01 动机
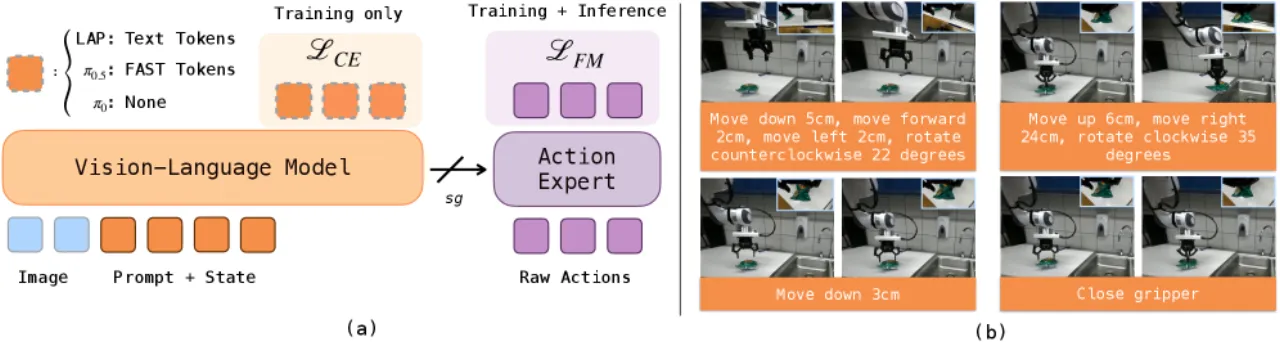
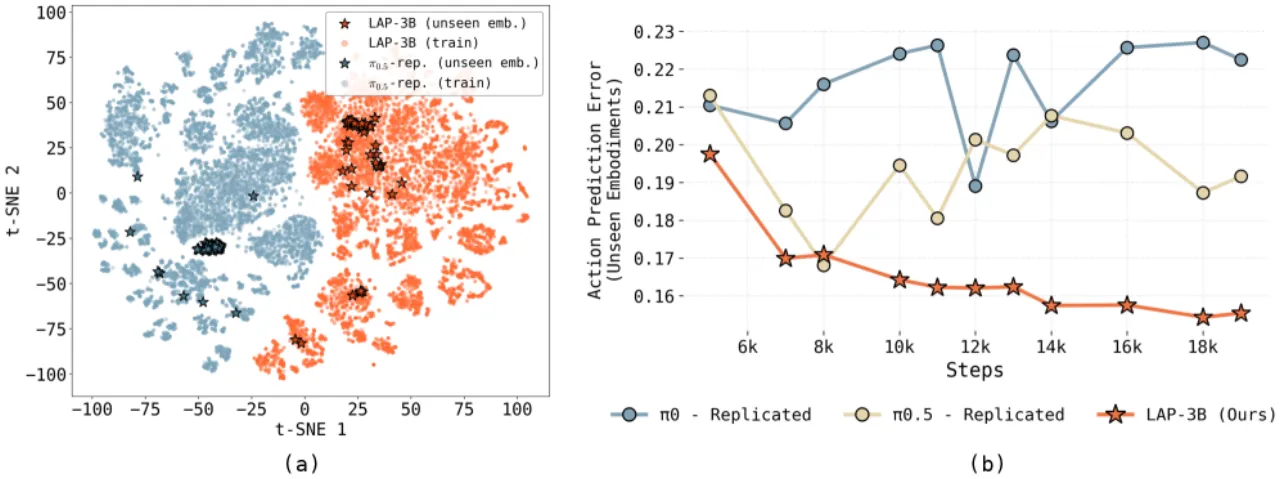
尽管 VLA 模型已在多机器人混合数据集上大规模预训练,"state-of-the-art VLAs still rarely function zero-shot on new robots"——哪怕只是换了一个夹爪或调整了摄像头位置,模型就会失效。问题根源在于:现有方法将 VLM 微调为直接预测连续动作或离散控制 token,这造成了"distributional mismatch",因为 VLM 的预训练从未接触过电机级高频控制信号,也无法从这些信号中提取任何跨机器人通用的语义结构。
"Zero-shot cross-embodiment transfer depends critically on how we adapt a pre-trained VLM for motor control."
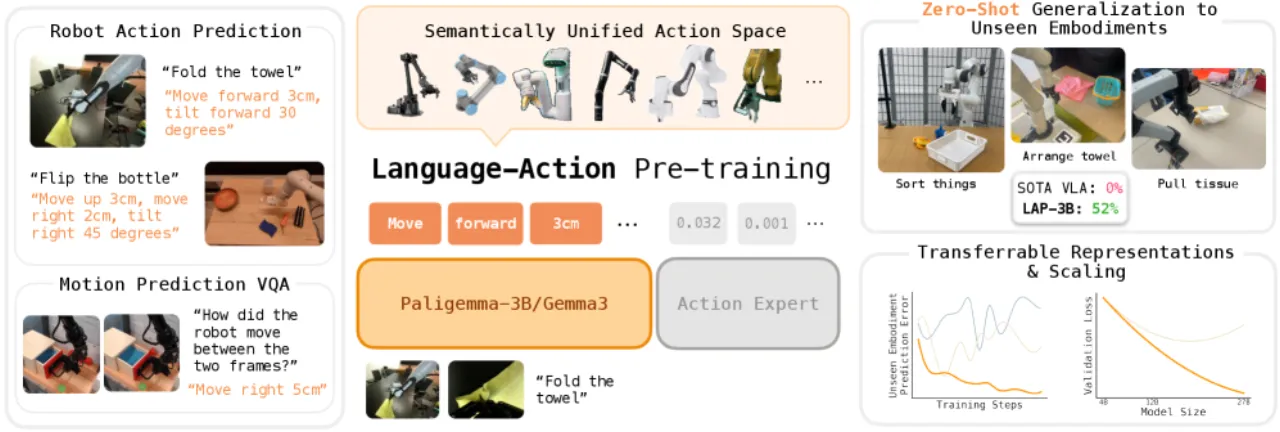
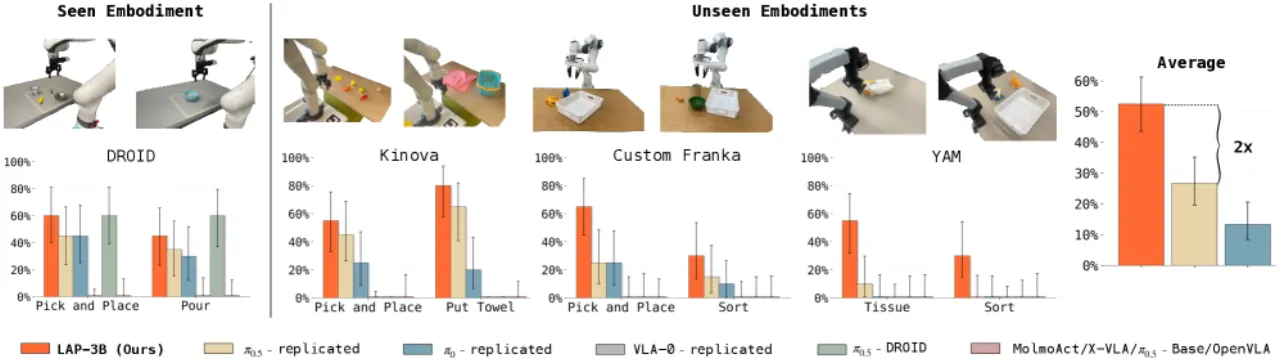
>50%3 个新机器人的平均零样本成功率
~2×超越最强 VLA 基线的提升幅度
2.5×少于基线所需演示数量的微调效率提升
0%所有现有开源 VLA 在未见机器人上的零样本成功率
现有的五个开源 VLA(π0.5-DROID、π0.5-Base、X-VLA、MolmoAct、OpenVLA)在未见机器人上均完全失效,成功率均为 0%。这表明简单地增大数据规模并不能解决跨机器人泛化问题,关键在于动作表示的选择。