02 方法iMF 在三个层面对原始 MeanFlow 进行了系统改进:将训练目标重构为 v-loss(velocity loss)、引入灵活的 guidance 条件化、以及用 in-context conditioning 替换参数密集的 adaLN-zero。
改进一:MeanFlow as v-loss(速度损失重构)
原始 MF 的训练目标可以分解为:对平均速度 u(z_t) 的预测,加上一个关于时间导数的修正项。通过引入 MeanFlow 恒等式,可以将目标重写为对瞬时速度 v(z_t) 的回归:
V_θ(z_t) ≜ u_θ(z_t) + (t−r) · JVP_sg(u_θ; v_θ)
其中 JVP(Jacobian-Vector Product)在 stop-gradient(sg)下计算,确保训练目标仅依赖当前输入 z_t,而与网络参数无关,构成合法的监督回归。
论文提出两种实现方式:Boundary condition (令 v_θ = u_θ(z_t, t, t),无额外参数)和 Auxiliary head (独立的 v-head,共享主干参数,效果更优)。
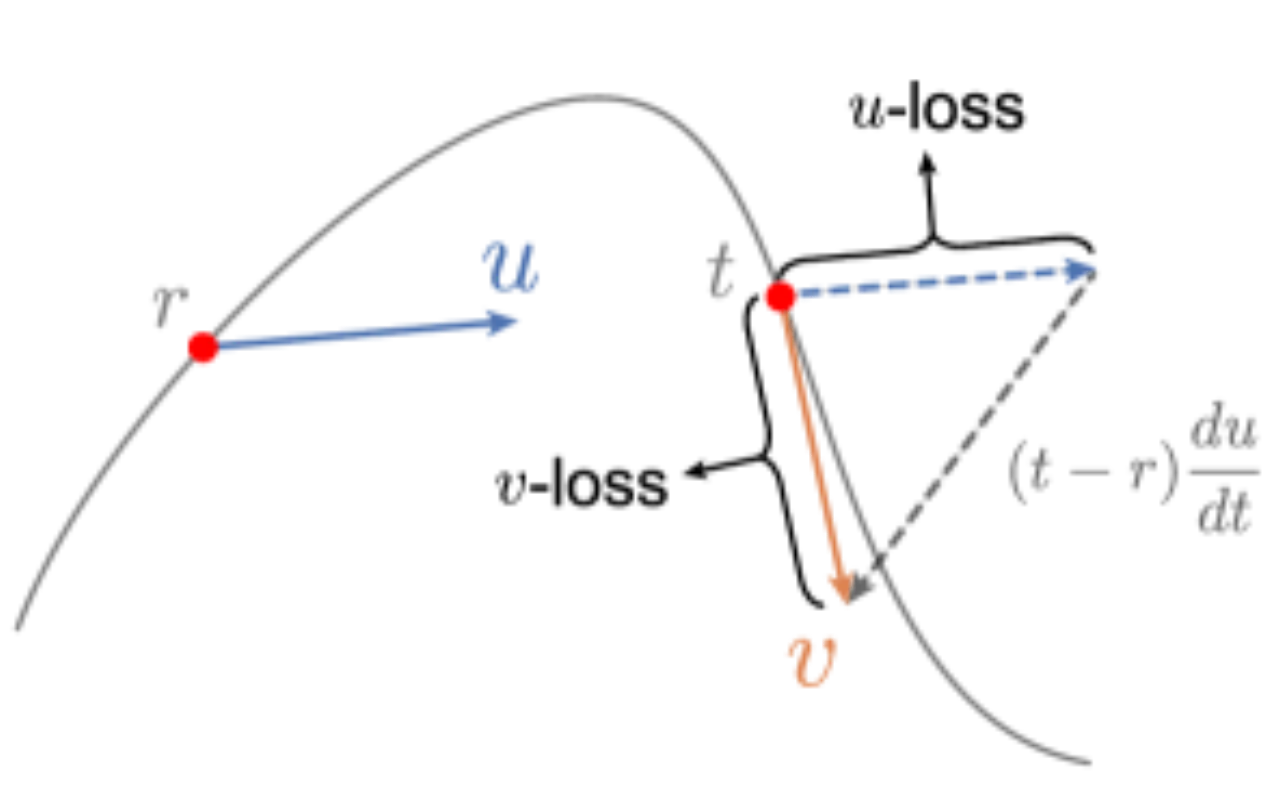
图 2: MeanFlow 可以被重构为以平均速度预测为参数化形式的速度损失(v-loss),推导基于 MeanFlow 恒等式关系。这一重构赋予了训练目标与网络无关的合法回归性质。
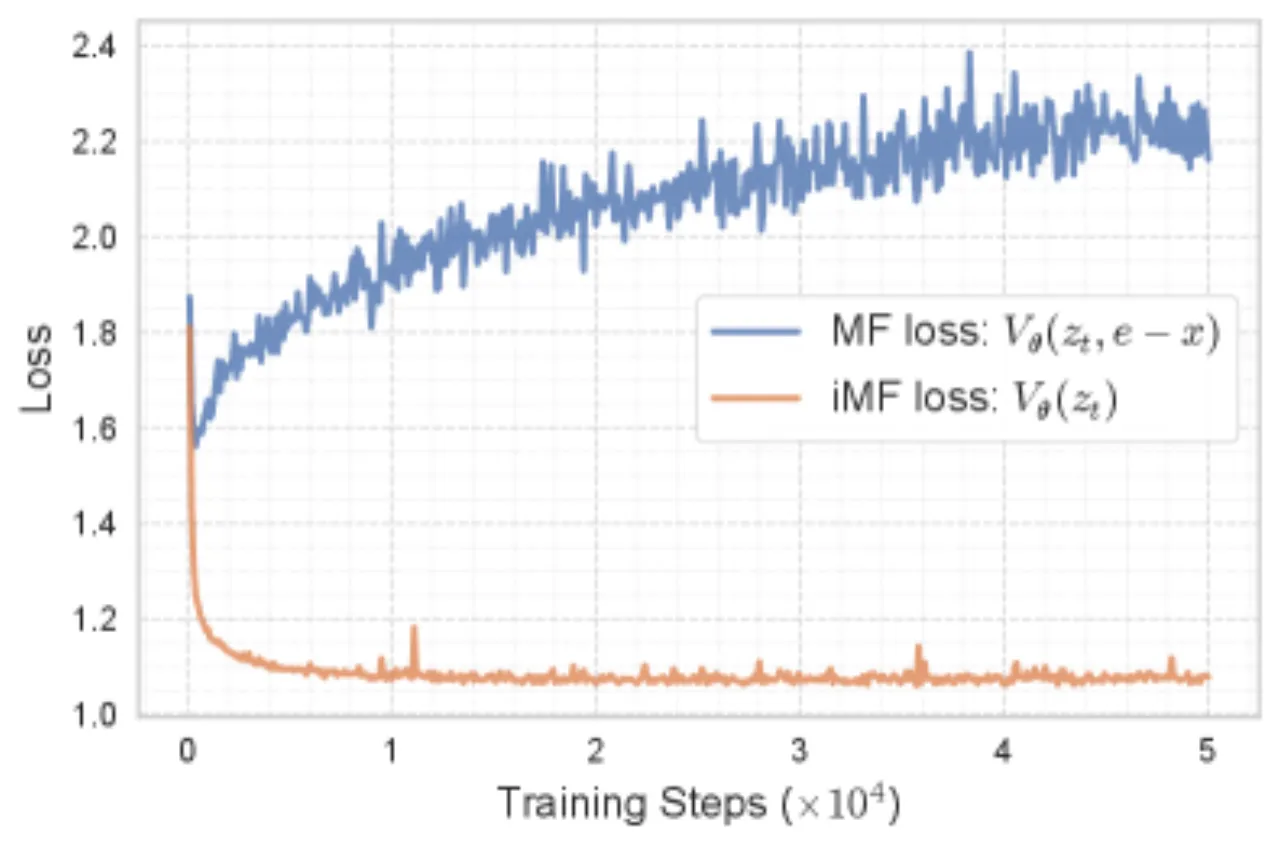
图 3: 训练损失曲线对比。原始 MF 表现出高方差和不下降的损失曲线(非标准回归的典型症状);而改进后的 iMF 收敛更加稳定平滑。
改进二:灵活的 Guidance 条件化(Flexible Guidance)
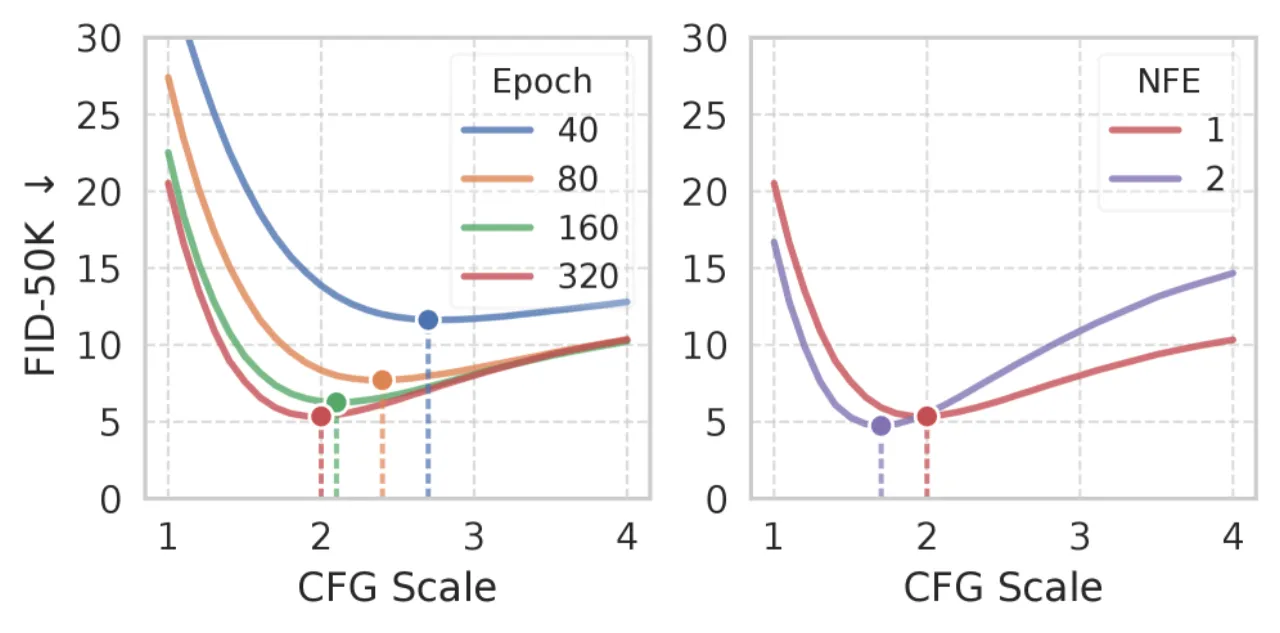
实验发现,最优 CFG 尺度随模型大小和训练轮次显著变化(图 4),固定 ω 使得原始 MF 在不同推理场景下性能受限。
解决方案:将 guidance 尺度 ω 作为显式条件变量 ,在训练时从分布中采样(偏向较小值以稳定训练),使单个模型在推理时支持任意 CFG 尺度。论文进一步扩展为 Ω = {ω, t_min, t_max},额外支持 CFG 的应用区间控制。
图 4: 不同训练 epoch 和推理步数下的最优 CFG 尺度(ω)差异显著。固定 ω 会导致在多数场景下使用次优的 guidance 强度,验证了灵活 guidance 设计的必要性。
改进三:In-context Conditioning(上下文条件化)
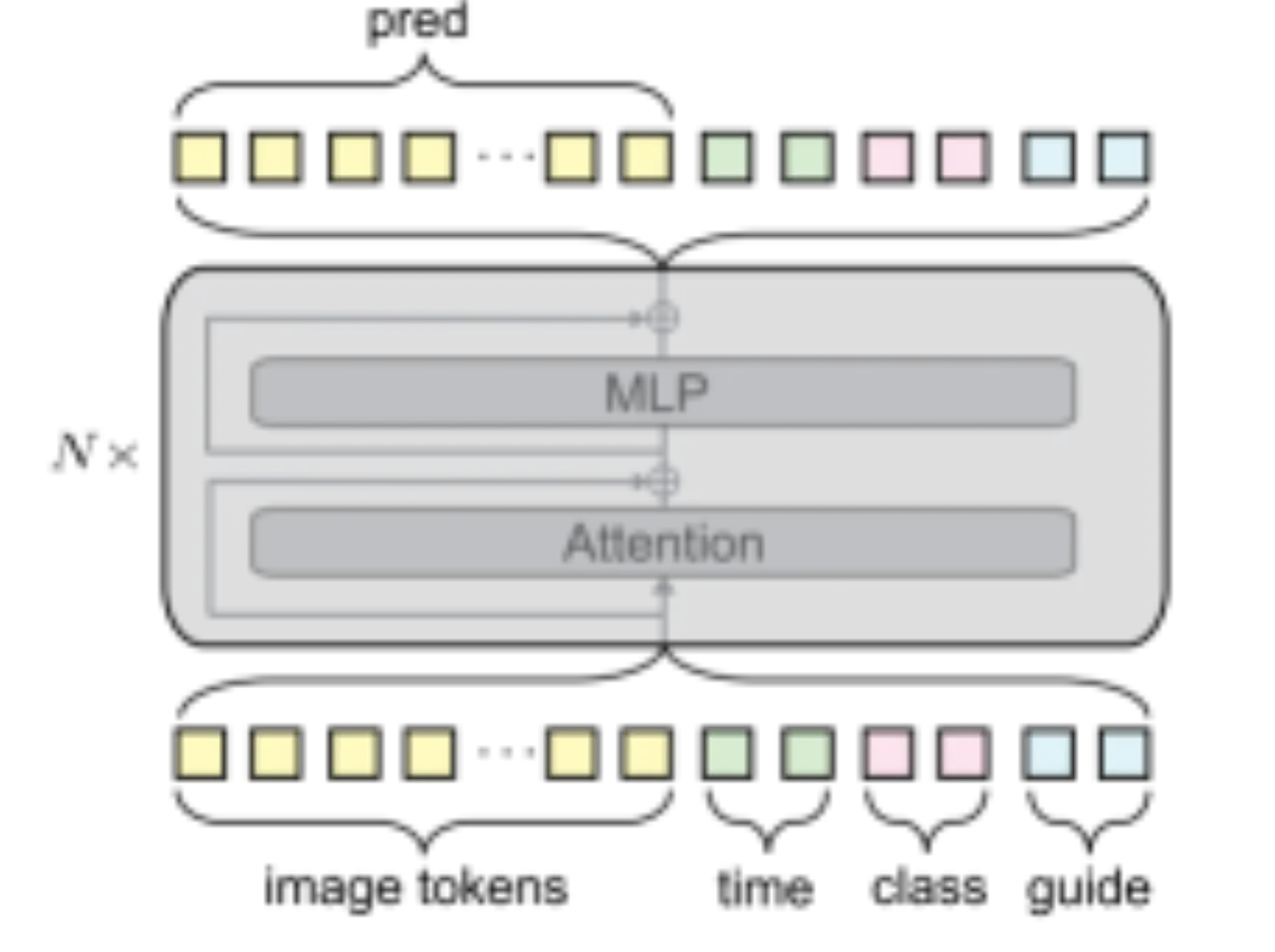
原始 DiT 使用参数密集的 adaLN-zero 来融合条件信息。iMF 改用多 token 的 in-context conditioning:每种条件(时间步 r, t;类别 c;guidance 因子 Ω)转化为若干可学习 token,与图像 token 拼接后统一送入 Transformer。
配置:类别条件用 8 个 token,其余条件各用 4 个 token。这一设计在 Base 规模上将参数量从 133M 减至 89M(减少 33% ),同时 FID 进一步提升。
图 5(对应原文图 6): 改进的 in-context conditioning 架构。将每种条件类型(时间步、类别、guidance 因子)编码为多个 token 并拼接至图像 token 序列,取代了原来参数量较大的自适应层归一化(adaLN-zero),在减少参数的同时提升了性能。