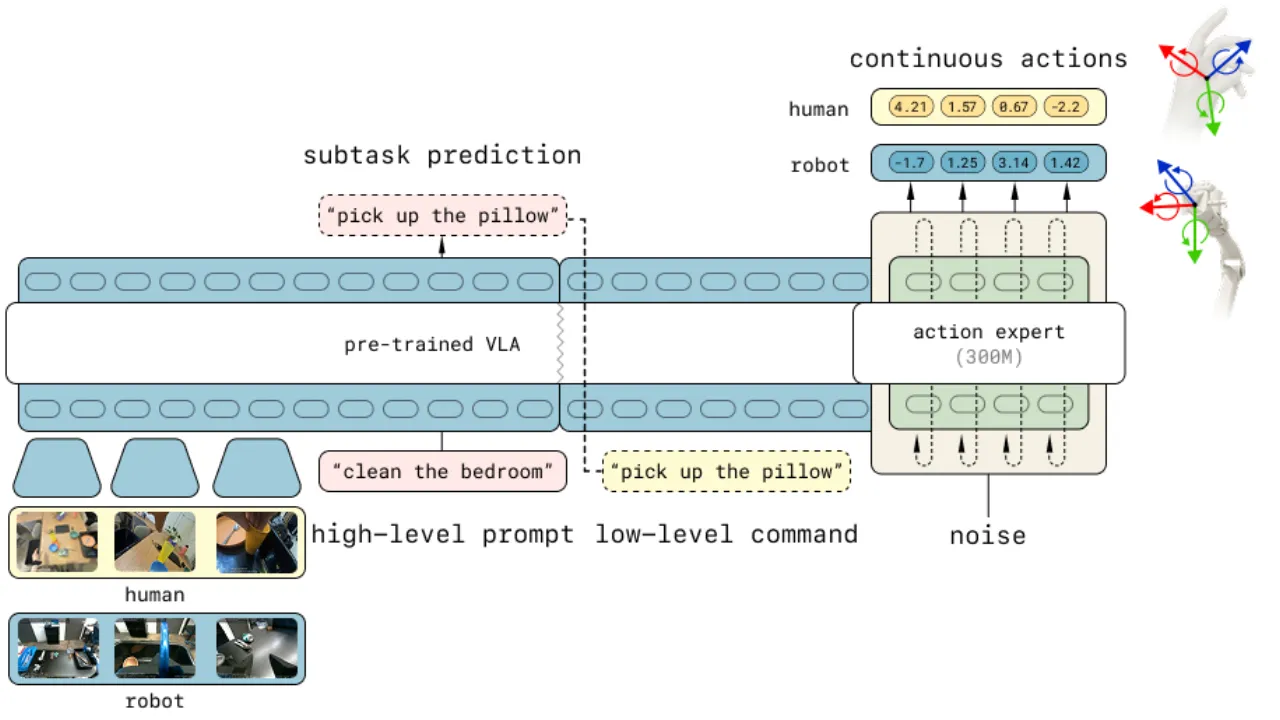
01 动机
训练机器人需要大量专门的遥操作数据,成本高且难以规模化。互联网上拥有海量人类操作视频,理论上可以极大丰富训练数据多样性——但人与机器人在形态、视角、运动方式上存在巨大差异,直接利用并非易事。
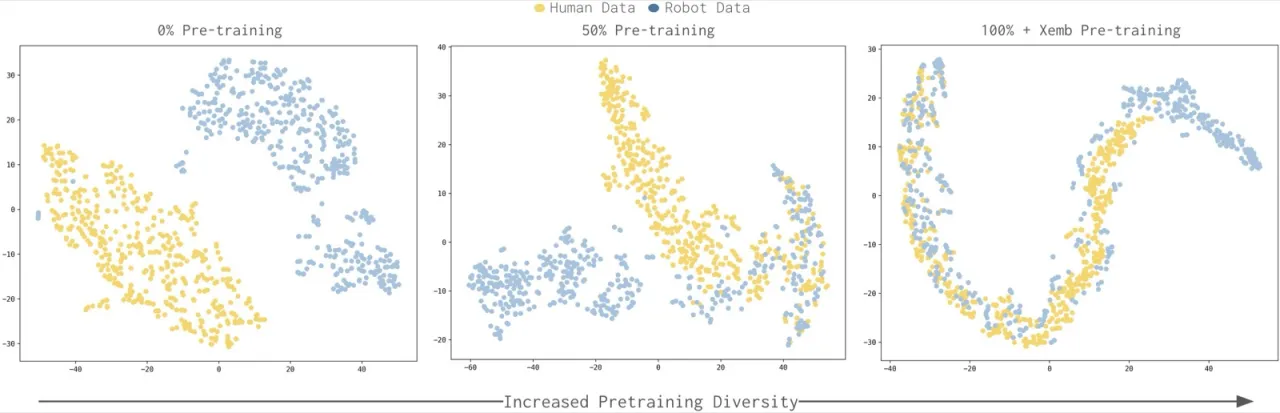
过去的研究尝试用显式的跨形态对齐(如视频预测、形态嵌入对齐)来桥接这一鸿沟,但效果不稳定。本文提出一个不同视角:这种迁移能力是否是大规模 VLA 预训练多样性带来的涌现属性,而非需要专门设计的桥接机制?
"Human-to-robot transfer is an emergent property of diverse VLA pretraining."
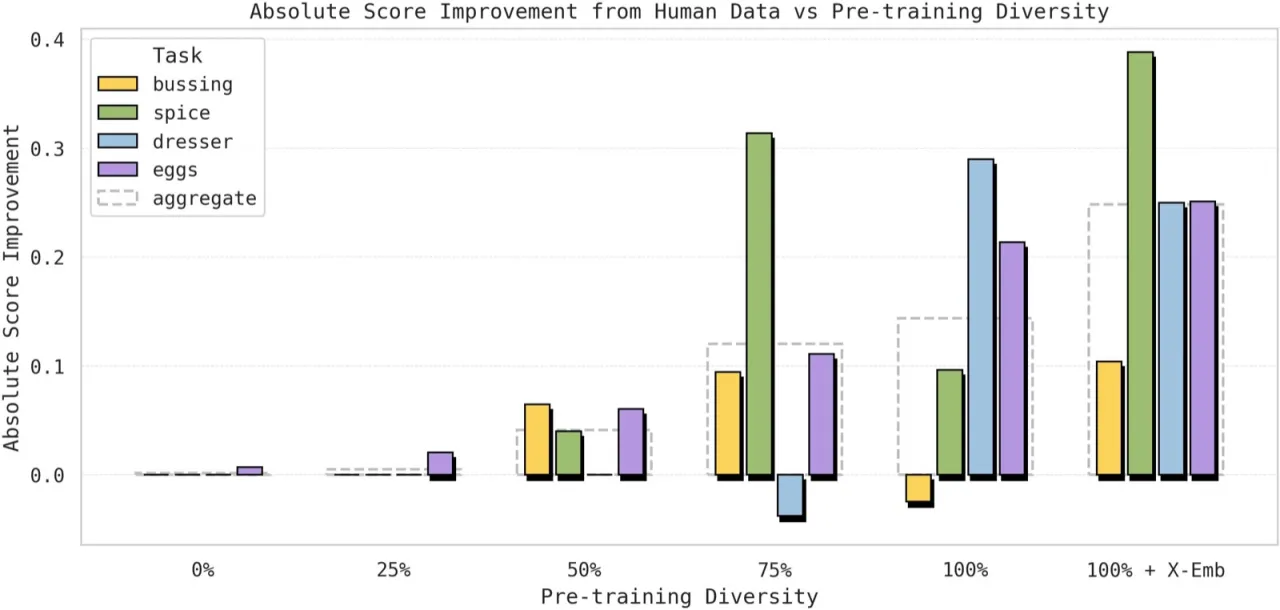
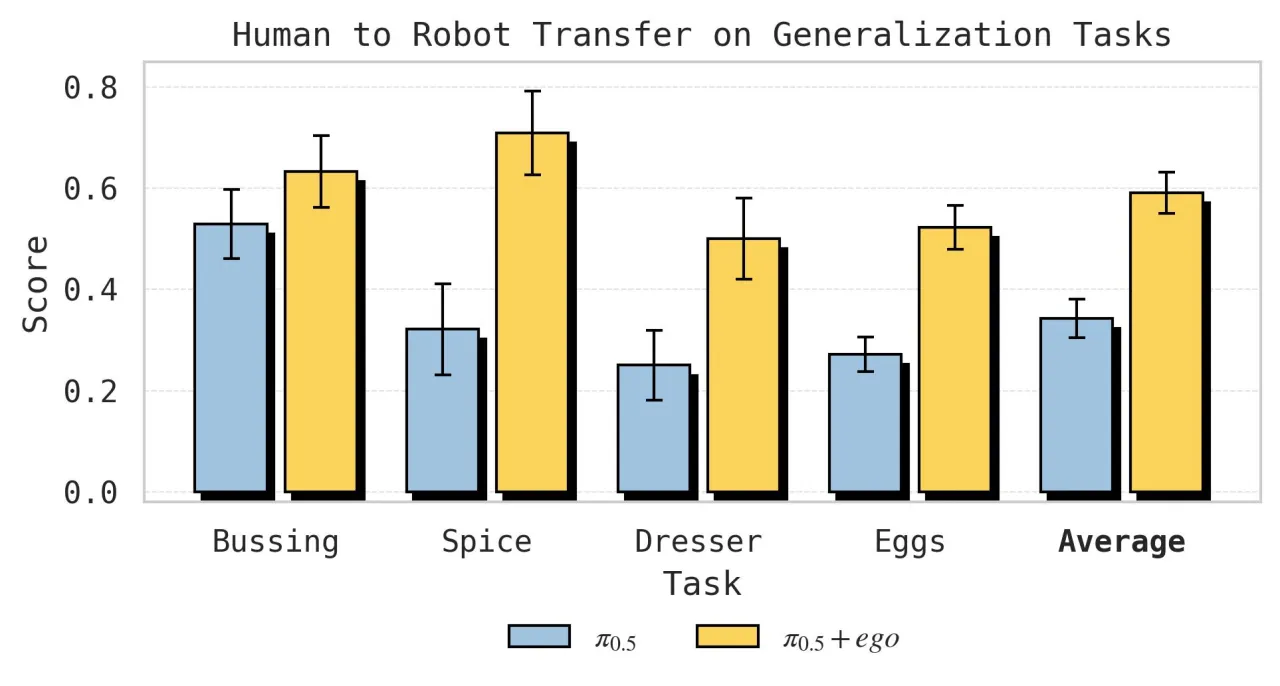
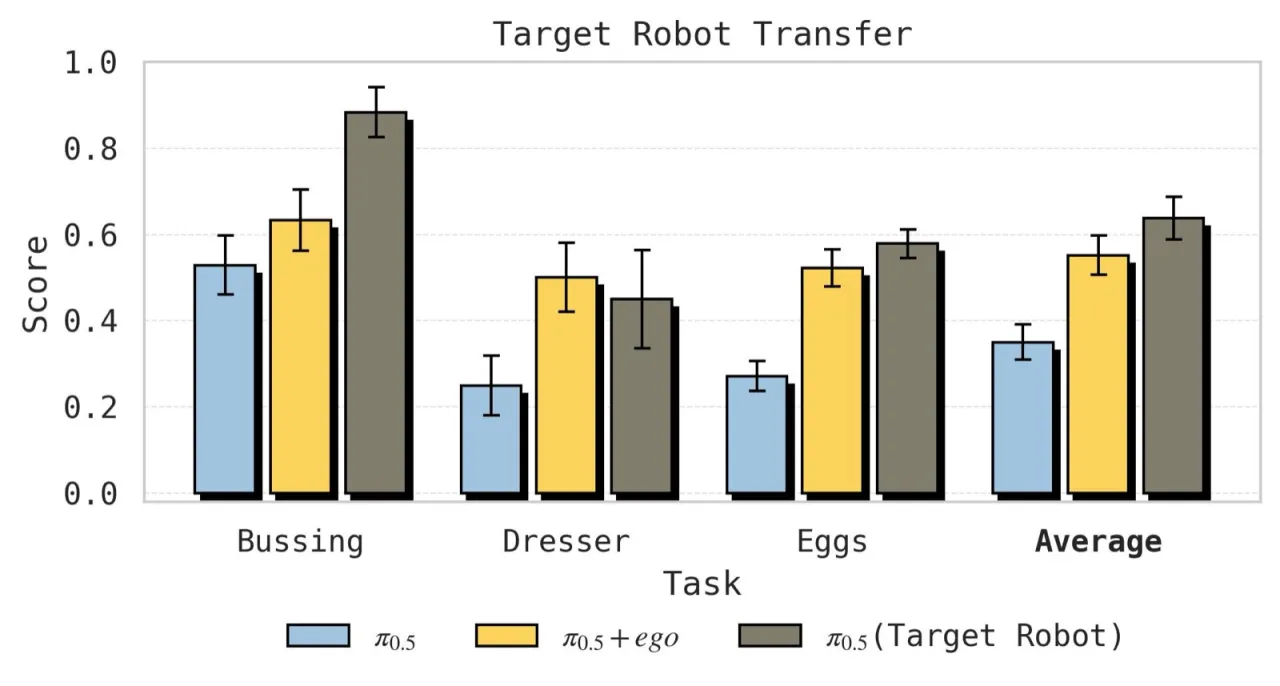
+39%Spice 任务成功率提升(32%→71%)
+25%Dresser 任务成功率提升(25%→50%)
+21%Sort Eggs 准确率提升(57%→78%)
14h人类示范视频总时长(4 个任务)