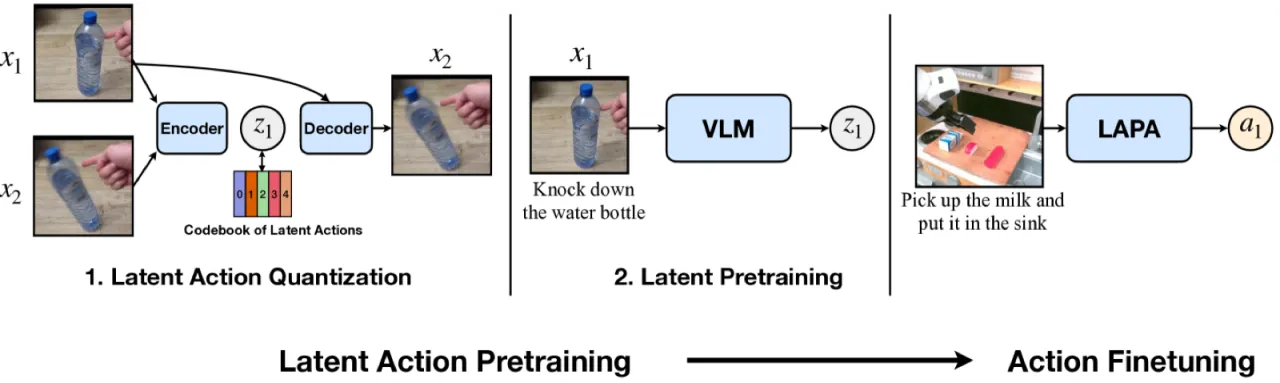
01 动机
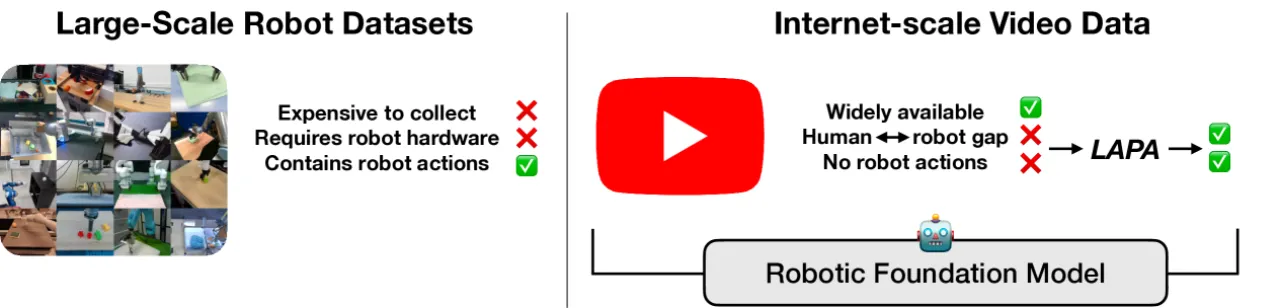
现有 Vision-Language-Action (VLA) 模型的预训练依赖于机器人遥操作收集的有标注动作数据, 这使得可用数据规模极为有限。互联网上存在海量的人类操作视频(如 YouTube、Something-Something 等), 却因缺少机器人动作标签而无法直接用于 VLA 预训练。 如何利用这些无标注视频数据,是扩展机器人基础模型的核心瓶颈。
"We introduce LAPA, an unsupervised method for pretraining Vision-Language-Action (VLA) models without ground-truth robot action labels."
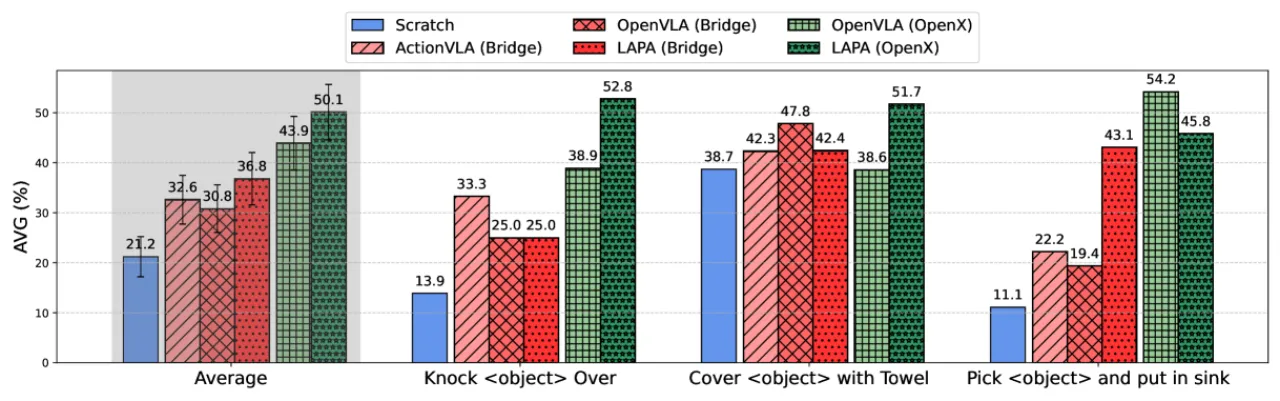
50.1%LAPA (Open-X) 真实机器人平均成功率
43.9%OpenVLA (Open-X) 对比基准成功率
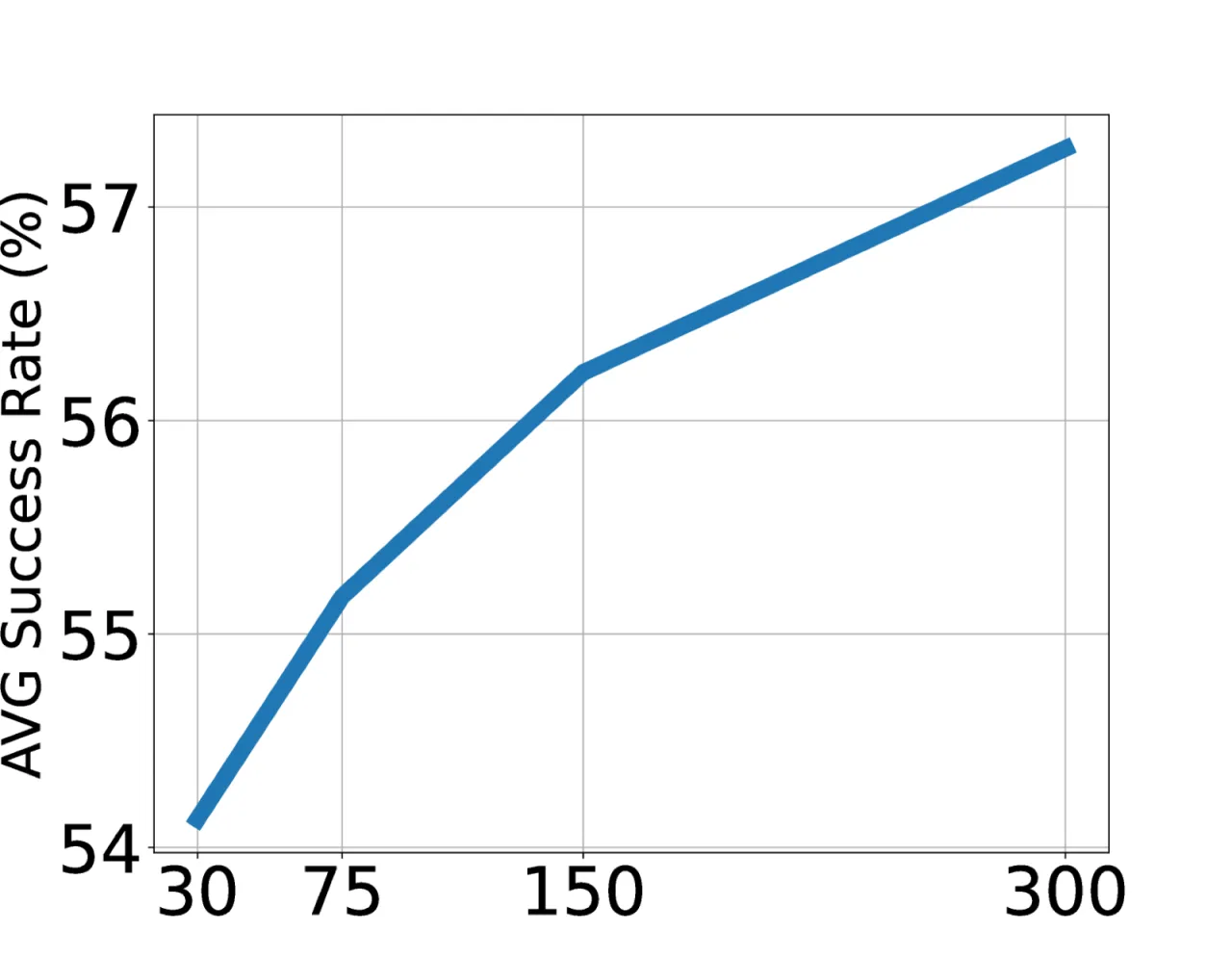
30×LAPA 相对 OpenVLA 的预训练效率提升
272hLAPA 预训练所用 H100 GPU 时(OpenVLA 需 21,500 A100 时)