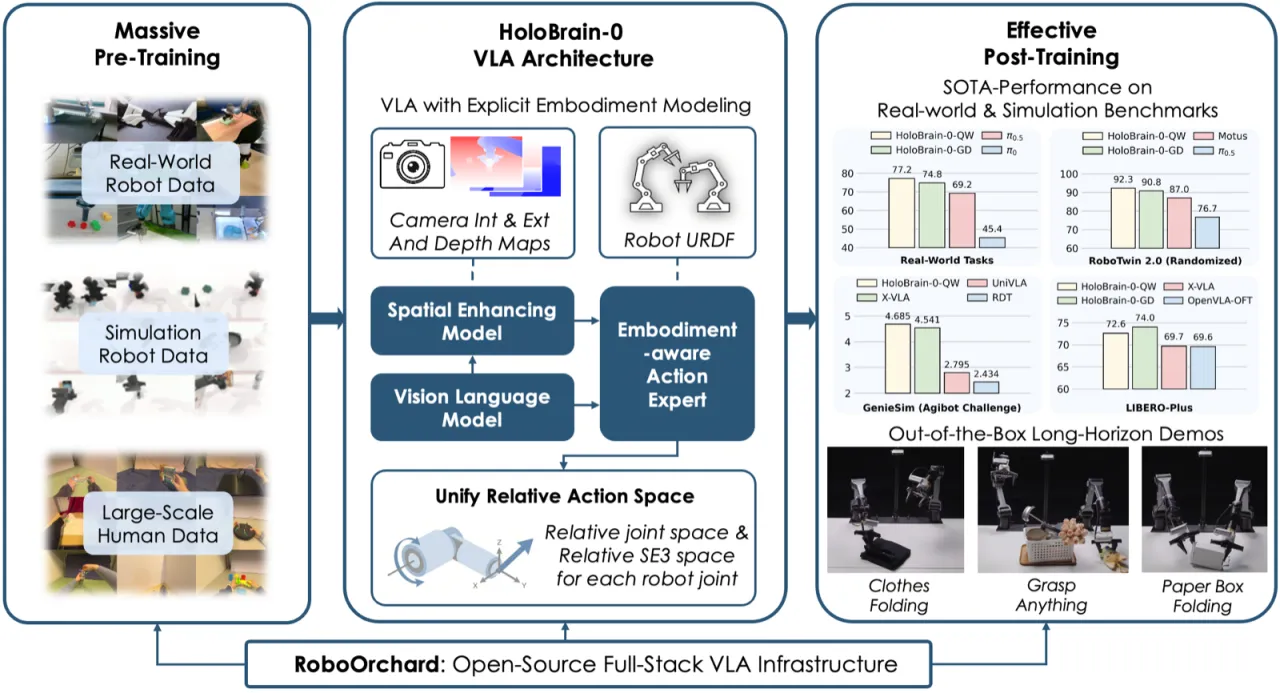
PSE 利用相机内外参与深度图,将多视角 2D 图像特征投影到统一的 3D 坐标系。关键设计是将 3D 投影坐标系从机器人本体基座坐标系切换至固定中心相机坐标系,从而支持跨具身(cross-embodiment)训练——不同机器人的传感器布局不同,但统一到相机帧后可共享特征空间。
Embodiment-Aware Action Expert
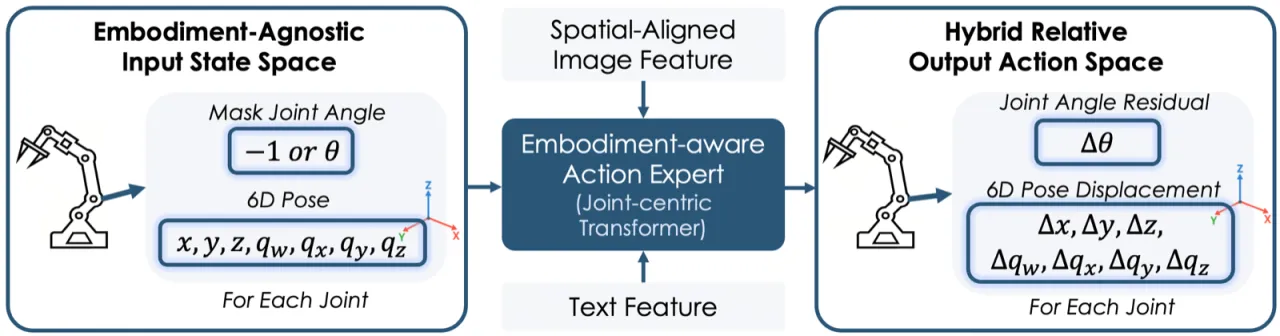
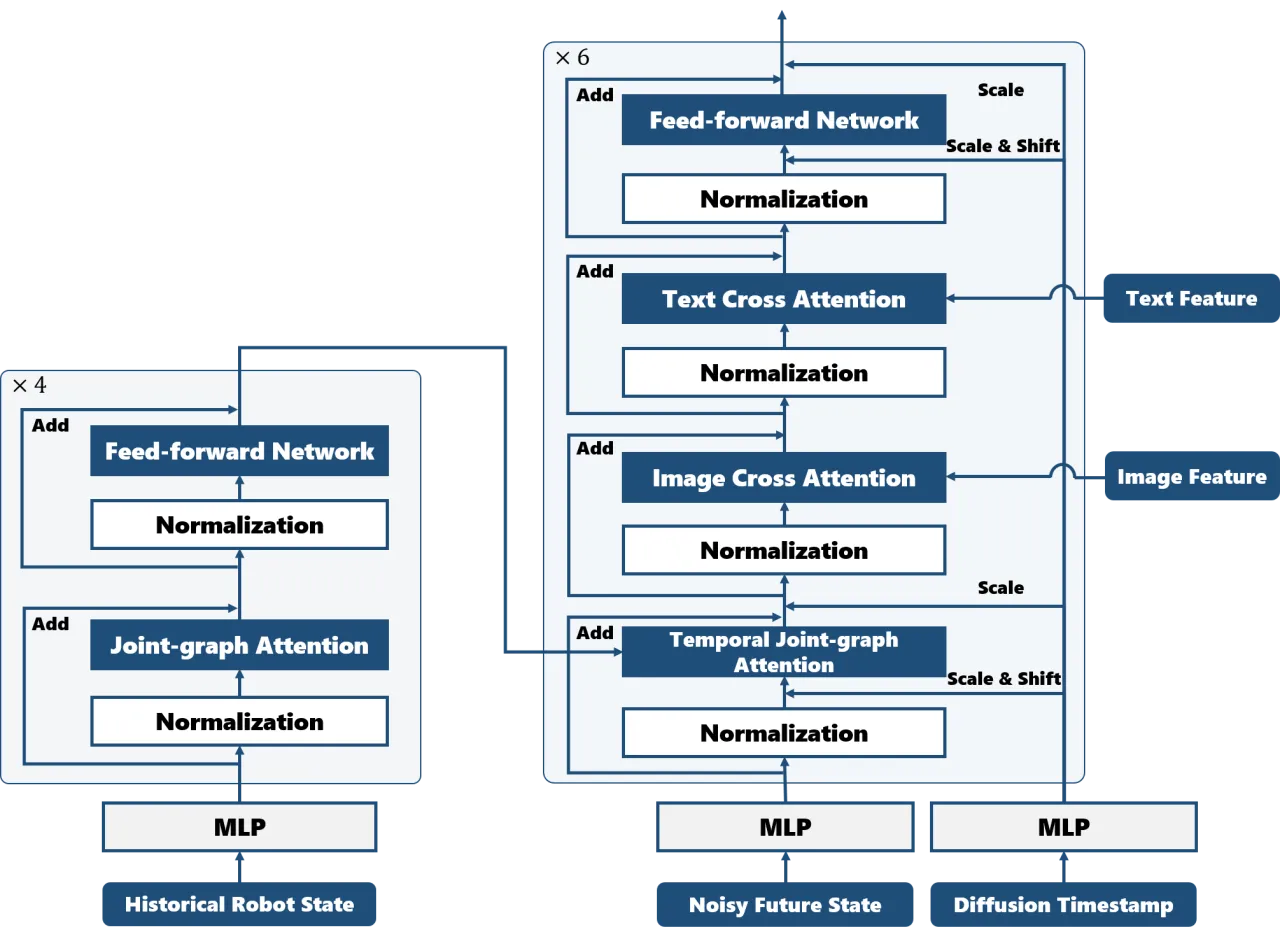
动作专家模块对机器人状态进行编码:对夹爪关节角做掩码(masked),仅保留 6D 姿态信息,以实现跨具身兼容。输出动作为:"a concatenation of joint angle residuals (in radians) and link pose displacements (in meters and quaternions)",即同时预测关节角增量和连杆末端位姿增量,格式为 [Δθ, Δx, Δy, Δz, Δqw, Δqx, Δqy, Δqz]。训练损失包含关节位置损失、末端姿态损失、正向运动学姿态损失和深度损失四项,均采用 smooth L1 距离以缓解极端误差带来的训练不稳定。
论文原文承认:"Although the sim-to-real gap persists, simulation benchmarks remain essential"(Section Experiments)。尽管 RoboTwin 2.0 等仿真基准上表现出色,真实世界部署中仍会出现新的分布外状态,需持续迭代数据采集加以弥补。
真实数据采集成本高(Data Collection Cost)
论文指出:"The efficacy of post-training is often bottlenecked by the high cost of collecting high-quality, real-world data"。测试驱动策略虽有效降低采集需求,但每轮仍需人工遥操作录制恢复轨迹(约 2–3 秒/次),规模化时成本仍然显著。
精确指令跟随能力尚待评估(Instruction Following)
论文原文指出:"We observe that precise instruction following is still an under-evaluated ability in current VLA research",并将开发更严格的语言指令跟随基准列为未来工作方向,当前模型在区分语义相近指令时仍有提升空间。
未集成离线强化学习(Off-Policy RL)
当前 HoloBrain-0 仅采用模仿学习(imitation learning),论文在 Future Work 中明确提到将集成 off-policy 强化学习与价值模型(value models),以进一步突破专家示范的性能上限。