01 Motivation
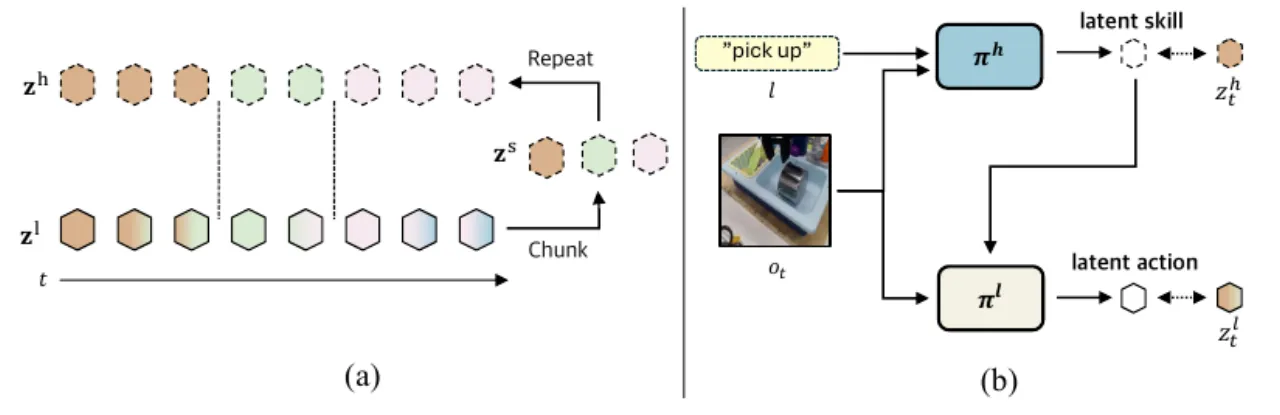
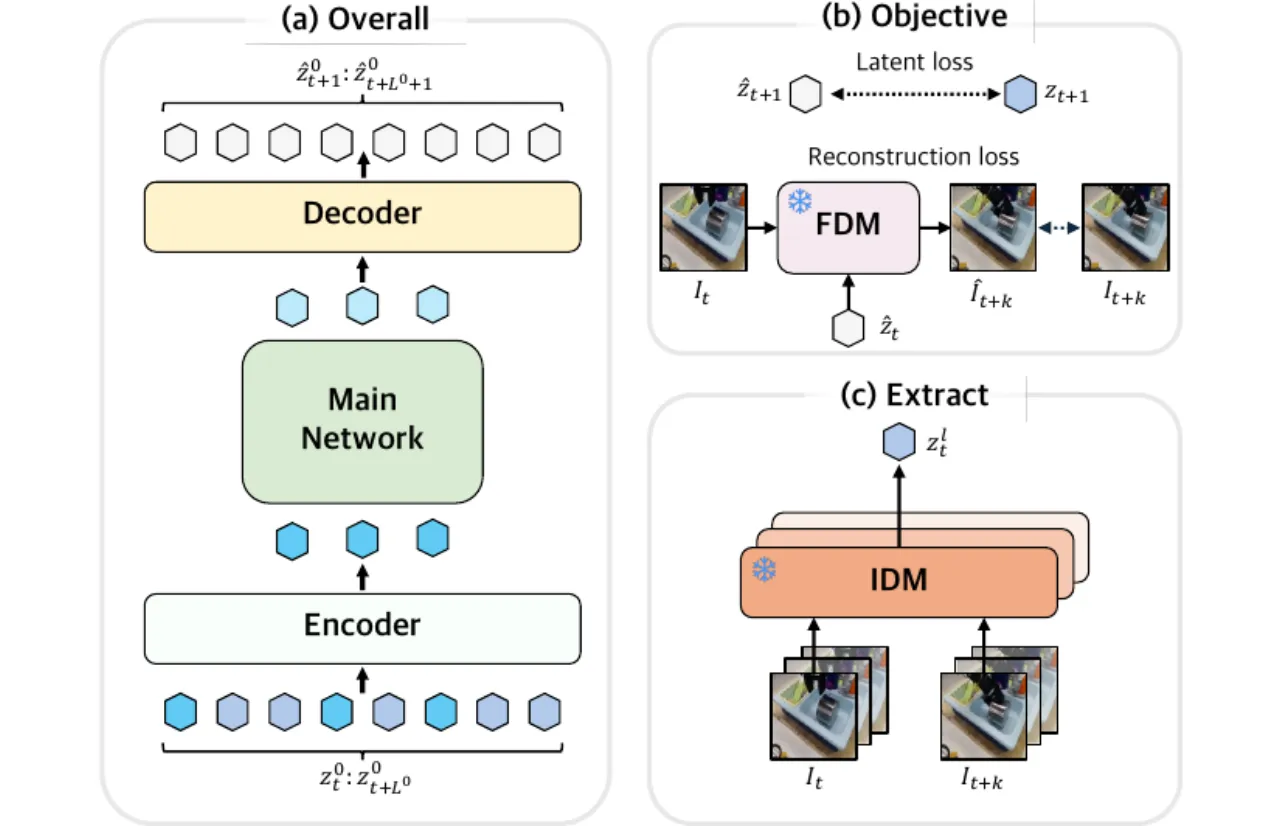
Latent Action Models (LAMs) 通过 Inverse Dynamics Model 从观测视频中推断帧间 latent action,无需人工标注动作标签。然而,现有方法几乎全部聚焦于短时域帧间运动,对视频中本已存在的高层技能结构视而不见。
"existing latent action models are largely limited to short-term motion. As a result, they can capture low-level dynamics from observation-only data but often miss higher-level structure, such as temporally extended skills. This exposes a key gap where actionless videos contain not only primitive motions but also high-level skills that remain underutilized."
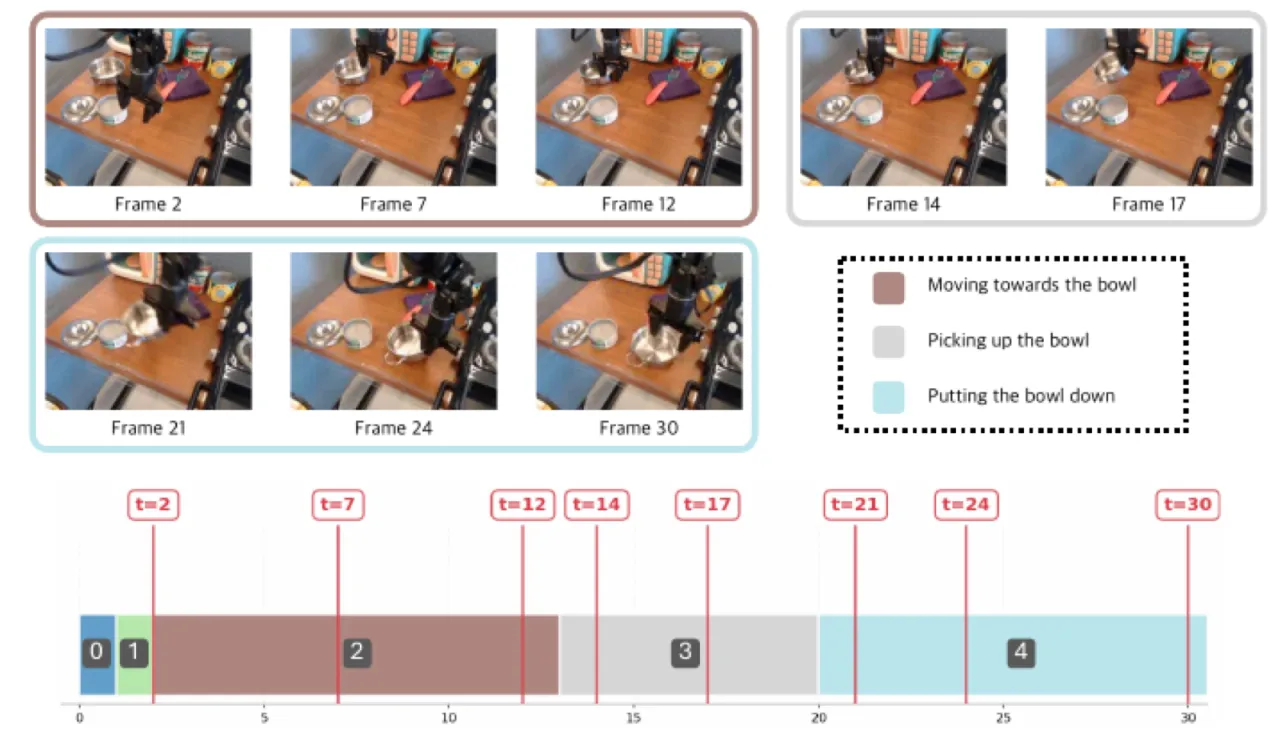
此前方法要么预设固定数量的 skill vectors(如 BUDS、SkillDiffuser),要么将固定长度的低层动作序列编码为 skill(如 SPiRL),均无法适应现实世界中技能时长自然变化的特性。HiLAM 的目标是:从无标签视频中自动提取可变长度、无需预先定义 skill set 的层次化 latent skills。
45%HiLAM 仅用 10% 数据在 LIBERO-Long 的成功率(BAKU 仅 23%)
84%HiLAM 用 50% 数据达到的成功率(≈ BAKU 100% 数据水平)
94%HiLAM 用 100% 数据在 LIBERO-Long 的成功率
4 suites全部 LIBERO 子测试均超越 BAKU baseline