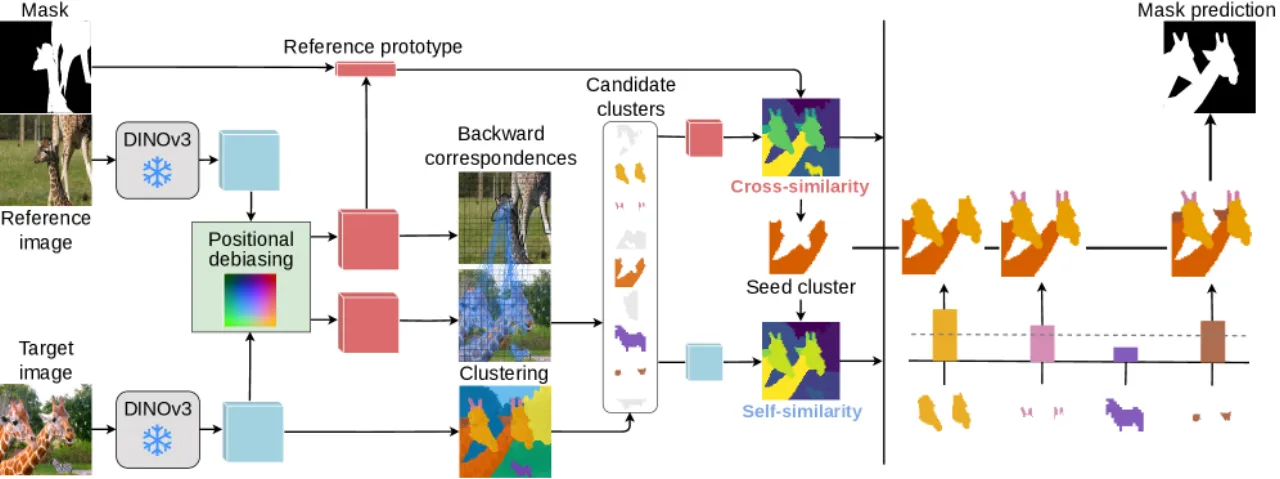
02 方法(Method)INSID3 流程共四步:① Positional Debiasing (去除位置偏差),② Fine-grained Clustering (聚类分解目标图像为连贯区域),③ Seed-cluster Selection (通过 backward correspondence 筛选候选簇,再用 cross-image similarity 定位种子簇),④ Cluster Aggregation (结合 cross-similarity 与 self-similarity 生成最终 mask)。
Figure 3. INSID3 方法概览。参考图与目标图的 DINOv3 特征首先经过 positional debiasing,再对目标图做 agglomerative clustering 得到结构化分解;通过 backward correspondence 保留候选簇,再由参考区域原型定位 seed cluster;最终融合 cross-image similarity 与 self-similarity 扩展 seed cluster 得到预测 mask。
① Positional Debiasing(位置偏差去除)
DINOv3 特征存在显著的 positional bias:即便使用均匀低复杂度图像("noise images"),提取的特征仍保留明显的空间结构,使得跨图像的相似度图被位置信息污染。INSID3 在噪声图像上提取特征矩阵 Fnoise ∈ ℝP×D ,对其做 PCA 取前 s 个主成分构成位置子空间 B ,随后将参考图和目标图特征投影到该子空间的正交补空间:
F̃ = F(1D − BB⊤ ) ,从而在不需要任何训练的情况下有效解耦语义信息与位置信息。
Figure 2. DINOv3 密集特征的区域级分组。每对图像展示原图(左)与对 DINOv3 特征做 agglomerative clustering 后的聚类图(右)——自然形成语义连贯的区域分解,为后续 in-context segmentation 提供结构化表示。
② Fine-grained Clustering(细粒度聚类)
对去偏后的目标图特征 F̃t 做 agglomerative clustering,聚类粒度由阈值 τ 控制(论文设置 τ = 0.6)。聚类结果将目标图分解为一组空间连贯的候选区域 {Gk },其空间结构对 part 和个性化分割尤为关键。
③ Seed-cluster Selection(种子簇选择)
先以 backward correspondence 在去偏空间中筛选候选簇 Ccand (即参考区域中有足够多 patch 将其最近邻落在该簇内的候选集合);再计算各候选簇原型 p̃k t 与参考区域原型 p̃r 的 cross-image similarity score:sk cross = ⟨p̃k t , p̃r ⟩ ,取得分最高的簇作为 seed cluster G*。
④ Cluster Aggregation(簇聚合)
以 seed cluster 为锚点,将其余候选簇中语义相近的区域融入最终预测。融合 cross-image similarity(语义对齐)与 self-similarity(与 seed cluster 的内部亲和度)两项得分,阈值 α = 0.2 控制合并力度;最终 mask 经 CRF refinement 提升边界精度。