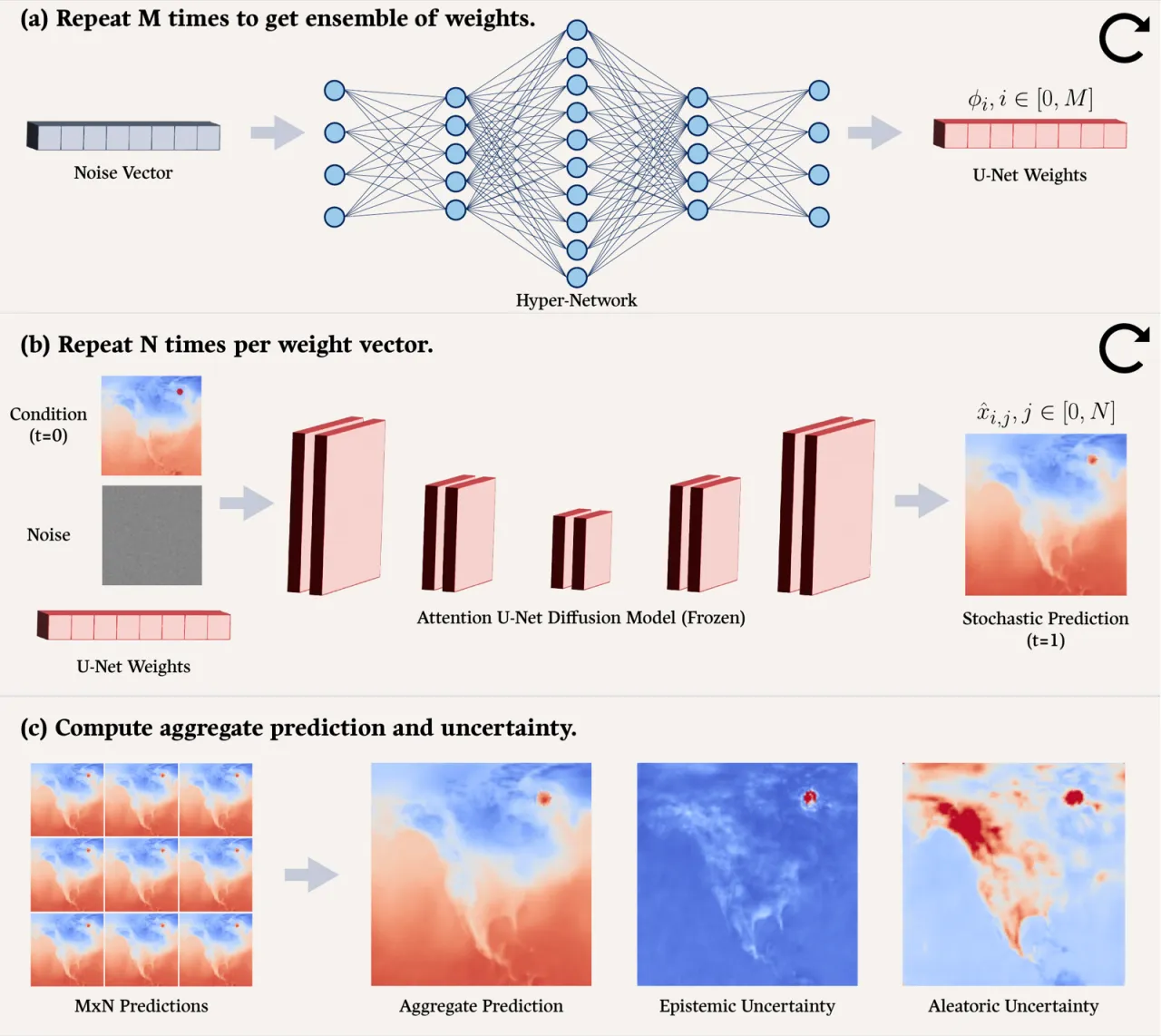
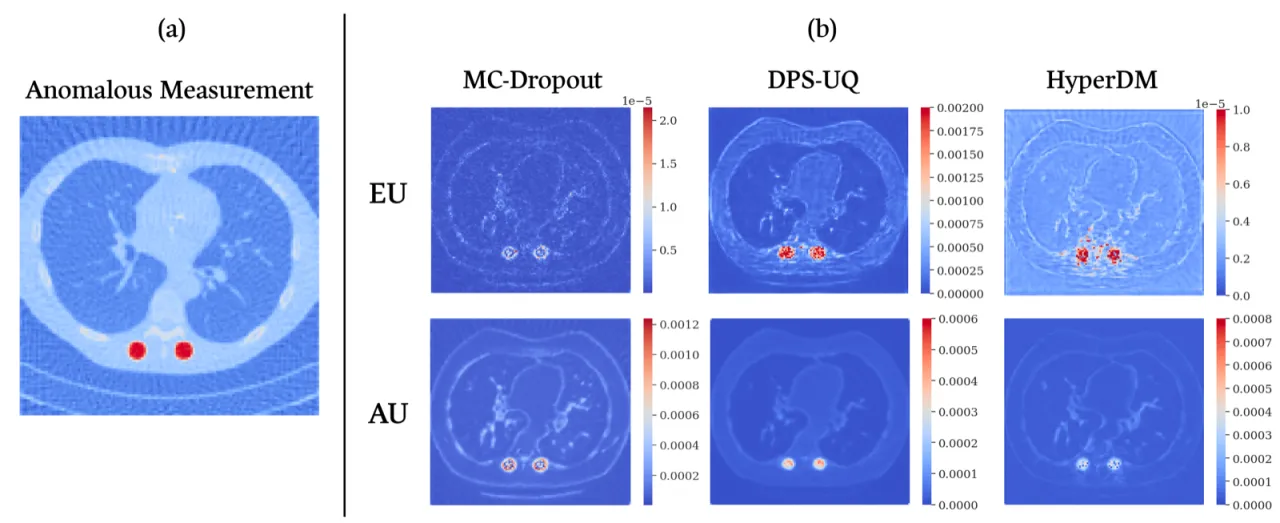
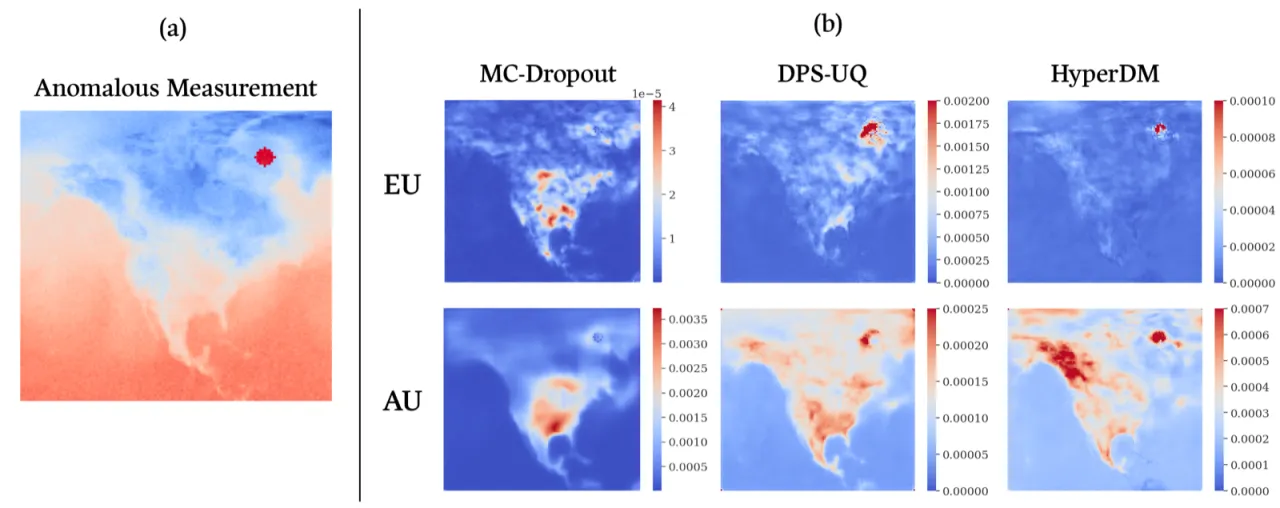
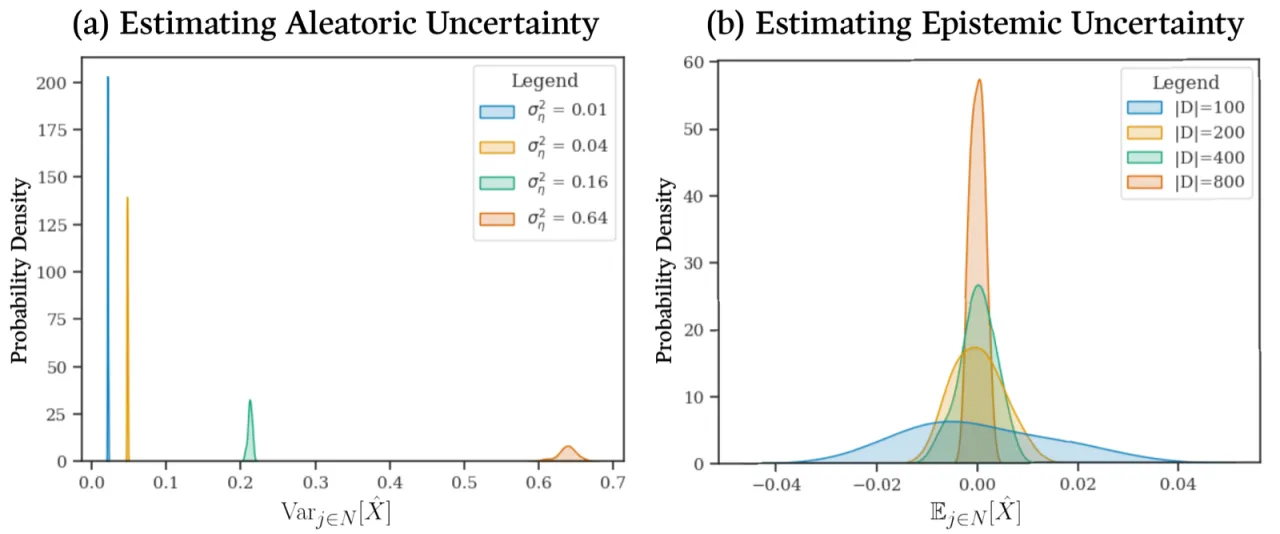
01 动机
Conditional diffusion model 已能高效地从数据后验分布中采样,这在理论上使不确定性估计变得简单:训练并采样一个大型 diffusion model 集成即可。 然而,随着模型架构复杂度增长,训练这样一个集成在计算上变得"intractable"(难以承受)。 现有单模型方案——如 Monte-Carlo dropout 和 Bayesian neural network(BNN)——要么损害预测精度,要么推理代价过高,且通常无法同时精确估计两类不确定性。
"Estimating and disentangling epistemic uncertainty, uncertainty that is reducible with more training data, and aleatoric uncertainty, uncertainty that is inherent to the task at hand, is critically important when applying machine learning to high-stakes applications such as medical imaging and weather forecasting."
1×训练开销(vs. M×倍 deep ensemble)
~3%额外训练时间(vs. MC-Dropout baseline)
8×DPS-UQ 训练开销倍数(vs. HyperDM)
M×N总预测样本数(M 组权重,每组 N 次采样)