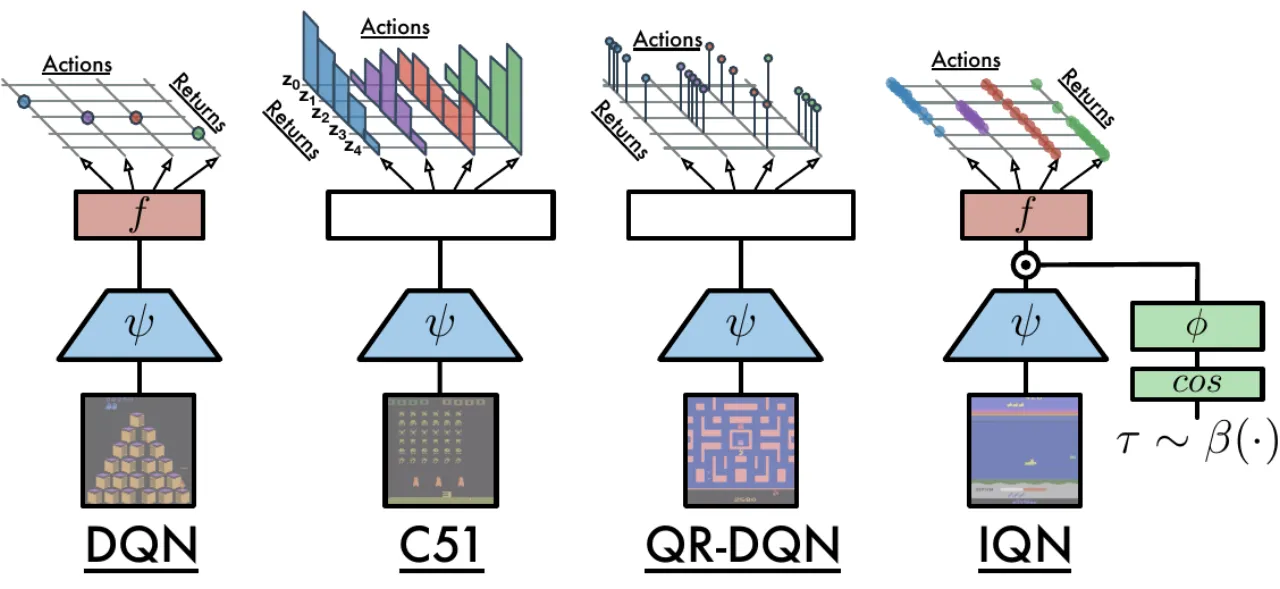
02 方法 Method
IQN 将 DQN 的标量 Q 网络替换为一个接受 (状态 x, 动作 a, 分位数水平 τ) 三元输入的量化函数近似器,输出分位值 Z_τ(x,a)。结合任意基础分布(如 U([0,1]))即可在推断时对回报分布进行任意粒度的采样。
核心公式:隐式量化函数
设 Z_τ(x,a) := F⁻¹_{Z(x,a)}(τ) 为回报分布在分位数 τ 处的逆 CDF 值。IQN 通过以下网络结构近似该量化函数:
Z_τ(x, a) ≈ f(ψ(x) ⊙ φ(τ))_a
其中:
- ψ(x):DQN 中原有的卷积特征提取器,输出 d 维向量
- φ(τ):τ 的嵌入函数,将 [0,1] 中的标量映射为 d 维向量
- ⊙:element-wise(Hadamard)乘积,迫使卷积特征与 τ 嵌入早期交互
- f:后续全连接层,输出各动作的分位值
作者最终采用的 τ 嵌入公式(embedding dimension n = 64)为:
φ_j(τ) := ReLU(Σ_{i=0}^{n-1} cos(πiτ) · w_{ij} + b_j)
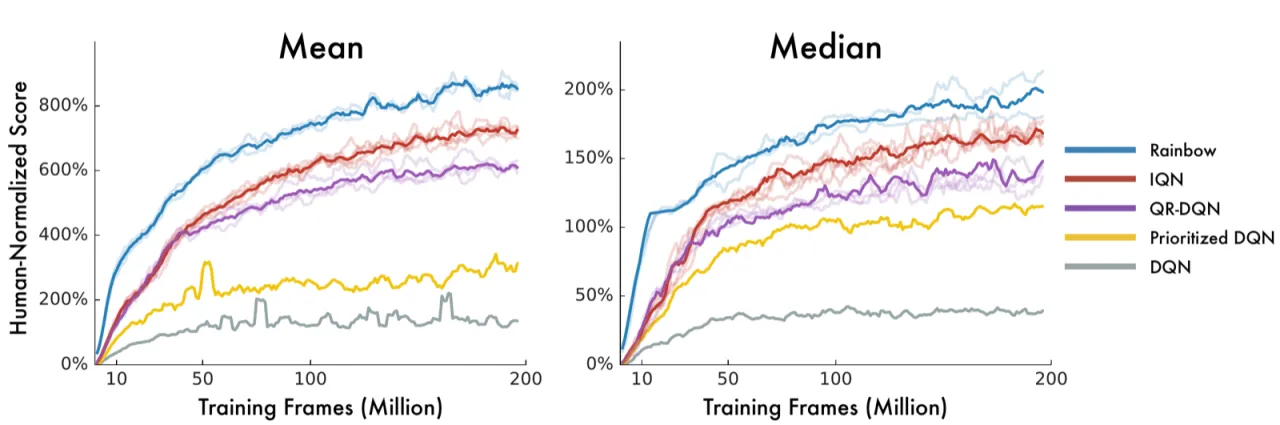
即对 τ 计算余弦基函数特征后经线性变换和 ReLU 激活。消融实验表明,多种架构变体(MLP embedding、concatenation、residual fusion 等)均能稳定超过 QR-DQN 基线,整体对超参数选择鲁棒。
损失函数
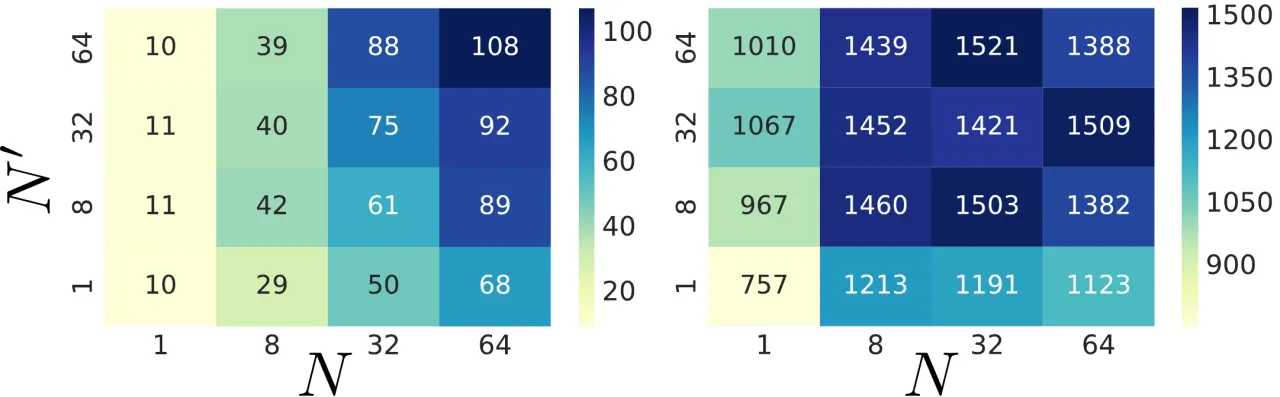
训练时从 U([0,1]) 中分别采样 N 个 τ 和 N' 个 τ',对所有 N×N' 对 TD 误差计算 Huber quantile regression loss:
L(x_t, a_t, r_t, x_{t+1}) = (1/N') Σ_{i=1}^{N} Σ_{j=1}^{N'} ρ^κ_{τ_i}(δ_t^{τ_i, τ_j'})
其中 δ_t^{τ,τ'} = r_t + γ Z_{τ'}(x_{t+1}, π_β(x_{t+1})) − Z_τ(x_t, a_t) 为采样 TD 误差,ρ^κ_τ 为 Huber 分位数损失。
风险敏感策略(Risk-Sensitive Policies)
IQN 的隐式分布表示天然支持 distortion risk measure:给定连续单调函数 β:[0,1]→[0,1](称为 distortion risk measure),只需将策略中 τ 的采样分布从 U([0,1]) 替换为 β 变换后的分布即可实现风险偏好调整:
π_β(x) = argmax_{a} E_{τ~U([0,1])} [Z_{β(τ)}(x, a)]
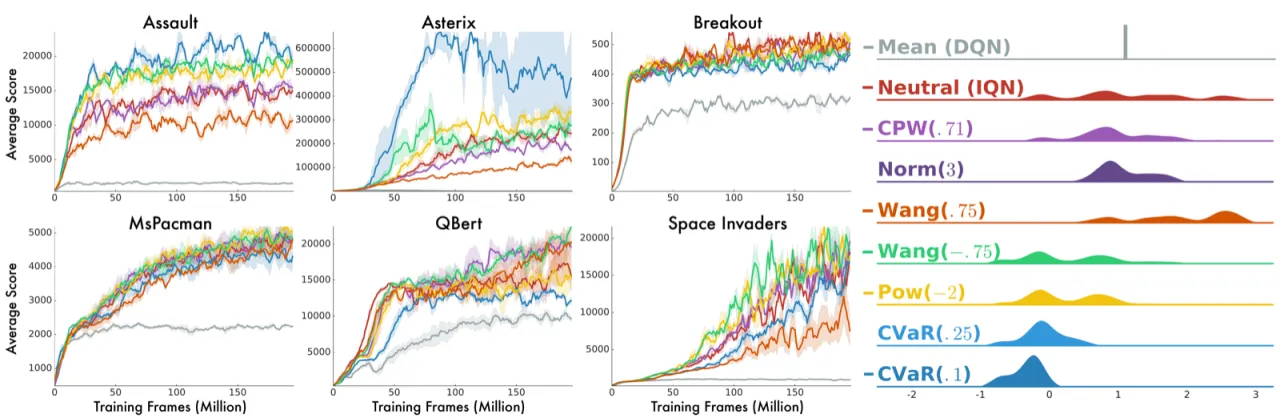
论文考察了四种 distortion risk measure:CPW(cumulative prospect theory 中的概率权重函数,η=0.71 最接近人类行为)、Wang、Pow 和 CVaR,涵盖风险厌恶和风险追求两类策略。