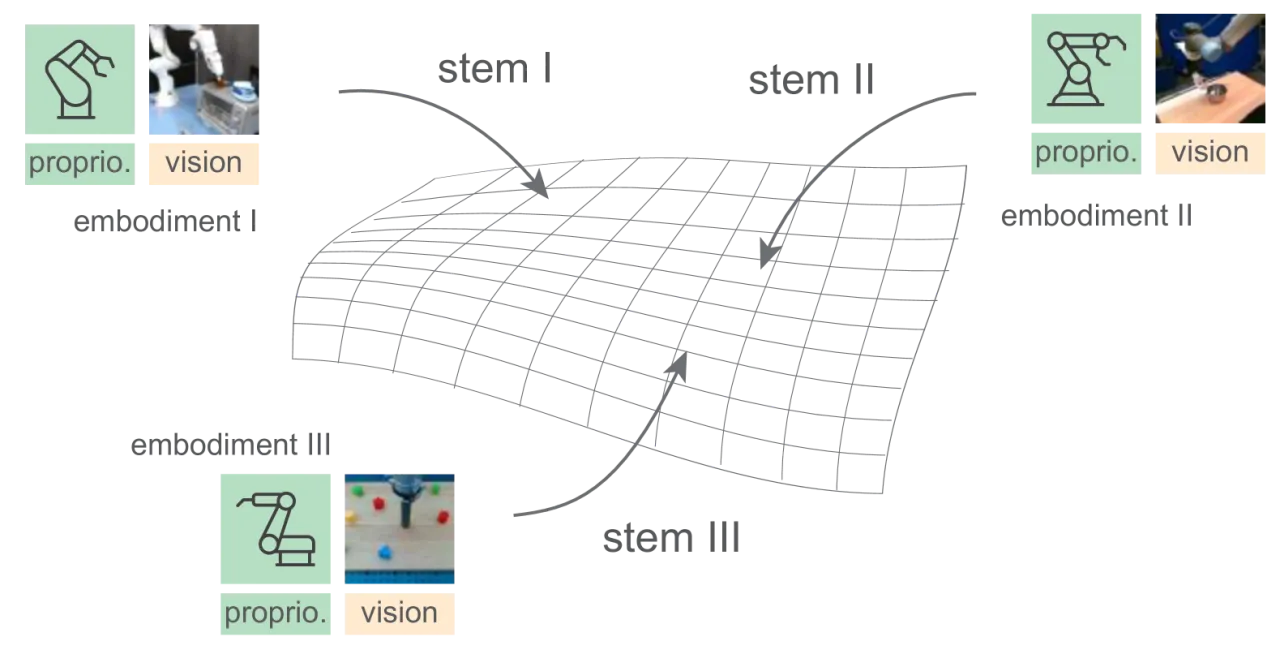
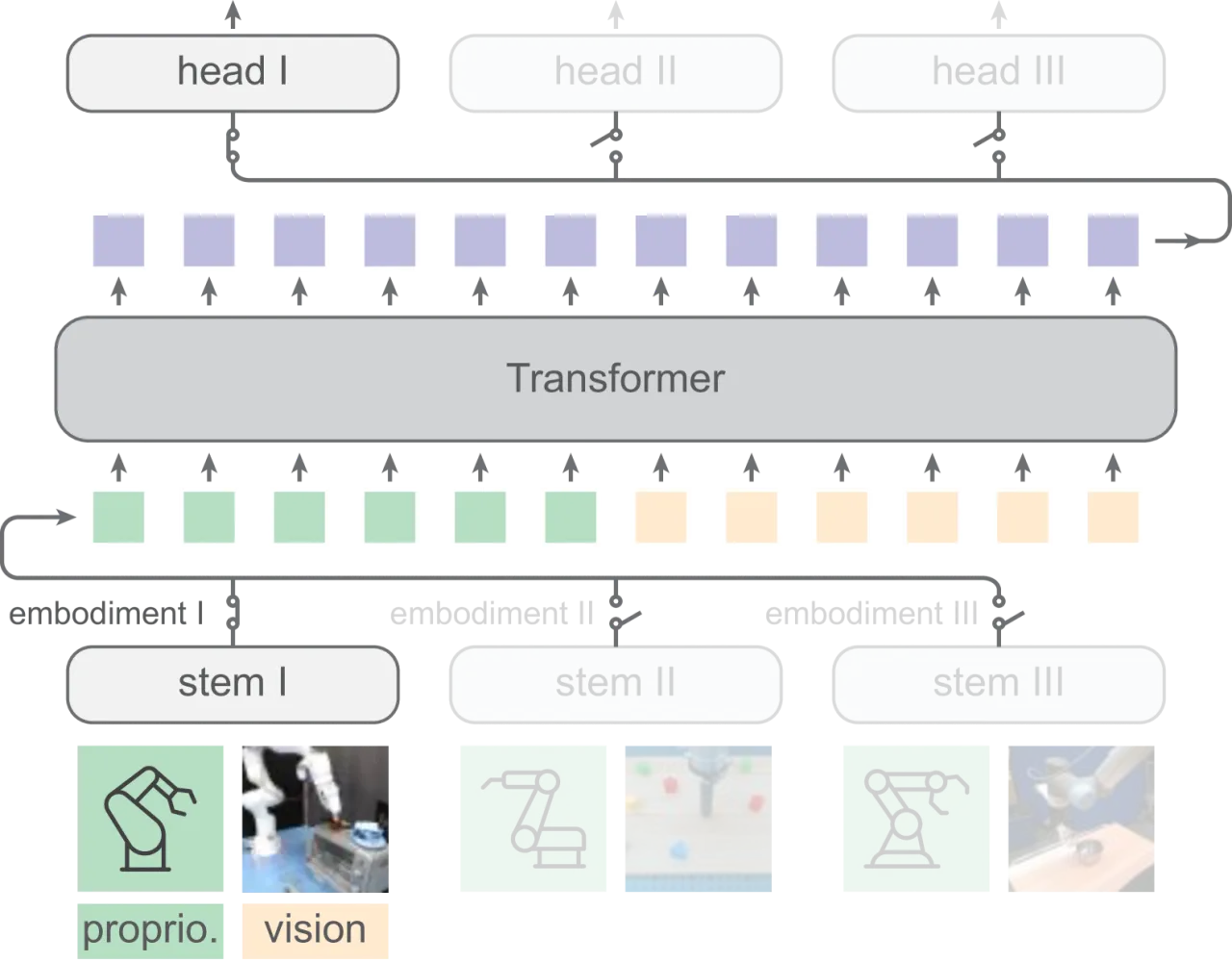
02 方法HPT 将策略神经网络拆分为三个模块:形态专属的 stem (输入对齐层)、可共享的大型 trunk (Transformer 主干)、以及任务专属的 head (动作输出层)。预训练阶段共享 trunk,迁移时仅微调 head 或全部参数。
Figure 2:HPT 整体架构。 每种机器人形态配有独立的 stem 和 head(switch 机制按当前数据集激活对应的 stem/head),所有形态共享同一个 trunk。stem 将视觉和本体感知观测分别映射为各 16 个 token,拼接后输入 trunk;trunk 输出经池化后由 head 解码为动作序列。这一设计使得 trunk 能够在异构数据上协同学习,而不同形态的 IO 差异由 stem/head 吸收。
Stem:本体感知与视觉 Token 化
对于形态 k,proprioceptive tokenizer 将任意维度的本体感知序列(关节角度、末端位姿等)映射为 Np =16 个固定维度 token:先用 MLP 映射到特征空间,再施加 sinusoidal 位置编码,通过 cross-attention 将特征压缩到 16 个可学习 query token 上。Vision tokenizer 则先用冻结的 ResNet-18 提取图像特征,再同样通过 attention 映射到 16 个 token。两组 token 拼接后形成 32 个输入 token 送入 trunk。
Figure 3:Stem 架构细节。 左侧为本体感知 tokenizer(MLP + sinusoidal PE + cross-attention → 16 tokens),右侧为视觉 tokenizer(冻结 ResNet-18 特征 + cross-attention → 16 tokens)。两者输出拼接后送入 trunk。每种形态的 stem 参数独立,但结构相同。
Trunk:共享 Transformer 主干
Trunk 是标准的 Transformer encoder,提供五种规格的参数量:
规格 参数量 深度 宽度 HPT-Small 3.1M — — HPT-Base 12.6M — — HPT-Large 50.5M — — HPT-XL 226.8M — — HPT-Huge 1.1B — —
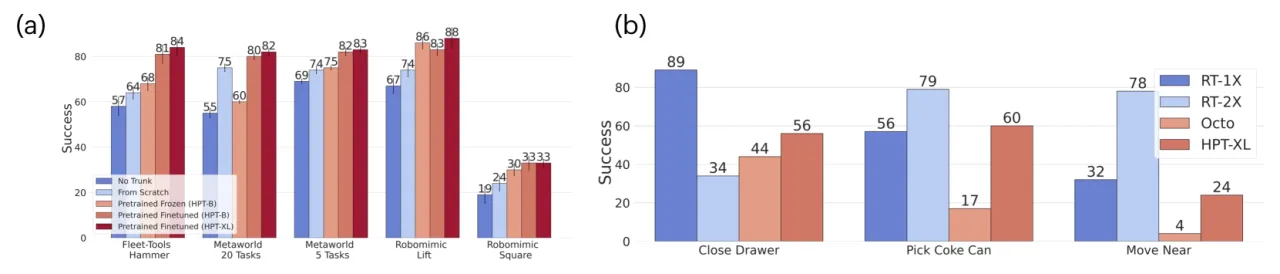
预训练阶段,trunk 对所有数据集共享权重,通过 switch 机制在同一个 batch 中激活不同形态的 stem/head 对,实现真正的异构联合训练。迁移时,trunk 初始化来自预训练权重,head 重新初始化后再端到端微调。
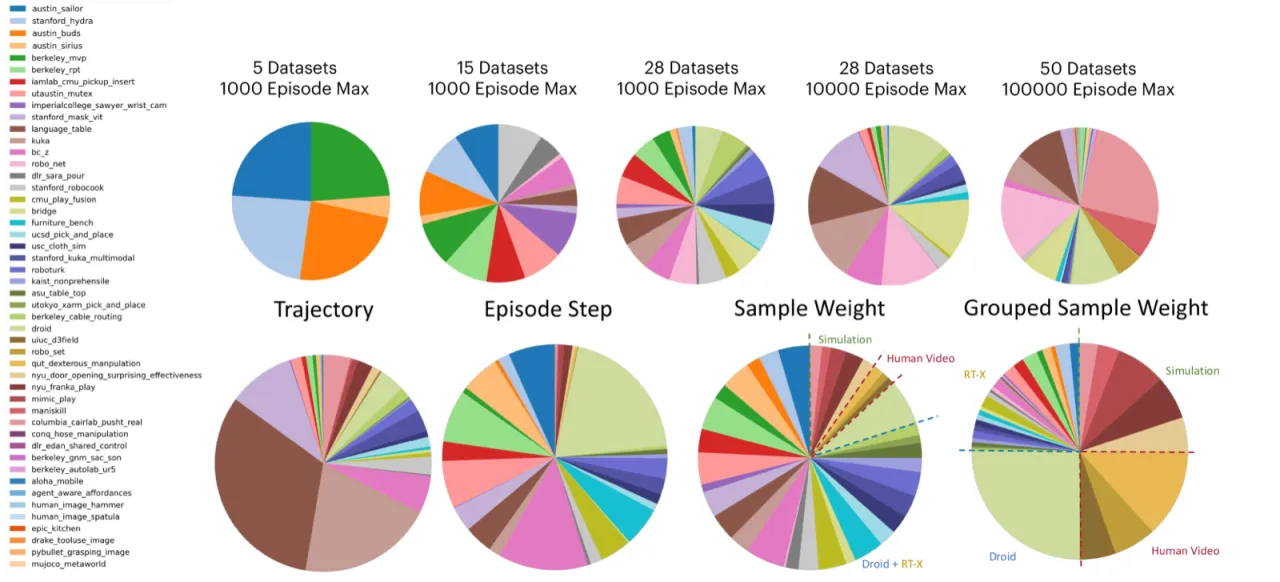
预训练数据规模
默认设置使用 27 个 RT-X 数据集(16k 轨迹,5M 样本,batch size 256)。大规模设置扩展到 52 个数据集(270k 轨迹,155M 样本,batch size 2048),涵盖 42 个真实机器人数据集、7 个仿真数据集、3 个人类视频数据集和 1 个已部署机器人数据集。