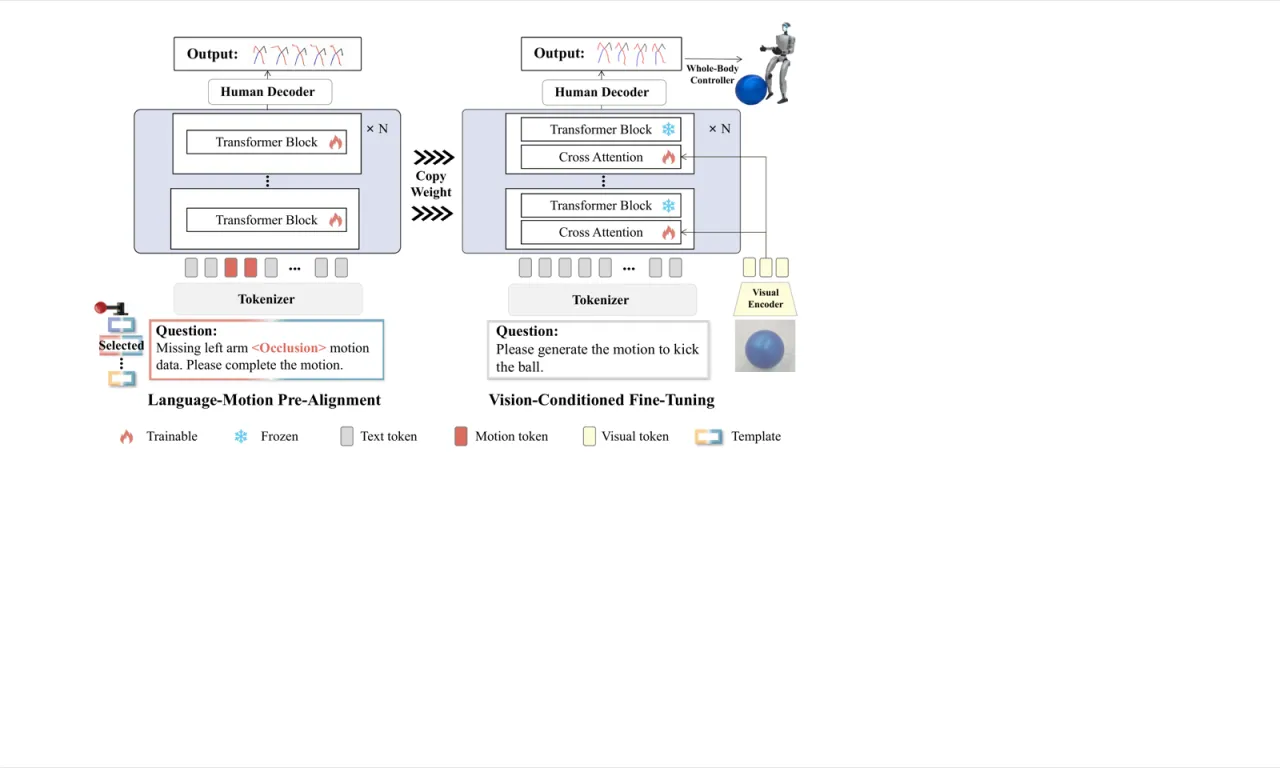
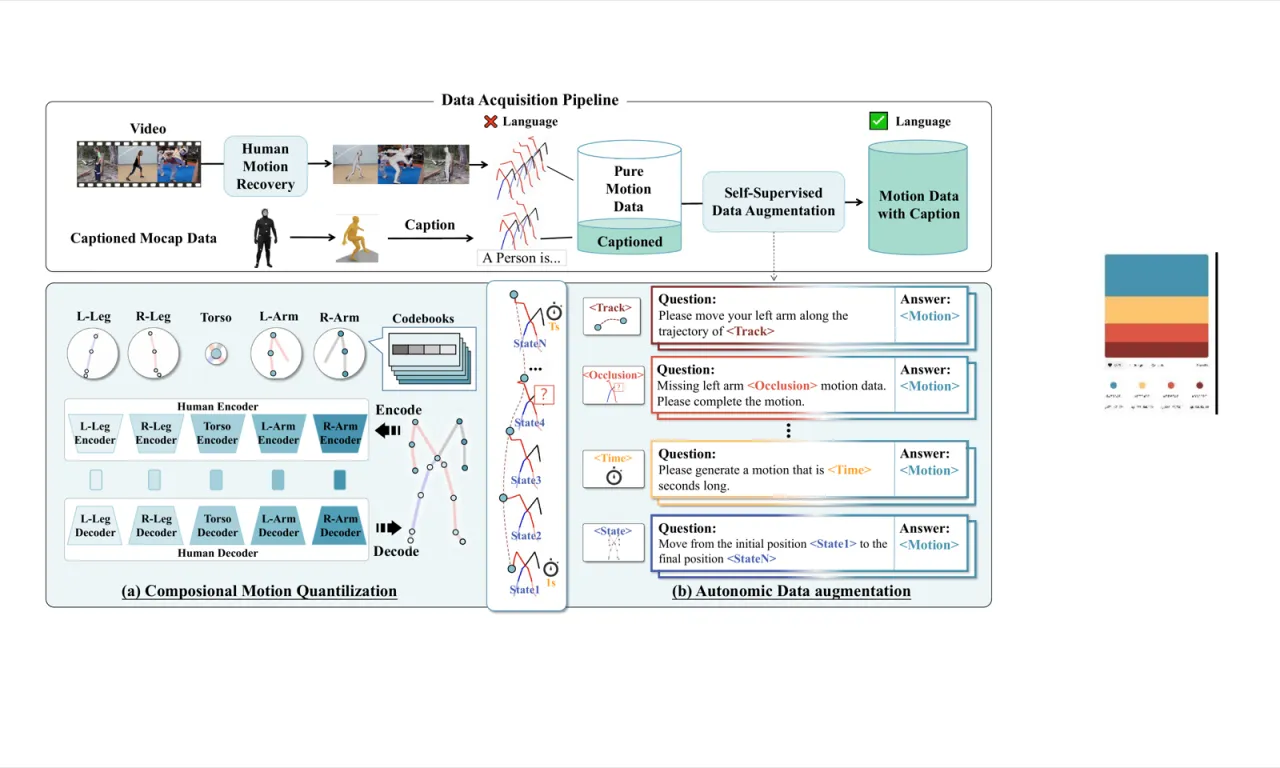
"Current data acquisition methods, focusing mainly on human joint poses, lack integration with egocentric vision. Thus, they can only teach robots what actions are performed, not the underlying intent or context."
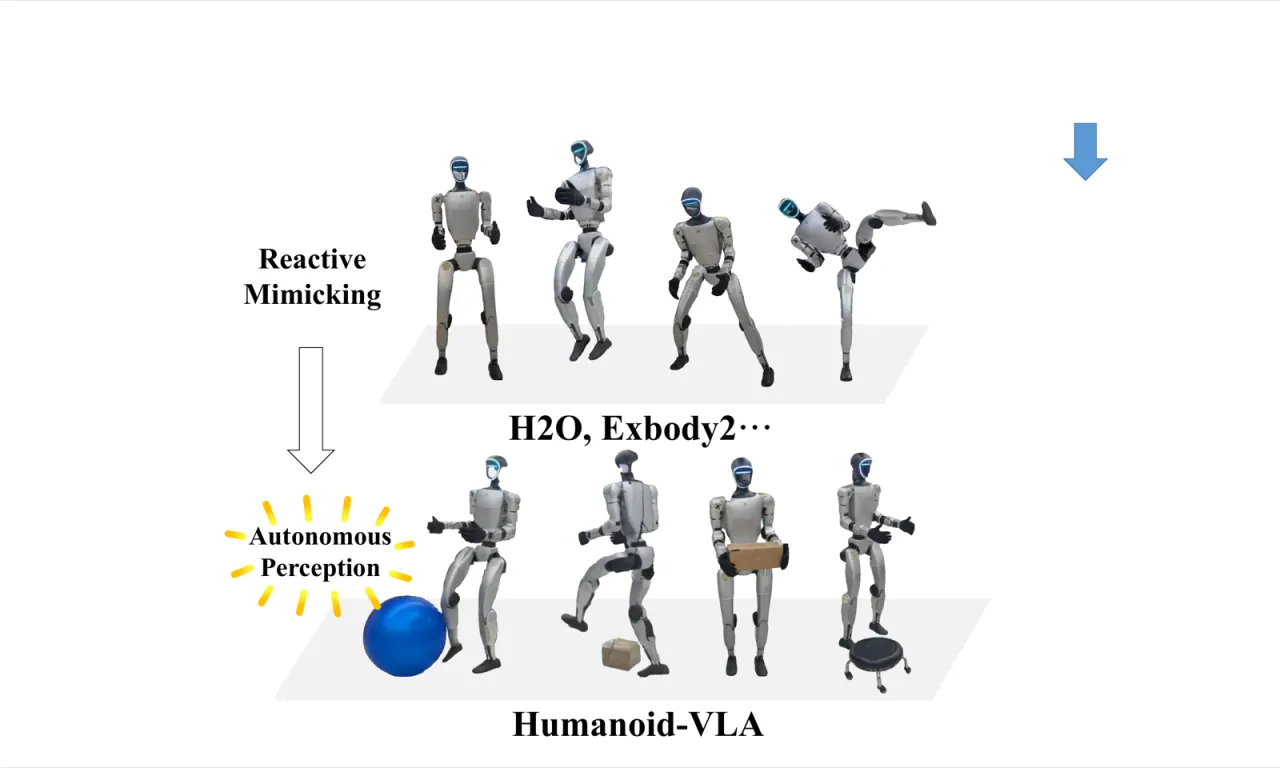
图1:先前方法 vs. Humanoid-VLA。
先前方法通过模仿人体演示执行运动,依赖反应式机制。Humanoid-VLA 具备自主感知能力,可主动识别交互目标并执行物体交互任务,显著超越了基于演示模仿的方法。
论文结论明确指出:"In the future, we aim to enhance the success rate of humanoid robots in performing more complex loco-manipulation tasks."——说明当前框架在精细运动操作(loco-manipulation)任务上仍存在不足,尤其在涉及手部精细控制的场景中。