01 动机
通用人形机器人的进步依赖于大规模、多样化的数据,而现有数据集存在明显短板:任务种类少、传感器模态单一、缺乏标准化评测手段。Humanoid Everyday 旨在从根本上弥补这些缺口。
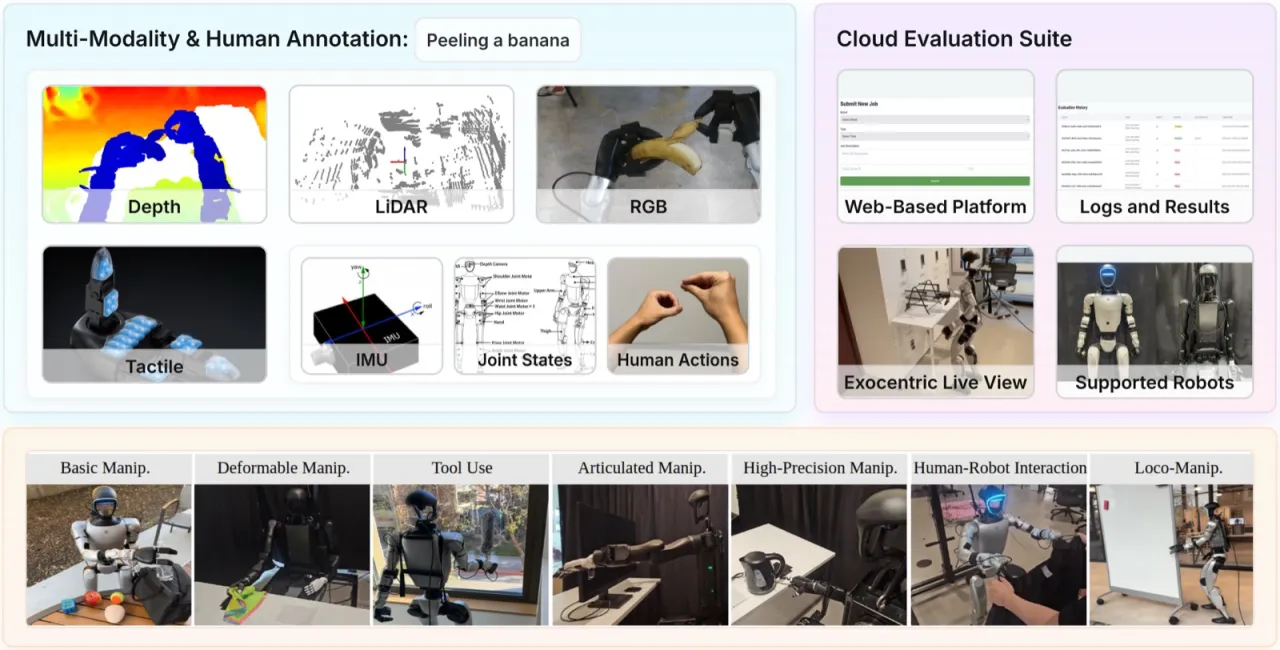
"现有机器人操作数据集往往局限于桌面操作场景,且大多基于非人形平台,难以捕捉类人机器人在真实世界中面临的高自由度、多任务挑战……我们提出 Humanoid Everyday——一个大规模、多模态的人形机器人操作数据集,覆盖 dextrous object manipulation、human-humanoid interaction 与 locomotion-integrated actions。"
10.3k条轨迹(trajectories)
3M+帧数据(frames)
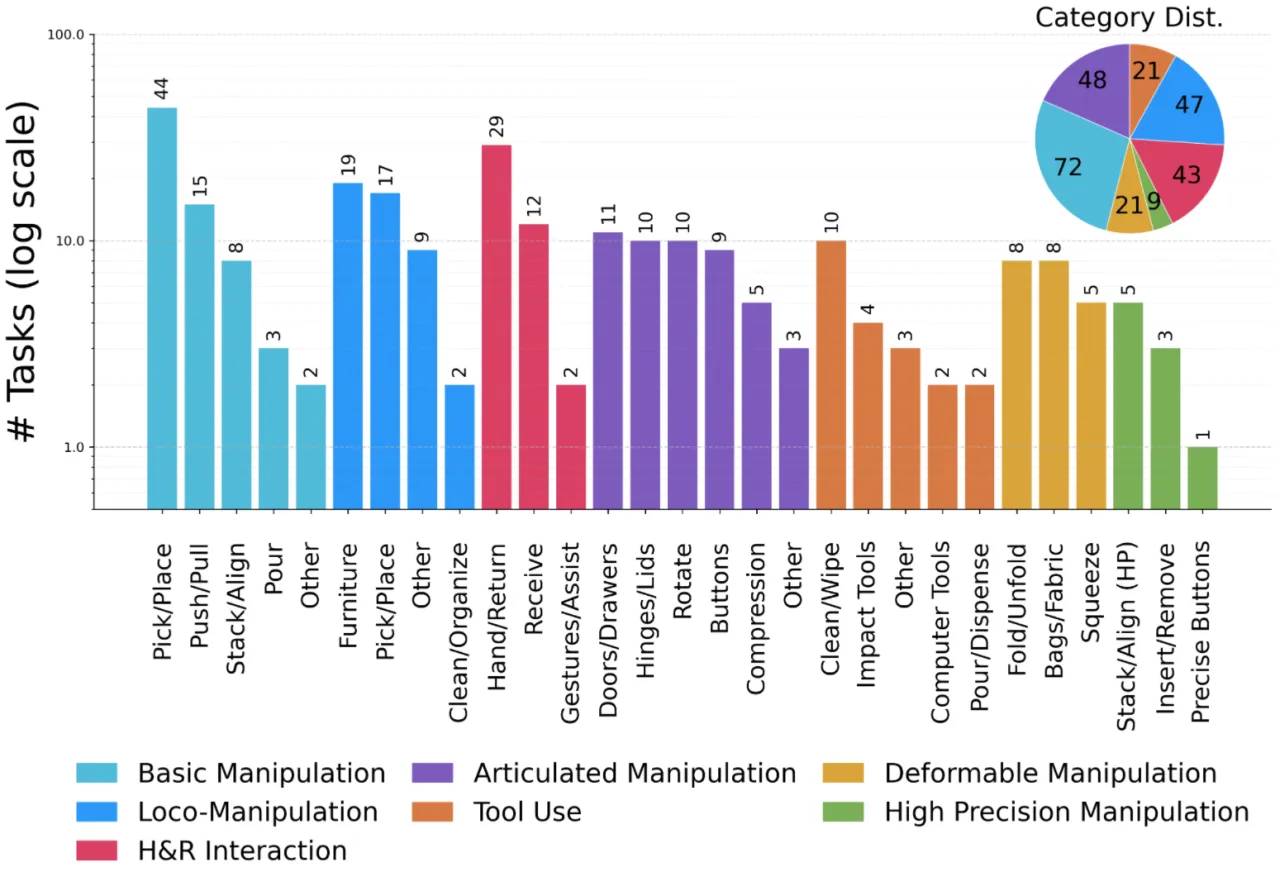
260个独特任务(unique tasks)
7大任务类别
三大核心贡献
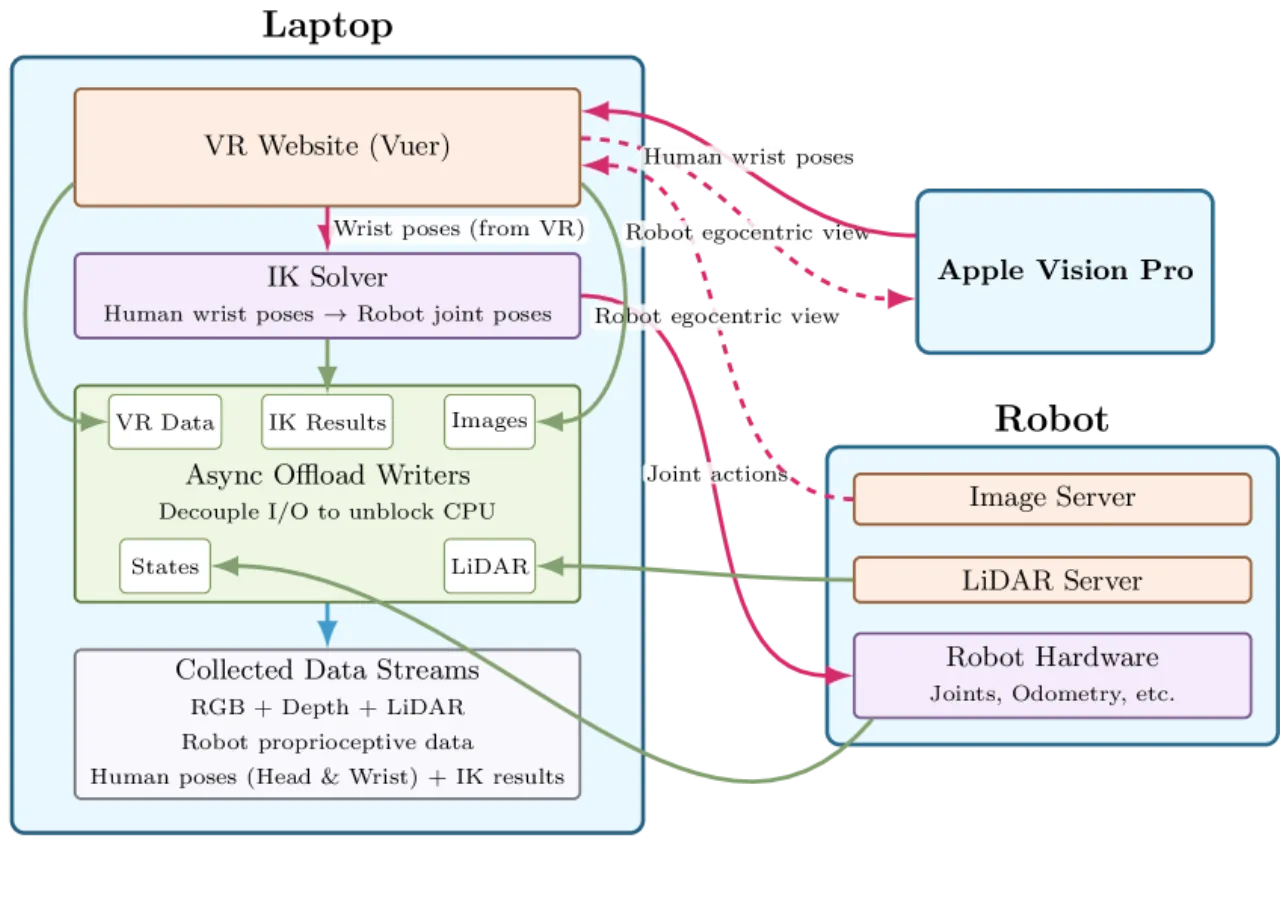
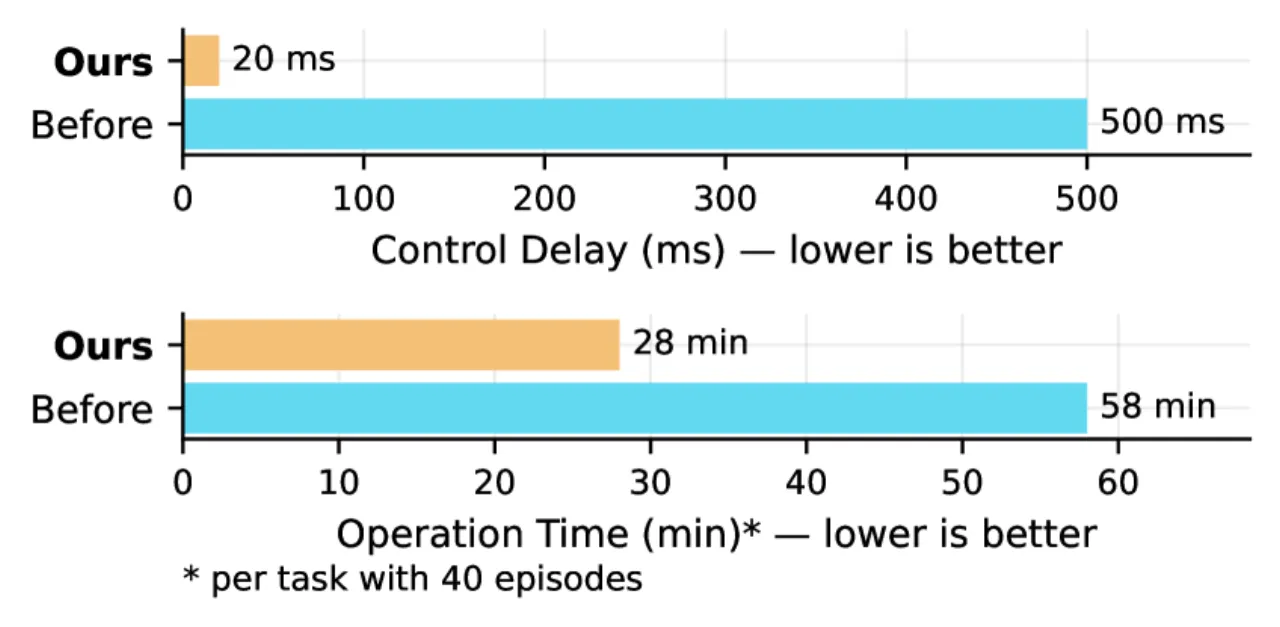
- 大规模多模态数据集:真实世界采集,含 RGB、深度图、LiDAR、触觉及自然语言标注,优化后的遥控采集流水线将采集时间减半。
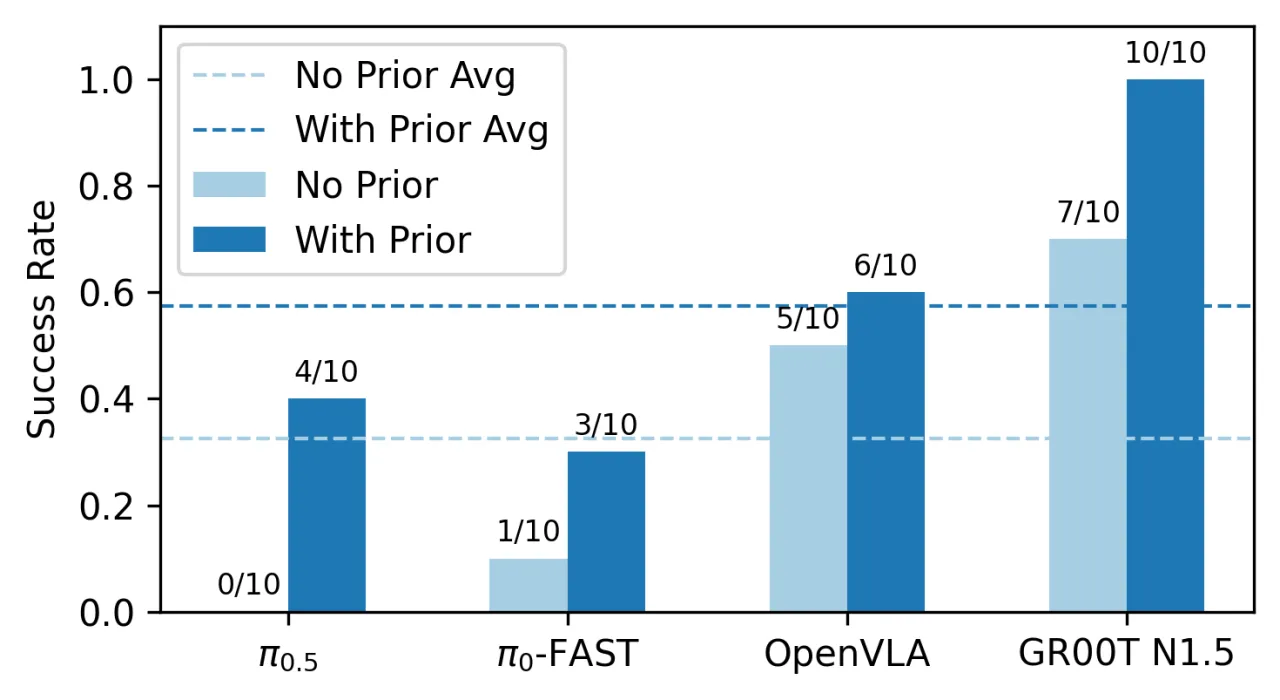
- 代表性策略评测分析:对主流 imitation learning 方法(Diffusion Policy、ACT、OpenVLA、π₀ 等)进行系统评测,揭示其优劣势。
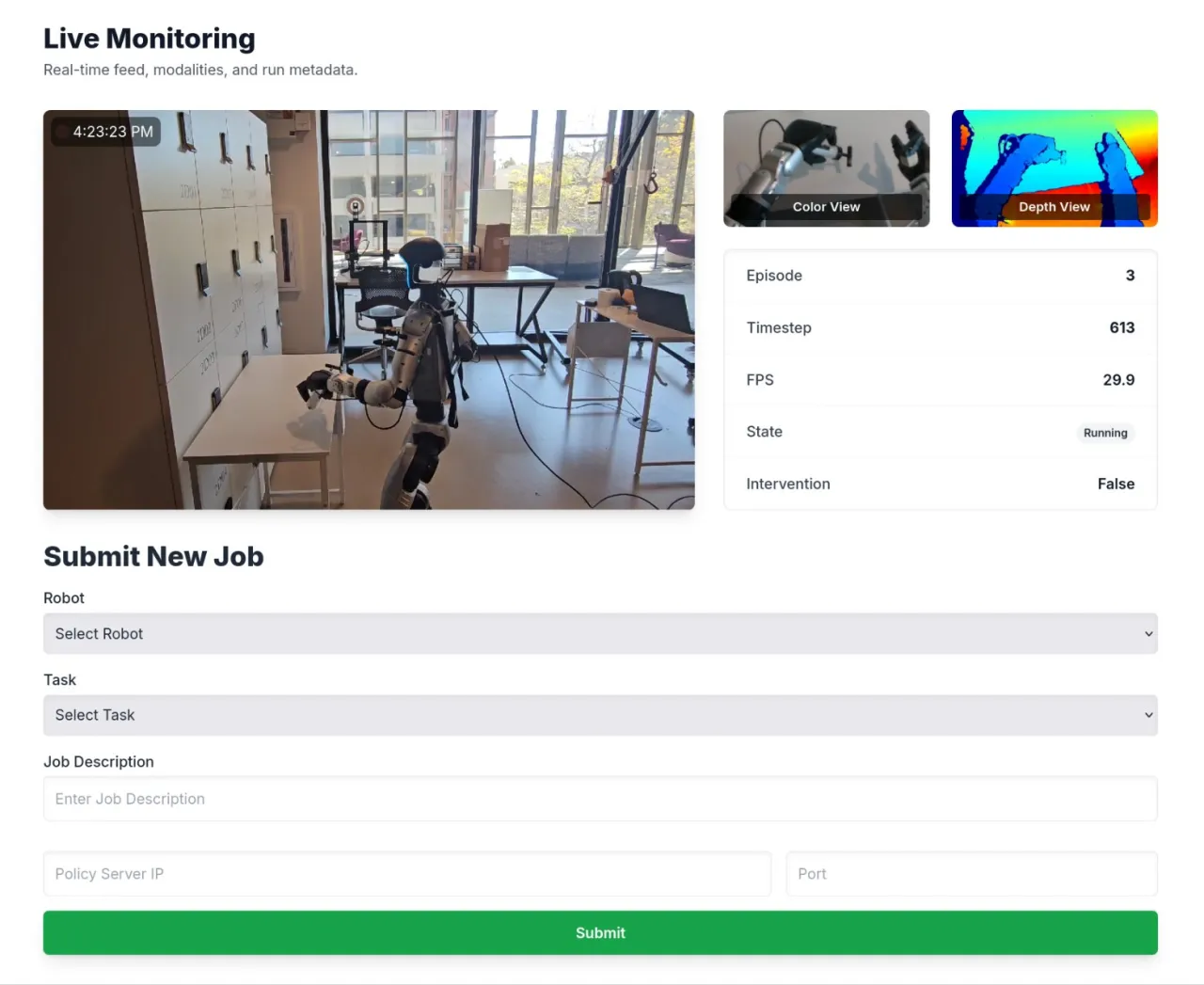
- 云端评测平台:支持标准化、可复现、协作式的策略部署与测试,无需研究者自备硬件。